
¿Qué es la regresión lineal?
La regresión lineal es un algoritmo de aprendizaje supervisado que se utiliza en Machine Learning y en estadística. En su versión más sencilla, lo que haremos es “dibujar una recta” que nos indicará la tendencia de un conjunto de datos continuos (si fueran discretos, utilizaríamos Regresión Logística).
En estadísticas, regresión lineal es una aproximación para modelar la relación entre una variable escalar dependiente “y” y una o mas variables explicativas nombradas con “X”.

Recordemos rápidamente la fórmula de la recta:
Y = mX + b
Donde Y es el resultado, X es la variable, m la pendiente (o coeficiente) de la recta y b la constante o también conocida como el “punto de corte con el eje Y” en la gráfica (cuando X=0)
¿Cómo funciona el algoritmo de regresión lineal en Machine Learning?
Recordemos que los algoritmos de Machine Learning Supervisados, aprenden por sí mismos y -en este caso- a obtener automáticamente esa “recta” que buscamos con la tendencia de predicción. Para hacerlo se mide el error con respecto a los puntos de entrada y el valor “Y” de salida real. El algoritmo deberá minimizar el coste de una función de error cuadrático y esos coeficientes corresponderán con la recta óptima. Hay diversos métodos para conseguir minimizar el coste. Lo más común es utilizar una versión vectorial y la llamada Ecuación Normal que nos dará un resultado directo.
NOTA: cuando hablo de “recta” es en el caso particular de regresión lineal simple. Si hubiera más variables, hay que generalizar el término.
Hagamos un Ejercicio Práctico
En este ejemplo cargaremos un archivo .csv de entrada obtenido por webscraping que contiene diversas URLs a artículos sobre Machine Learning de algunos sitios muy importantes como Techcrunch o KDnuggets y como características de entrada -las columnas- tendremos:
- Title: Titulo del Artículo
- url: ruta al artículo
- Word count: la cantidad de palabras del artículo,
- # of Links: los enlaces externos que contiene,
- # of comments: cantidad de comentarios,
- # Images video: suma de imágenes (o videos),
- Elapsed days: la cantidad de días transcurridos (al momento de crear el archivo)
- # Shares: nuestra columna de salida que será la “cantidad de veces que se compartió el artículo”.
A partir de las características de un artículo de machine learning intentaremos predecir, cuantas veces será compartido en Redes Sociales.
Haremos una primer predicción de regresión lineal simple -con una sola variable predictora- para poder graficar en 2 dimensiones (ejes X e Y) y luego un ejemplo de regresión Lineal Múltiple, en la que utilizaremos 3 dimensiones (X,Y,Z) y predicciones.
NOTA: el archivo .csv contiene mitad de datos reales, y otra mitad los generé de manera aleatoria, por lo que las predicciones que obtendremos no serán reales. Intentaré en el futuro hacer webscrapping de los enlaces que me faltaban y reemplazar los resultados por valores reales.
Requerimientos para hacer el Ejercicio
Para realizar este ejercicio, crearemos una Jupyter notebook con código Python y la librería SkLearn muy utilizada en Data Science. Recomendamos utilizar la suite de Anaconda. Puedes leer este artículo donde muestro paso a paso como instalar el ambiente de desarrollo. Podrás descargar los archivos de entrada csv o visualizar la notebook online (al final del artículo los enlaces).
Predecir cuántas veces será compartido un artículo de Machine Learning.
Regresión lineal simple en Python (con 1 variable)
Aqui vamos con nuestra notebook!
Comencemos por importar las librerías que utilizaremos:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# Imports necesarios import numpy as np import pandas as pd import seaborn as sb import matplotlib.pyplot as plt %matplotlib inline from mpl_toolkits.mplot3d import Axes3D from matplotlib import cm plt.rcParams['figure.figsize'] = (16, 9) plt.style.use('ggplot') from sklearn import linear_model from sklearn.metrics import mean_squared_error, r2_score |
Leemos el archivo csv y lo cargamos como un dataset de Pandas. Y vemos su tamaño
|
1 2 3 4 |
#cargamos los datos de entrada data = pd.read_csv("./articulos_ml.csv") #veamos cuantas dimensiones y registros contiene data.shape |
Nos devuelve (161,8)
Veamos esas primeras filas:
|
1 2 |
#son 161 registros con 8 columnas. Veamos los primeros registros data.head() |
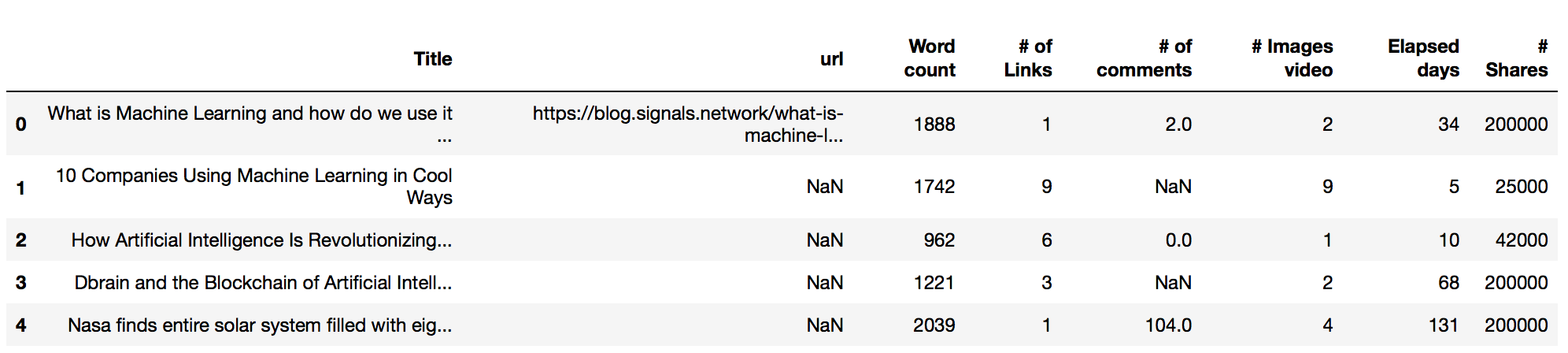
Se ven algunos campos con valores NaN (nulos) por ejemplo algunas urls o en comentarios.
Veamos algunas estadísticas básicas de nuestros datos de entrada:
|
1 2 |
# Ahora veamos algunas estadísticas de nuestros datos data.describe() |
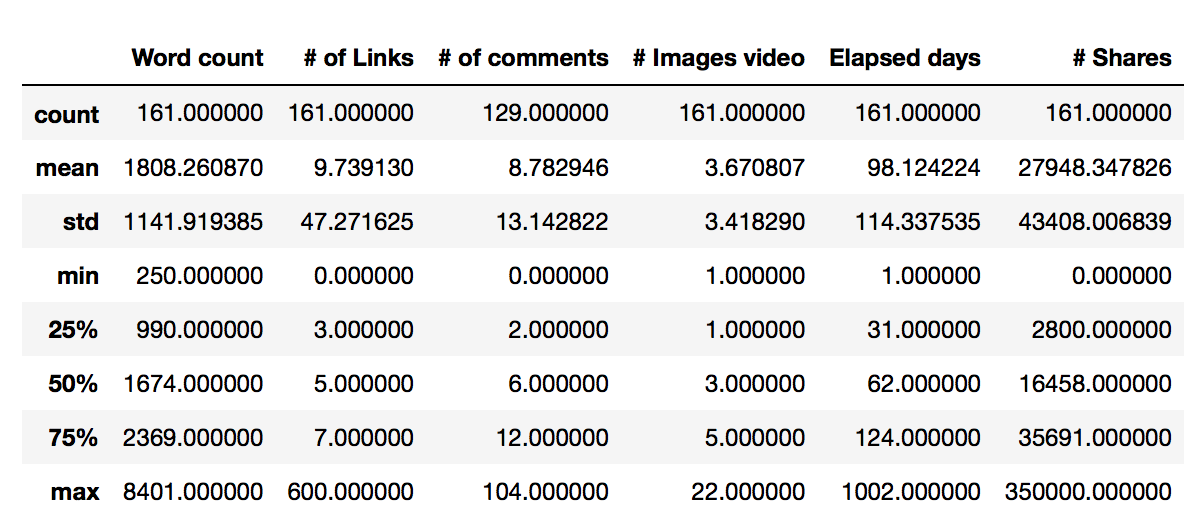
Aqui vemos que la media de palabras en los artículos es de 1808. El artículo más corto tiene 250 palabras y el más extenso 8401. Intentaremos ver con nuestra relación lineal, si hay una correlación entre la cantidad de palabras del texto y la cantidad de Shares obtenidos.
Hacemos una visualización en general de los datos de entrada:
|
1 2 3 |
# Visualizamos rápidamente las caraterísticas de entrada data.drop(['Title','url', 'Elapsed days'],1).hist() plt.show() |
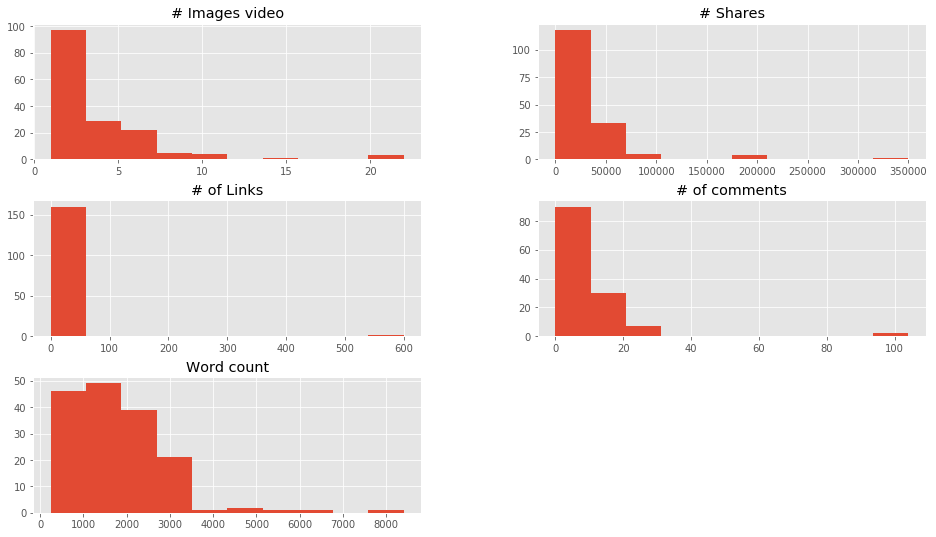
En estas gráficas vemos entre qué valores se concentran la mayoría de registros.
Vamos a filtrar los datos de cantidad de palabras para quedarnos con los registros con menos de 3500 palabras y también con los que tengan Cantidad de compartidos menos a 80.000. Lo gratificaremos pintando en azul los puntos con menos de 1808 palabras (la media) y en naranja los que tengan más.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# Vamos a RECORTAR los datos en la zona donde se concentran más los puntos # esto es en el eje X: entre 0 y 3.500 # y en el eje Y: entre 0 y 80.000 filtered_data = data[(data['Word count'] <= 3500) & (data['# Shares'] <= 80000)] colores=['orange','blue'] tamanios=[30,60] f1 = filtered_data['Word count'].values f2 = filtered_data['# Shares'].values # Vamos a pintar en colores los puntos por debajo y por encima de la media de Cantidad de Palabras asignar=[] for index, row in filtered_data.iterrows(): if(row['Word count']>1808): asignar.append(colores[0]) else: asignar.append(colores[1]) plt.scatter(f1, f2, c=asignar, s=tamanios[0]) plt.show() |
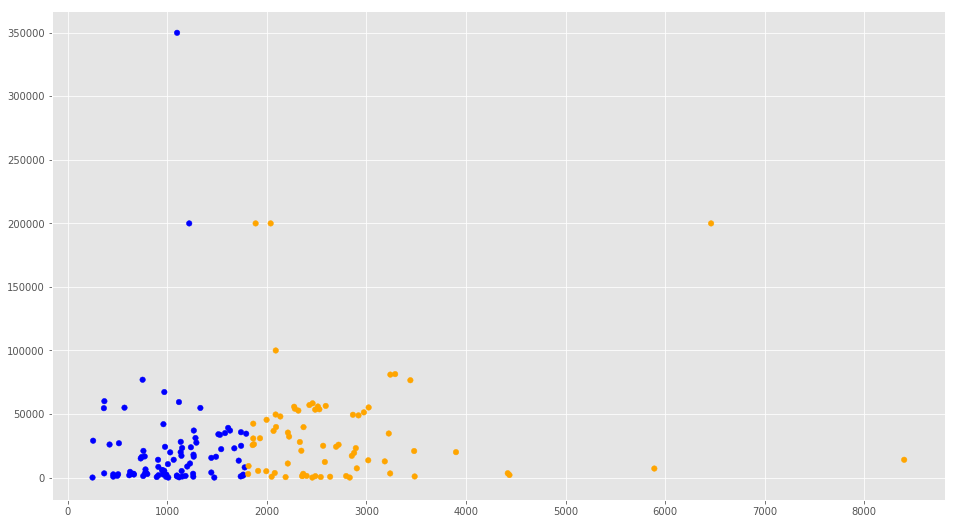
Regresión Lineal con Python y SKLearn
Vamos a crear nuestros datos de entrada por el momento sólo Word Count y como etiquetas los # Shares. Creamos el objeto LinearRegression y lo hacemos “encajar” (entrenar) con el método fit(). Finalmente imprimimos los coeficientes y puntajes obtenidos.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# Asignamos nuestra variable de entrada X para entrenamiento y las etiquetas Y. dataX =filtered_data[["Word count"]] X_train = np.array(dataX) y_train = filtered_data['# Shares'].values # Creamos el objeto de Regresión Linear regr = linear_model.LinearRegression() # Entrenamos nuestro modelo regr.fit(X_train, y_train) # Hacemos las predicciones que en definitiva una línea (en este caso, al ser 2D) y_pred = regr.predict(X_train) # Veamos los coeficienetes obtenidos, En nuestro caso, serán la Tangente print('Coefficients: \n', regr.coef_) # Este es el valor donde corta el eje Y (en X=0) print('Independent term: \n', regr.intercept_) # Error Cuadrado Medio print("Mean squared error: %.2f" % mean_squared_error(y_train, y_pred)) # Puntaje de Varianza. El mejor puntaje es un 1.0 print('Variance score: %.2f' % r2_score(y_train, y_pred)) |
<
p style=”padding-left: 30px;”>Coefficients: [5.69765366]
Independent term: 11200.303223074163
Mean squared error: 372888728.34
Variance score: 0.06
De la ecuación de la recta y = mX + b nuestra pendiente “m” es el coeficiente 5,69 y el término independiente “b” es 11200. Tenemos un Error Cuadrático medio enorme… por lo que en realidad este modelo no será muy bueno 😉 Pero estamos aprendiendo a usarlo, que es lo que nos importa ahora 🙂 Esto también se ve reflejado en el puntaje de Varianza que debería ser cercano a 1.0.
Visualicemos la Recta
Veamos la recta que obtuvimos:
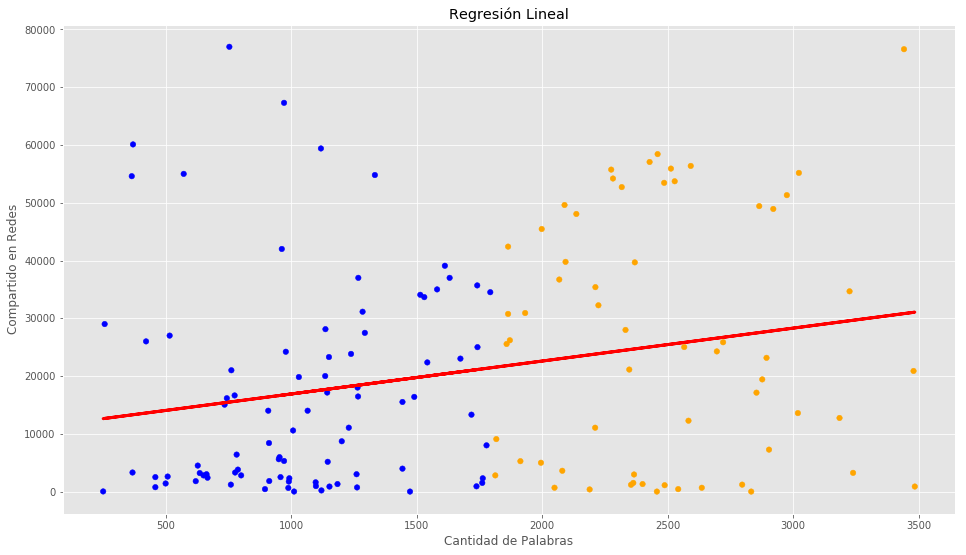
Predicción en regresión lineal simple
Vamos a intentar probar nuestro algoritmo, suponiendo que quisiéramos predecir cuántos “compartir” obtendrá un articulo sobre ML de 2000 palabras
|
1 2 3 4 5 |
#Vamos a comprobar: # Quiero predecir cuántos "Shares" voy a obtener por un artículo con 2.000 palabras, # según nuestro modelo, hacemos: y_Dosmil = regr.predict([[2000]]) print(int(y_Dosmil)) |
Nos devuelve una predicción de 22595 “Shares” para un artículo de 2000 palabras (ya quisiera yo!!!).
Regresión Lineal Múltiple en Python
(o “Regresión con Múltiples Variables”)
Vamos a extender el ejercicio utilizando más de una variable de entrada para el modelo. Esto le da mayor poder al algoritmo de Machine Learning, pues de esta manera podremos obtener predicciones más complejas.
Nuestra “ecuación de la Recta”, ahora pasa a ser:
Y = b + m1 X1 + m2 X2 + … + m(n) X(n)
y deja de ser una recta)
En nuestro caso, utilizaremos 2 “variables predictivas” para poder graficar en 3D, pero recordar que para mejores predicciones podemos utilizar más de 2 entradas y prescindir del grafico.
Nuestra primer variable seguirá siendo la cantidad de palabras y la segunda variable será la suma de 3 columnas de entrada: la cantidad de enlaces, comentarios y cantidad de imágenes. Vamos a programar!
|
1 2 3 4 5 6 7 8 9 |
#Vamos a intentar mejorar el Modelo, con una dimensión más: # Para poder graficar en 3D, haremos una variable nueva que será la suma de los enlaces, comentarios e imágenes suma = (filtered_data["# of Links"] + filtered_data['# of comments'].fillna(0) + filtered_data['# Images video']) dataX2 = pd.DataFrame() dataX2["Word count"] = filtered_data["Word count"] dataX2["suma"] = suma XY_train = np.array(dataX2) z_train = filtered_data['# Shares'].values |
Nota: hubiera sido mejor aplicar PCA para reducción de dimensiones, manteniendo la información más importante de todas
Ya tenemos nuestras 2 variables de entrada en XY_train y nuestra variable de salida pasa de ser “Y” a ser el eje “Z”.
Creamos un nuevo objeto de Regresión lineal con SKLearn pero esta vez tendrá las dos dimensiones que entrenar: las que contiene XY_train. Al igual que antes, imprimimos los coeficientes y puntajes obtenidos:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# Creamos un nuevo objeto de Regresión Lineal regr2 = linear_model.LinearRegression() # Entrenamos el modelo, esta vez, con 2 dimensiones # obtendremos 2 coeficientes, para graficar un plano regr2.fit(XY_train, z_train) # Hacemos la predicción con la que tendremos puntos sobre el plano hallado z_pred = regr2.predict(XY_train) # Los coeficientes print('Coefficients: \n', regr2.coef_) # Error cuadrático medio print("Mean squared error: %.2f" % mean_squared_error(z_train, z_pred)) # Evaluamos el puntaje de varianza (siendo 1.0 el mejor posible) print('Variance score: %.2f' % r2_score(z_train, z_pred)) |
<
p style=”padding-left: 30px;”>Coefficients: [ 6.63216324 -483.40753769]
Mean squared error: 352122816.48
Variance score: 0.11
Como vemos, obtenemos 2 coeficientes (cada uno correspondiente a nuestras 2 variables predictivas), pues ahora lo que graficamos no será una linea si no, un plano en 3 Dimensiones.
El error obtenido sigue siendo grande, aunque algo mejor que el anterior y el puntaje de Varianza mejora casi el doble del anterior (aunque sigue siendo muy malo, muy lejos del 1).
Visualizar un plano en 3 Dimensiones en Python
Graficaremos nuestros puntos de las características de entrada en color azul y los puntos proyectados en el plano en rojo. Recordemos que en esta gráfica, el eje Z corresponde a la “altura” y representa la cantidad de Shares que obtendremos.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
fig = plt.figure() ax = Axes3D(fig) # Creamos una malla, sobre la cual graficaremos el plano xx, yy = np.meshgrid(np.linspace(0, 3500, num=10), np.linspace(0, 60, num=10)) # calculamos los valores del plano para los puntos x e y nuevoX = (regr2.coef_[0] * xx) nuevoY = (regr2.coef_[1] * yy) # calculamos los correspondientes valores para z. Debemos sumar el punto de intercepción z = (nuevoX + nuevoY + regr2.intercept_) # Graficamos el plano ax.plot_surface(xx, yy, z, alpha=0.2, cmap='hot') # Graficamos en azul los puntos en 3D ax.scatter(XY_train[:, 0], XY_train[:, 1], z_train, c='blue',s=30) # Graficamos en rojo, los puntos que ax.scatter(XY_train[:, 0], XY_train[:, 1], z_pred, c='red',s=40) # con esto situamos la "camara" con la que visualizamos ax.view_init(elev=30., azim=65) ax.set_xlabel('Cantidad de Palabras') ax.set_ylabel('Cantidad de Enlaces,Comentarios e Imagenes') ax.set_zlabel('Compartido en Redes') ax.set_title('Regresión Lineal con Múltiples Variables') |
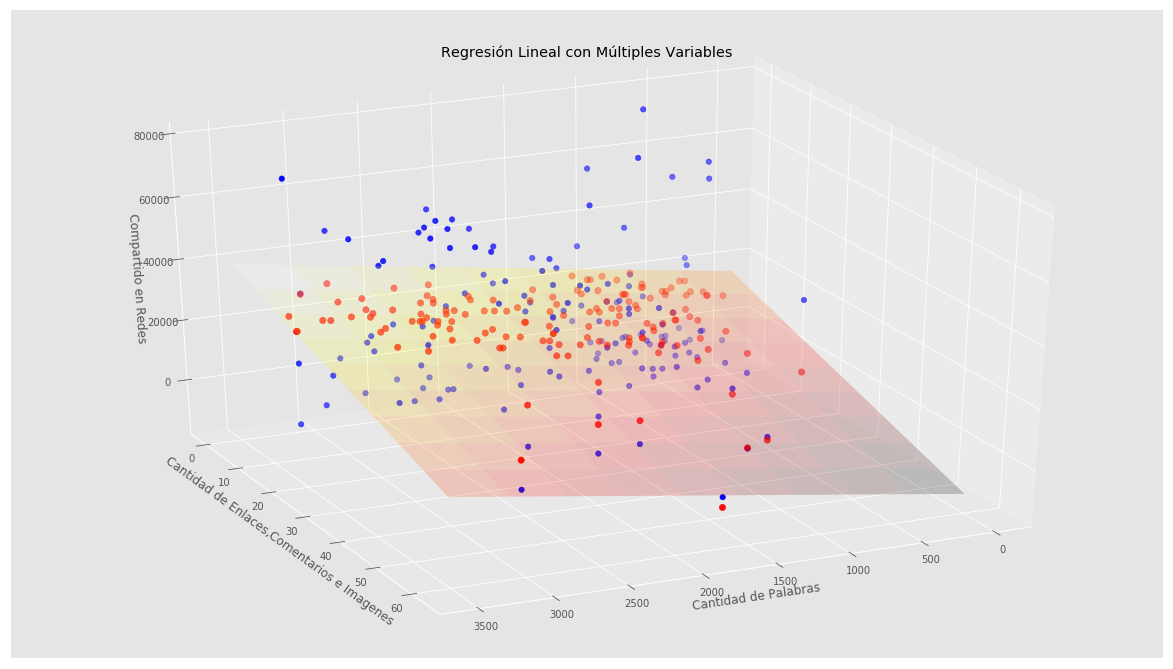
Podemos rotar el gráfico para apreciar el plano desde diversos ángulos modificando el valor del parámetro azim en view_init con números de 0 a 360.
Predicción con el modelo de Mútiples Variables
Veamos ahora, que predicción tendremos para un artículo de 2000 palabras, con 10 enlaces, 4 comentarios y 6 imágenes.
|
1 2 3 4 5 6 |
# Si quiero predecir cuántos "Shares" voy a obtener por un artículo con: # 2000 palabras y con enlaces: 10, comentarios: 4, imagenes: 6 # según nuestro modelo, hacemos: z_Dosmil = regr2.predict([[2000, 10+4+6]]) print(int(z_Dosmil)) |
Esta predicción nos da 20518 y probablemente sea un poco mejor que nuestra predicción anterior con 1 variables.
Conclusion y Mejora de nuestro modelo
Hemos visto cómo utilizar SKLearn en Python para crear modelos de Regresión Lineal con 1 o múltiples variables. En nuestro ejercicio no tuvimos una gran confianza en las predicciónes. Por ejemplo en nuestro primer modelo, con 2000 palabras nos predice que podemos tener 22595 pero el margen de error haciendo raíz del error cuartico medio es más menos 19310. Es decir que escribiendo un artículo de 2000 palabras lo mismo tenemos 3285 Shares que 41905. En este caso usamos este modelo para aprender a usarlo y habrá que ver en otros casos en los que sí nos brinde predicciones acertadas.
Para mejorar nuestro modelo, deberíamos utilizar más dimensiones y encontrar datos de entrada mejores. Atención: también es posible, que no exista ninguna relación nunca entre nuestras variables de entrada y el éxito en Shares del artículo… con lo cual… nunca podremos predecir con certeza esta salida. Esto fue un experimento! Espero que les haya gustado!.
Suscribirme al Blog
Recibir el próximo artículo quincenal sobre Machine Learning y prácticas en Python
Puedes hacer otros ejercicios Machine Learning en Python en nuestra categoría d Ejercicios paso a paso por ejemplo de Regresión Logística o de Aprendizaje no supervisado como clustering K-means o comprender y crear una Sencilla Red Neuronal.
Recursos y enlaces del ejercicio
- Descarga la Jupyter Notebook y el archivo de entrada csv
- ó puedes visualizar online
- o ver y descargar desde mi cuenta github
Otros enlaces con Artículos sobre Regresión Lineal (en Inglés)
- Introduction to Linear Regression using python
- Linear Regression using Python SkLearn
- Linear Regression Detailed View
- How do you solve a linear regression problem in python
- Python tutorial on LinearRegression with Batch Gradient Descent
El libro del Blog
Si te gustan los contenidos del blog y quieres darme una mano, puedes comprar el libro en papel, ó en digital.
Gemial Juan! Me gustaría la explicación de un ejemplo que minimice el error practicamente al máximo y que la varianza se acerque a 1. Muchas gracias por compartir tus conocimientos!!! Un abrazo crack!
Hola David, gracias por escribirme!. Te cuento que estuve buscando artículos en para mostrarte el uso de la función de r2_score y me costó bastante encontrar uno bueno. Este es muy completo y de hecho logran un puntaje cercano a 1. Espero que te sirva (está en inglés). El enlace es: Regression Apache Spark Saludos!
Hola Juan Ignacio, primero que todo te felicito por la calidad de explicación en cada uno de tus posteos, como dicen por ahí uno nunca termina de aprender, y fiel prueba de ello es que aqui he ido aprendiendo mucho mas, sabes tengo una duda, he realizado regresiones con algoritmo de árbol de decisión, funciona y predice relativamente bien, el problema es que no tengo idea como puedo mostrar en pantalla o bien guardar mi csv todas las columnas originales de mi dataset más la columna y_predict, me puedes orientar con algo?.
Saludos y felicidades por el tremendo blog
Hola Raul, gracias por escribirme, me alegro que te sirvieran los posts!. Te cuento que para guardar el csv, te recomiendo si usas Pandas pues facilita mucho las tareas. Te dejo un enlace con buenos tips de Pandas: 19 Snippets in Pandas.
Para guardar a csv es tan simple como hacer miTabla.to_csv(‘nombre_archivo.csv’)
Saludos y cualquier cosa me dices!
Hola Juan! Muy buenos los posts que has realizado, le he dado una buena mirada varios y sigo leyendo. Son muy nuevos, bien explicados y (para mi caso sobretodo) en español. Hace poco decidí incursionarme un poco en ML. Aún no he logrado mucho, pero vamos en camino. Te quería consultar algunos consejos. Actualmente tengo dos requerimientos, 1- analizar y predecir el espacio de disco (o un punto de montaje) teniendo el histórico. 2- clasificar la carga (el load) de un sistema en tiempo real sabiendo la historia de carga.
Respecto al punto dos me veo imposibilitado de darme cuenta como usar el campo fecha (actualmente lo tengo yyyy-MM-dd hh:mm:ss). Para el punto 1, podría pasarlo a timestamp, pero para el punto 2 que a mi me interesa que el sistema aprenda que los Lunes, tiene un comportamiento diferente a los martes, que a las 14 PM la carga es mayor que a las 3 AM, que los primeros días del mes la carga va a ser mayor, etc etc. no estoy logrando encontrar el uso que debería a ese campo.
Respecto al punto 1, estaría correcto utilizar regresión lineal?. Me interesa poder darle una fecha y que me estime(prediga) el espacio que va tener ocupado o, dado un valor de espacio ocupado, que estime en que fecha se llegaría a tener ese valor de espacio ocupado.
Muchas gracias por el tiempo que has dedicado a compartir tus conocimientos.
Slds desde Uruguay.
Hola Emiliano!, saludos a Uruguay! gracias por leerme y escribir comentarios en mi blog. Me alegro que te gustaran los artículos 🙂
Mira, voy a escribirte a tu email (si me autorizas) para que podamos comentar los los requerimientos que tienes y veamos si te puedo ayudar y de hecho, me gustan los dos casos para realizar un artículo y compartirlo con la comunidad de AprendeMachineLearning.
Saludos de un Argentino en España, te escribo pronto.
Juan, excelente, estaré a la espera de tu correo.
Te comento que estuve avanzando un poco y haciendo pruebas de predicción usan LSTM (utilizando un modelo ya creado) y tomando datos desde una base de influx (aún me falta muchísimo mejorar el manejo de los datos con pandas) y el resultado fue muy bueno para ser la primera prueba.
Igual aún tengo que mejorar muchos conceptos, madurar el uso de pandas y de tensorflow. También hay varios conceptos que uno debe tener claros que son matemáticos que estoy tratando de poner al día.
Gracias por todo,
Slds.-
Hola Nacho. Muy buen post, aunque se te olvidó el código de cómo hacer la visualización de la recta con una sola variable 😉
Espero no estar equivocado…
plt.scatter(X_train, y_train)
plt.plot(X_train, y_pred, color=’blue’, linewidth=3)
plt.show()
Hola. Muchas gracias por el ejecrcio. Soy nuevo en Phyton y ha sido muy util para mi. Donde puedo encontrar información de cada metodo de PANDAS. Por ejemplo la linea data.drop([‘Title’,’url’, ‘Elapsed days’],1).hist() no me queda claro que hace el drop (supongo que elimina, pero ¿que?)
Gracias
Hola Jaime, te dejo enlace a algunas webs con ejemplos para comprender mejor Pandas:
Saludos! Si tienes más dudas, me escribes!
Jaime, elimina esas columnas, 1 indica columna, 0 fila.
.hist() es para armar los histogramas.
Hola Juan, primeramente te felicito por la calidad de tus posteos, soy bastante nuevo en esto del Machine Learning y realmente aprecio el hecho de que compartas tus conocimientos con los simples mortales. Como sabrás uno de los ejemplos más difundidos para comprender el algoritmo de regresión lineal y múltiple es la predicción del precio de una casa o inmueble. Mi consulta es si tendrías un ejemplo para realizar la misma predicción pero aplicando el algoritmo de redes neuronales. Deseo realizar una comparación entre la efectividad de las predicciones utilizando redes neuronales y las técnicas de regresión. Hasta ahora los ejemplos que encontré sobre redes neuronales sólo predicen valores binarios.
Desde ya muchas gracias.
Hola Luis, me parece buena idea! Su te parece bien, intento hacer un ejemplo y te contesto vos email
Me parece excelente!! Estaré eternamente agradecido con usted. Yo estoy practicando con el paquete Spyder del IDE Anaconda.
Luis, te paso este enlace que hace exactamente lo que necesitas!:
Price Prediction with Neural Networks.
Estoy algo escaso de tiempo, pero si puedo igualmente haré la red y te escribo!.
Saludos
Muchas gracias, un excelente aporte, me es mas claro el procedimiento para aplicar a mis datos.
Hola Geovany Andrade, me alegro que te ayude el artículo! Espero que sigas visitando el blog! Saludos
excelente, me sirvió mucho para aprender
Excelente post, a decir verdad soy bastante nueva en esto y creo que es la mejor explicación que he encontrado, replique el ejercicio con mis datos y mi varianza es de 0.81 , como se puede mejorar el modelo para lograr llegar a un pronostico más acertado nuevamente gracias por tu explicación.
Hola Lesly, gracias por escribir. Para mejorar el modelo, de primeras se me ocurre: obtener más muestras, con eso seguro podremos mejorar la generalización de conocimiento. Otra opción puede ser detectar si hay “biases” y/o descartar puntos que sean muy “anormales” y que empeoren la predicción.
Saludos!
Hola nuevamente! Muchas gracias por responderme, me dedique a hacer más grande el data como me sugeriste así como descartar los puntos anormales, pero redujo mi varianza, tengo característica en mi data pero es cualitativa ¿Es posible agregarla? También había escuchado que se puede incorporar el error para mejorar el modelo ¿Es correcto eso? De antemano agradezco tu atención.
Saludos!
Buenos dias.
Estoy tratando de realizar este ejercicio, pero me da un error y me gustaría que me ayuden a corregirlo.
El error es en la siguiente parte del código:
Asignamos nuestra variable de entrada X para entrenamiento y las etiquetas Y.
dataX =filtered_data[[“Word count”]]
X_train = np.array(dataX)
y_train = filtered_data[‘# Shares’].values
Creamos el objeto de Regresión Linear
regr = linear_model.LinearRegression()
Entrenamos nuestro modelo
regr.fit(X_train, y_train)
Hacemos las predicciones que en definitiva una línea (en este caso, al ser 2D)
y_pred = regr.predict(X_train)
Veamos los coeficienetes obtenidos, En nuestro caso, serán la Tangente
print(‘Coefficients: \n’, regr.coef_)
Este es el valor donde corta el eje Y (en X=0)
print(‘Independent term: \n’, regr.intercept_)
Error Cuadrado Medio
print(“Mean squared error: %.2f” % mean_squared_error(y_train, y_pred))
Puntaje de Varianza. El mejor puntaje es un 1.0
print(‘Variance score: %.2f’ % r2_score(y_train, y_pred))
Y este es el error que me retorna:
NameError Traceback (most recent call last)
in
1 # Asignamos nuestra variable de entrada X para entrenamiento y las etiquetas Y.
—-> 2 dataX =filtered_data[[“Word count”]]
3 X_train = np.array(dataX)
4 y_train = filtered_data[‘# Shares’].values
5
NameError: name ‘filtered_data’ is not defined
Buenas tardes, de antemano gracias por el artículo, realmente interesante.
Tengo una duda cuando intento graficar y corre la línea:
nuevoX = (regr_rm.coef_[0] * xx)
nuevoY = (regr_rm.coef_[1] * yy)
y sencillamente se me cierra.
qué podrá ser?
muchas gracias!
Excelente este post Juan! A ver si tienes tiempo y dedicas un nuevo post a hablar de las regularizaciones Ridge y Lasso. Gracias!!
Muy bueno Juan.
Gracias por todo!
Muchas gracias! Saludos
Hola, excelente explicacion, pero me queda la duda. Por que no lo dividiste en entrenamiento y prueba?
Hola Orlando, las buenas prácticas indican que debemos separar en train y test, pero este fue uno de los primeros artículos que escribí en el blog y dado que el dataset era reducido, me centré en explicar el algoritmo y no tanto en el pipeline de ML.
Un saludo y gracias por escribir.
Muy buena explicación Juan! Gracias por compartir tus conocimientos! Saludos.
Gracias Juan! He replicado tus ejercicios y luego de superar algunos errores todo va muy bien. Excelentes posts, gracias por compartir tus conocimientos! Seguro eres un buen profesor, sino lo eres, deberías dedicarte a la docencia 🙂
me gusto resto ,lo que mas me gusto es que vas paso por paso super bien explicado