
En este artículo describiremos rápidamente en qué consisten y cómo funcionan los árboles de decisión utilizados en Aprendizaje Automático y nos centraremos en un divertido ejemplo en Python en el que analizaremos a los cantantes y bandas que lograron un puesto número uno en las listas de Billboard Hot 100 e intentaremos predecir quién será el próximo Ed Sheeran a fuerza de Inteligencia Artificial. Realizaremos Gráficas que nos ayudarán a visualizar los datos de entrada y un grafo para interpretar el árbol que crearemos con el paquete Scikit-Learn. Comencemos!

¿Qué es un árbol de decisión?
Los arboles de decisión son representaciones gráficas de posibles soluciones a una decisión basadas en ciertas condiciones, es uno de los algoritmos de aprendizaje supervisado más utilizados en machine learning y pueden realizar tareas de clasificación o regresión (acrónimo del inglés CART). La comprensión de su funcionamiento suele ser simple y a la vez muy potente.
Utilizamos mentalmente estructuras de árbol de decisión constantemente en nuestra vida diaria sin darnos cuenta:
¿Llueve? => lleva paraguas. ¿Soleado? => lleva gafas de sol. ¿estoy cansado? => toma café. (decisiones del tipo IF THIS THEN THAT)
Los árboles de decisión tienen un primer nodo llamado raíz (root) y luego se descomponen el resto de atributos de entrada en dos ramas (podrían ser más, pero no nos meteremos en eso ahora) planteando una condición que puede ser cierta o falsa. Se bifurca cada nodo en 2 y vuelven a subdividirse hasta llegar a las hojas que son los nodos finales y que equivalen a respuestas a la solución: Si/No, Comprar/Vender, o lo que sea que estemos clasificando.
Otro ejemplo son los populares juegos de adivinanza:
- ¿Animal ó vegetal? -Animal
- ¿Tiene cuatro patas? -Si
- ¿Hace guau? -Si
- -> Es un perro!
¿Qué necesidad hay de usar el Algoritmo de Arbol?
Supongamos que tenemos atributos como Género con valores “hombre ó mujer” y edad en rangos: “menor de 18 ó mayor de 18” para tomar una decisión. Podríamos crear un árbol en el que dividamos primero por género y luego subdividir por edad. Ó podría ser al revés: primero por edad y luego por género. El algoritmo es quien analizando los datos y las salidas -por eso es supervisado!– decidirá la mejor forma de hacer las divisiones (split) entre nodos. Tendrá en cuenta de qué manera lograr una predicción (clasificación ó regresión) con mayor probabilidad de acierto. Parece sencillo, no? Pensemos que si tenemos 10 atributos de entrada cada uno con 2 o más valores posibles, las combinaciones para decidir el mejor árbol serían cientos ó miles… Esto ya no es un trabajo para hacer artesanalmente. Y ahí es donde este algoritmo cobra importancia, pues él nos devolverá el árbol óptimo para la toma de decisión más acertada desde un punto de vista probabilístico.
¿Cómo funciona un árbol de decisión?
Para obtener el árbol óptimo y valorar cada subdivisión entre todos los árboles posibles y conseguir el nodo raiz y los subsiguientes, el algoritmo deberá medir de alguna manera las predicciones logradas y valorarlas para comparar de entre todas y obtener la mejor. Para medir y valorar, utiliza diversas funciones, siendo las más conocidas y usadas los “Indice gini” y “Ganancia de información” que utiliza la denominada “entropía“. La división de nodos continuará hasta que lleguemos a la profundidad máxima posible del árbol ó se limiten los nodos a una cantidad mínima de muestras en cada hoja. A continuación describiremos muy brevemente cada una de las estrategias nombradas:
Indice Gini:
Se utiliza para atributos con valores continuos (precio de una casa). Esta función de coste mide el “grado de impureza” de los nodos, es decir, cuán desordenados o mezclados quedan los nodos una vez divididos. Deberemos minimizar ese GINI index.
Ganancia de información:
Se utiliza para atributos categóricos (cómo en hombre/mujer). Este criterio intenta estimar la información que aporta cada atributo basado en la “teoría de la información“. Para medir la aleatoriedad de incertidumbre de un valor aleatorio de una variable “X” se define la Entropia.
Al obtener la medida de entropía de cada atributo, podemos calcular la ganancia de información del árbol. Deberemos maximizar esa ganancia.
Ejemplo de Arbol de Decisión con Python SKLearn paso a paso
Para este ejercicio me propuse crear un set de datos original e intentar que sea divertido a la vez que explique de forma clara el funcionamiento del árbol. Comencemos:
Requerimientos para hacer el Ejercicio
Para realizar este ejercicio, utilizaremos una Jupyter notebook con código python y la librería Scikit learn muy utilizada en Data Science. Recomendamos utilizar la suite de Anaconda. Si aún no la tienes, puedes leer este artículo donde muestra paso a paso como instalar el ambiente de desarrollo. Además podrás descargar los archivos de entrada csv o visualizar la notebook online (al final del artículo los enlaces).
Predicción del “Billboard 100”: ¿Qué artista llegará al número uno del ranking?
A partir de atributos de cantantes y de un histórico de canciones que alcanzaron entrar al Billboard 100 (U.S.) en 2013 y 2014 crearemos un árbol que nos permita intentar predecir si un nuevo cantante podrá llegar a número uno.
Obtención de los datos de entrada
Utilicé un código python para hacer webscraping de una web pública “Ultimate Music Database” con información histórica del Billboard que obtuve de este artículo: “Analyzing billboard 100″. Luego completé atributos utilizando la API de Deezer (duración de las canciones), la API de Gracenote (género y ritmo de las canciones). Finalmente agregué a mano varias fechas de nacimiento de artistas utilizando la Wikipedia que no había conseguido con la Ultimate Music Database. Algunos artistas quedaron sin completar su fecha de nacimiento y con valor 0. Veremos como superar este obstáculo tratando los datos.
Para empezar importemos las librerías que utilizaremos y revisemos sus atributos de entrada:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# Imports needed for the script import numpy as np import pandas as pd import seaborn as sb import matplotlib.pyplot as plt %matplotlib inline plt.rcParams['figure.figsize'] = (16, 9) plt.style.use('ggplot') from sklearn import tree from sklearn.metrics import accuracy_score from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from IPython.display import Image as PImage from subprocess import check_call from PIL import Image, ImageDraw, ImageFont |
Si te falta alguna de ellas, recuerda que puedes instalarla con el entorno Anaconda o con la herramienta Pip.
Análisis Exploratorio Inicial
Ahora veamos cuantas columnas y registros tenemos:
|
1 |
artists_billboard.shape |
Esto nos devuelve (635,11) es decir que tenemos 11 columnas (features) y 635 filas de datos. Vamos a echar un ojo a los primeros registros para tener una mejor idea del contenido:
|
1 |
artists_billboard.head() |
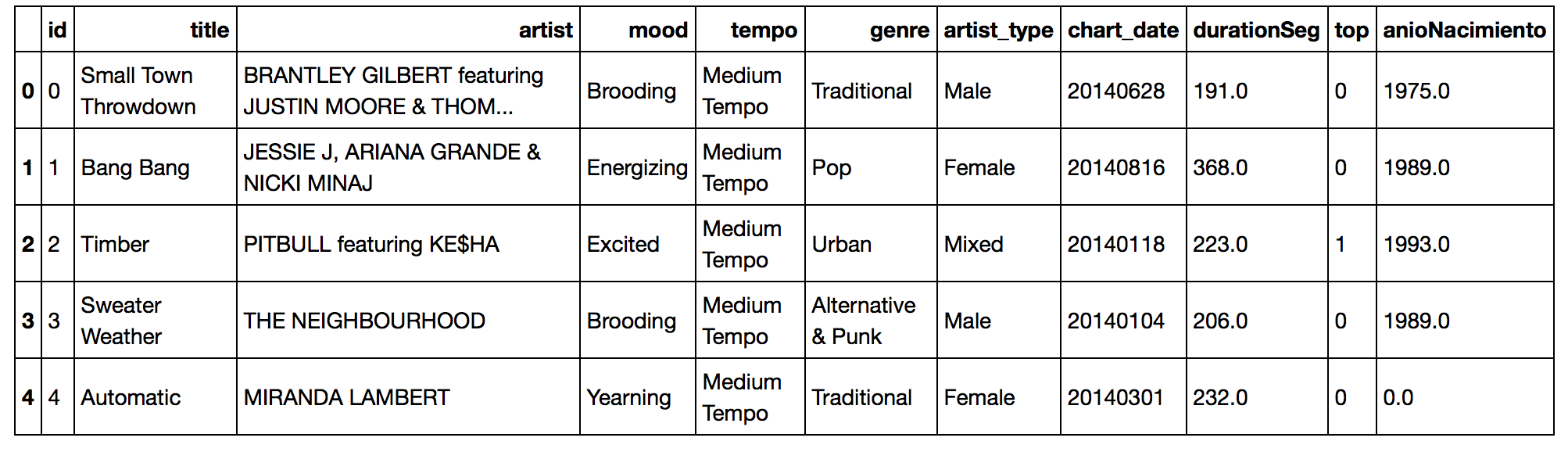
Vemos que tenemos: Titulo de la canción, artista, “mood” ó estado de ánimo de esa canción, tempo, género, Tipo de artista, fecha en que apareció en el billboard (por ejemplo 20140628 equivale al 28 de junio de 2014), la columna TOP será nuestra etiqueta, en la que aparece 1 si llegó al número uno de Billboard ó 0 si no lo alcanzó y el anio de Nacimiento del artista. Vemos que muchas de las columnas contienen información categórica. La columna durationSeg contiene la duración en segundos de la canción, siendo un valor continuo pero que nos convendrá pasar a categórico más adelante.
Vamos a realizar algunas visualizaciones para comprender mejor nuestros datos.
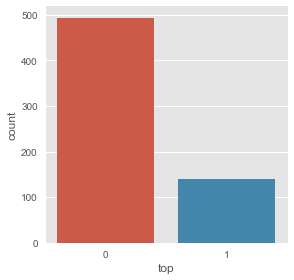
Primero, agrupemos registros para ver cuántos alcanzaron el número uno y cuantos no:
|
1 |
artists_billboard.groupby('top').size() |
nos devuelve:
top
0 494
1 141
Es decir que tenemos 494 canciones que no alcanzaron la cima y a 141 que alcanzaron el número uno. Esto quiere decir que tenemos una cantidad DESBALANCEADA de etiquetas con 1 y 0. Lo tendremos en cuenta al momento de crear el árbol.
Visualizamos esta diferencia:
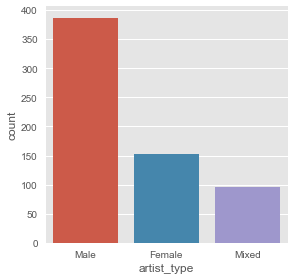
Veamos cuántos registros hay de tipo de artista, “mood”, tempo y género de las canciones:
|
1 |
sb.factorplot('artist_type',data=artists_billboard,kind="count") |
|
1 |
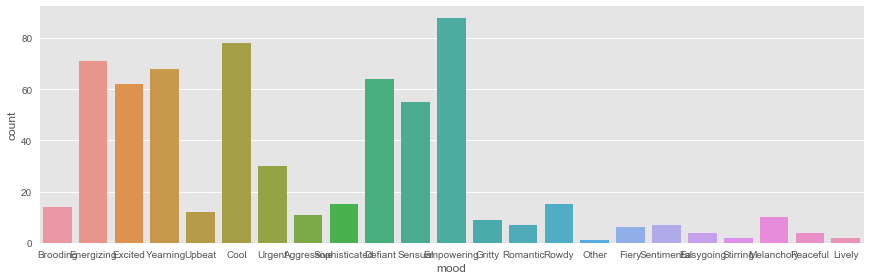
sb.factorplot('mood',data=artists_billboard,kind="count", aspect=3) |
|
1 |
sb.factorplot('tempo',data=artists_billboard,hue='top',kind="count") |
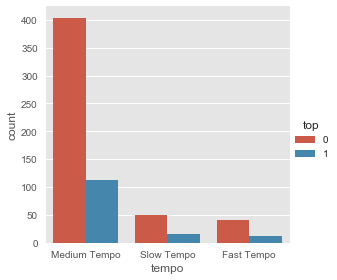
|
1 |
sb.factorplot('genre',data=artists_billboard,kind="count", aspect=3) |
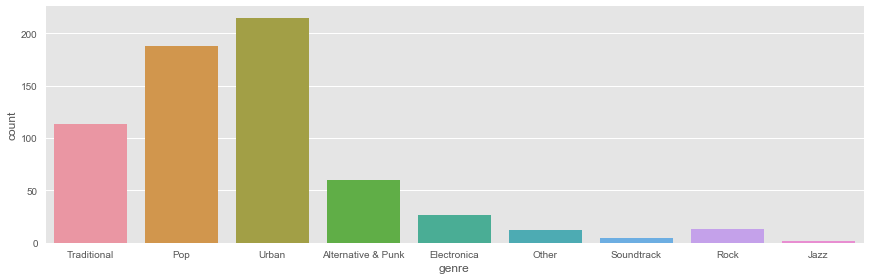
Veamos ahora que pasa al visualizar los años de nacimiento de los artistas:
|
1 |
sb.factorplot('anioNacimiento',data=artists_billboard,kind="count", aspect=3) |
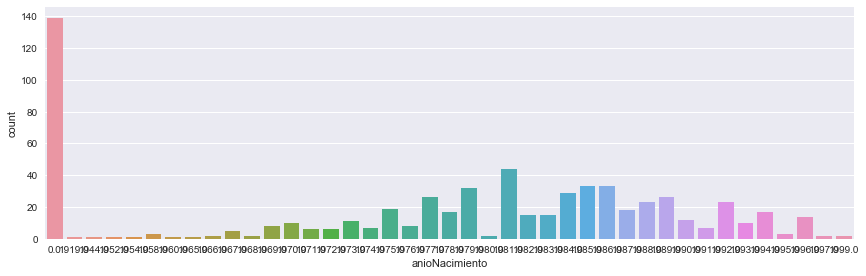
Como se ve en la gráfica tenemos cerca de 140 canciones de las cuales desconocemos el año de nacimiento del artista. El resto de años parecen concentrarse entre 1979 y 1994 (a ojo). Más adelante trataremos estos registros.
Balanceo de Datos: Pocos artistas llegan al número uno
Como dijimos antes, no tenemos “equilibrio” en la cantidad de etiquetas top y “no-top” de las canciones. Esto se debe a que en el transcurso de un año, apenas unas 5 o 6 canciones logran el primer puesto y se mantienen durante varias semanas en ese puesto. Cuando inicialmente extraje las canciones, utilicé 2014 y 2015 y tenía apenas a 11 canciones en el top de Billboard y 494 que no llegaron.
Para intentar equilibrar los casos positivos agregué solamente los TOP de los años 2004 al 2013. Con eso conseguí los valores que tenemos en el archivo csv: son 494 “no-top” y 141 top. A pesar de esto sigue estando desbalanceado, y podríamos seguir agregando sólo canciones TOP de años previos, pero utilizaremos un parámetro (class_weight) del algoritmo de árbol de decisión para compensar esta diferencia.
En e l artículo “Clasificación con Datos Desbalanceados” te cuento todas las estrategias para equilibrar las clases
Visualicemos los top y no top de acuerdo a sus fechas en los Charts:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
f1 = artists_billboard['chart_date'].values f2 = artists_billboard['durationSeg'].values colores=['orange','blue'] # si no estaban declarados previamente tamanios=[60,40] # si no estaban declarados previamente asignar=[] asignar2=[] for index, row in artists_billboard.iterrows(): asignar.append(colores[row['top']]) asignar2.append(tamanios[row['top']]) plt.scatter(f1, f2, c=asignar, s=tamanios) plt.axis([20030101,20160101,0,600]) plt.show() |
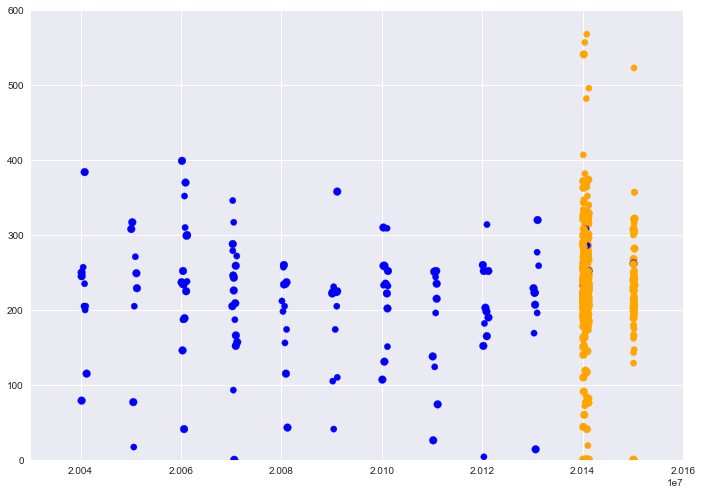
Preparamos los datos
Vamos a arreglar el problema de los años de nacimiento que están en cero. Realmente el “feature” o característica que queremos obtener es : “sabiendo el año de nacimiento del cantante, calcular qué edad tenía al momento de aparecer en el Billboard”. Por ejemplo un artista que nació en 1982 y apareció en los charts en 2012, tenía 30 años.
Primero vamos a sustituir los ceros de la columna “anioNacimiento”por el valor None -que es es nulo en Python-.
|
1 2 3 4 5 6 |
def edad_fix(anio): if anio==0: return None return anio artists_billboard['anioNacimiento']=artists_billboard.apply(lambda x: edad_fix(x['anioNacimiento']), axis=1); |
Luego vamos a calcular las edades en una nueva columna “edad_en_billboard” restando el año de aparición (los 4 primeros caracteres de chart_date) al año de nacimiento. En las filas que estaba el año en None, tendremos como resultado edad None.
|
1 2 3 4 5 6 7 8 |
def calcula_edad(anio,cuando): cad = str(cuando) momento = cad[:4] if anio==0.0: return None return int(momento) - anio artists_billboard['edad_en_billboard']=artists_billboard.apply(lambda x: calcula_edad(x['anioNacimiento'],x['chart_date']), axis=1); |
Y finalmente asignaremos edades aleatorias a los registros faltantes: para ello, obtenemos el promedio de edad de nuestro conjunto (avg) y su desvío estándar (std) -por eso necesitábamos las edades en None- y pedimos valores random a la función que van desde avg – std hasta avg + std. En nuestro caso son edades de entre 21 a 37 años.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
age_avg = artists_billboard['edad_en_billboard'].mean() age_std = artists_billboard['edad_en_billboard'].std() age_null_count = artists_billboard['edad_en_billboard'].isnull().sum() age_null_random_list = np.random.randint(age_avg - age_std, age_avg + age_std, size=age_null_count) conValoresNulos = np.isnan(artists_billboard['edad_en_billboard']) artists_billboard.loc[np.isnan(artists_billboard['edad_en_billboard']), 'edad_en_billboard'] = age_null_random_list artists_billboard['edad_en_billboard'] = artists_billboard['edad_en_billboard'].astype(int) print("Edad Promedio: " + str(age_avg)) print("Desvió Std Edad: " + str(age_std)) print("Intervalo para asignar edad aleatoria: " + str(int(age_avg - age_std)) + " a " + str(int(age_avg + age_std))) |
Si bien lo ideal es contar con la información real, y de hecho la podemos obtener buscando en Wikipedia (o en otras webs de música), quise mostrar otra vía para poder completar datos faltantes manteniendo los promedios de edades que teníamos en nuestro conjunto de datos.
Podemos visualizar los valores que agregamos (en color verde) en el siguiente gráfico:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
f1 = artists_billboard['edad_en_billboard'].values f2 = artists_billboard.index colores = ['orange','blue','green'] asignar=[] for index, row in artists_billboard.iterrows(): if (conValoresNulos[index]): asignar.append(colores[2]) # verde else: asignar.append(colores[row['top']]) plt.scatter(f1, f2, c=asignar, s=30) plt.axis([15,50,0,650]) plt.show() |
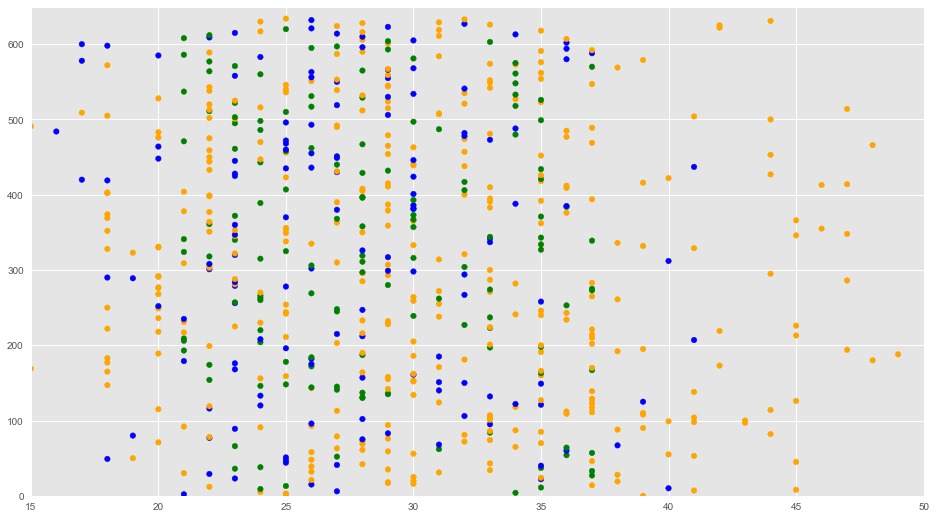
Mapeo de Datos
Vamos a transformar varios de los datos de entrada en valores categóricos. Las edades, las separamos en: menor de 21 años, entre 21 y 26, etc. las duraciones de canciones también, por ej. entre 150 y 180 segundos, etc. Para los estados de ánimo (mood) agrupé los que eran similares.
El Tempo que puede ser lento, medio o rápido queda mapeado: 0-Rapido, 1-Lento, 2-Medio (por cantidad de canciones en cada tempo: el Medio es el que más tiene)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
# Mood Mapping artists_billboard['moodEncoded'] = artists_billboard['mood'].map( {'Energizing': 6, 'Empowering': 6, 'Cool': 5, 'Yearning': 4, # anhelo, deseo, ansia 'Excited': 5, #emocionado 'Defiant': 3, 'Sensual': 2, 'Gritty': 3, #coraje 'Sophisticated': 4, 'Aggressive': 4, # provocativo 'Fiery': 4, #caracter fuerte 'Urgent': 3, 'Rowdy': 4, #ruidoso alboroto 'Sentimental': 4, 'Easygoing': 1, # sencillo 'Melancholy': 4, 'Romantic': 2, 'Peaceful': 1, 'Brooding': 4, # melancolico 'Upbeat': 5, #optimista alegre 'Stirring': 5, #emocionante 'Lively': 5, #animado 'Other': 0,'':0} ).astype(int) # Tempo Mapping artists_billboard['tempoEncoded'] = artists_billboard['tempo'].map( {'Fast Tempo': 0, 'Medium Tempo': 2, 'Slow Tempo': 1, '': 0} ).astype(int) # Genre Mapping artists_billboard['genreEncoded'] = artists_billboard['genre'].map( {'Urban': 4, 'Pop': 3, 'Traditional': 2, 'Alternative & Punk': 1, 'Electronica': 1, 'Rock': 1, 'Soundtrack': 0, 'Jazz': 0, 'Other':0,'':0} ).astype(int) # artist_type Mapping artists_billboard['artist_typeEncoded'] = artists_billboard['artist_type'].map( {'Female': 2, 'Male': 3, 'Mixed': 1, '': 0} ).astype(int) # Mapping edad en la que llegaron al billboard artists_billboard.loc[ artists_billboard['edad_en_billboard'] <= 21, 'edadEncoded'] = 0 artists_billboard.loc[(artists_billboard['edad_en_billboard'] > 21) & (artists_billboard['edad_en_billboard'] <= 26), 'edadEncoded'] = 1 artists_billboard.loc[(artists_billboard['edad_en_billboard'] > 26) & (artists_billboard['edad_en_billboard'] <= 30), 'edadEncoded'] = 2 artists_billboard.loc[(artists_billboard['edad_en_billboard'] > 30) & (artists_billboard['edad_en_billboard'] <= 40), 'edadEncoded'] = 3 artists_billboard.loc[ artists_billboard['edad_en_billboard'] > 40, 'edadEncoded'] = 4 # Mapping Song Duration artists_billboard.loc[ artists_billboard['durationSeg'] <= 150, 'durationEncoded'] = 0 artists_billboard.loc[(artists_billboard['durationSeg'] > 150) & (artists_billboard['durationSeg'] <= 180), 'durationEncoded'] = 1 artists_billboard.loc[(artists_billboard['durationSeg'] > 180) & (artists_billboard['durationSeg'] <= 210), 'durationEncoded'] = 2 artists_billboard.loc[(artists_billboard['durationSeg'] > 210) & (artists_billboard['durationSeg'] <= 240), 'durationEncoded'] = 3 artists_billboard.loc[(artists_billboard['durationSeg'] > 240) & (artists_billboard['durationSeg'] <= 270), 'durationEncoded'] = 4 artists_billboard.loc[(artists_billboard['durationSeg'] > 270) & (artists_billboard['durationSeg'] <= 300), 'durationEncoded'] = 5 artists_billboard.loc[ artists_billboard['durationSeg'] > 300, 'durationEncoded'] = 6 |
Finalmente obtenemos un nuevo conjunto de datos llamado artists_encoded con el que tenemos los atributos definitivos para crear nuestro árbol. Para ello, quitamos todas las columnas que no necesitamos con “drop”:
|
1 2 |
drop_elements = ['id','title','artist','mood','tempo','genre','artist_type','chart_date','anioNacimiento','durationSeg','edad_en_billboard'] artists_encoded = artists_billboard.drop(drop_elements, axis = 1) |
Como quedan los top en relación a los datos mapeados
Revisemos en tablas cómo se reparten los top=1 en los diversos atributos mapeados. Sobre la columna sum, estarán los top, pues al ser valor 0 o 1, sólo se sumarán los que sí llegaron al número 1.
|
1 |
artists_encoded[['moodEncoded', 'top']].groupby(['moodEncoded'], as_index=False).agg(['mean', 'count', 'sum']) |
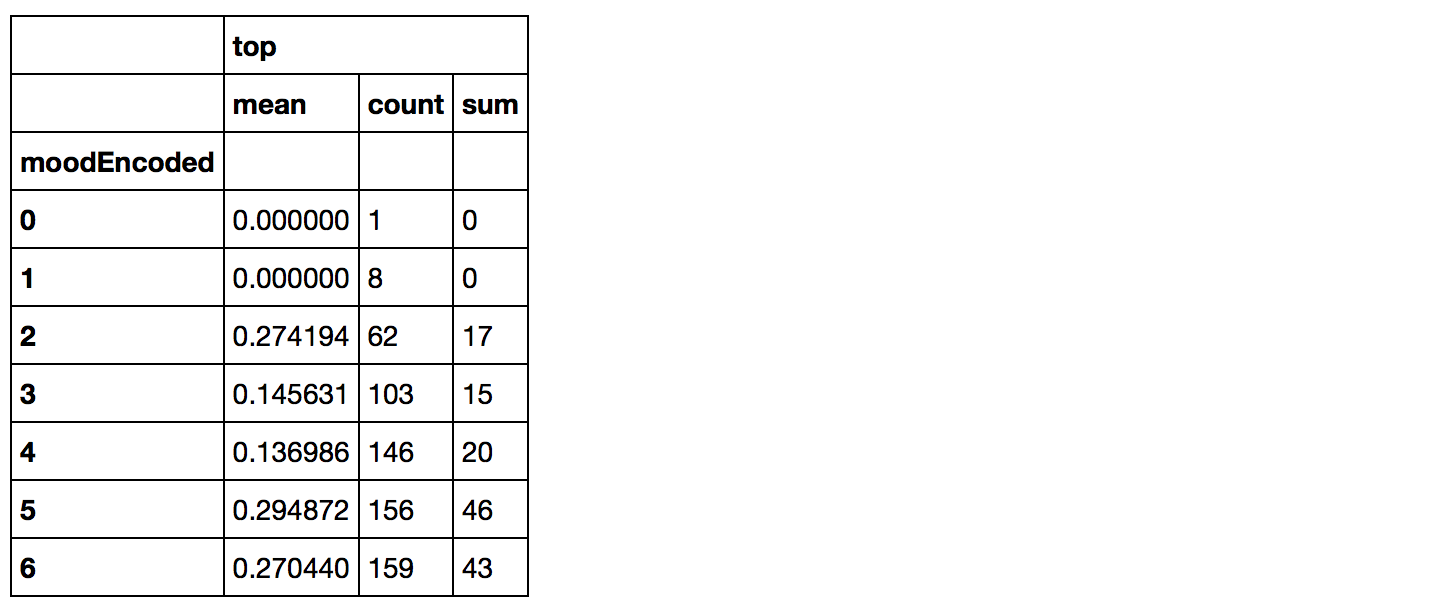
|
1 |
artists_encoded[['artist_typeEncoded', 'top']].groupby(['artist_typeEncoded'], as_index=False).agg(['mean', 'count', 'sum']) |
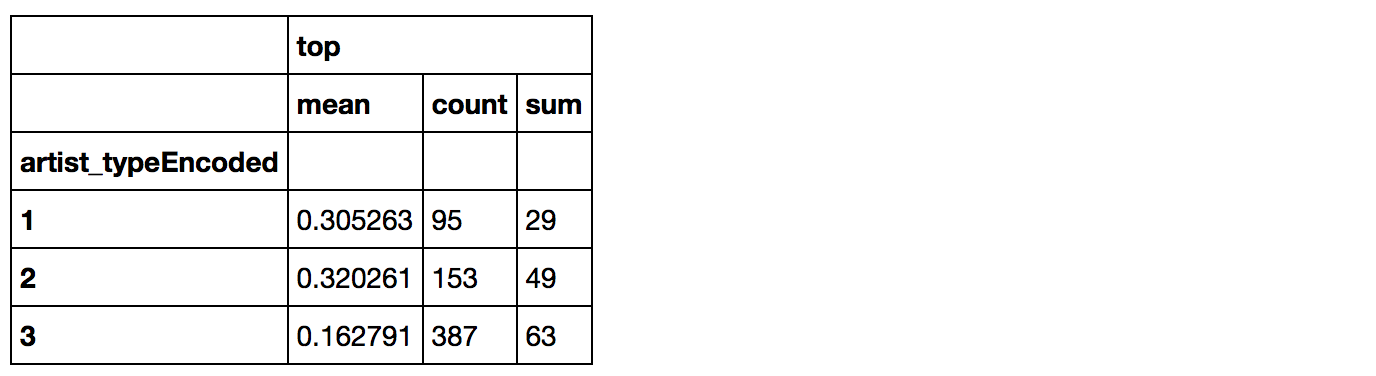
|
1 |
artists_encoded[['genreEncoded', 'top']].groupby(['genreEncoded'], as_index=False).agg(['mean', 'count', 'sum']) |
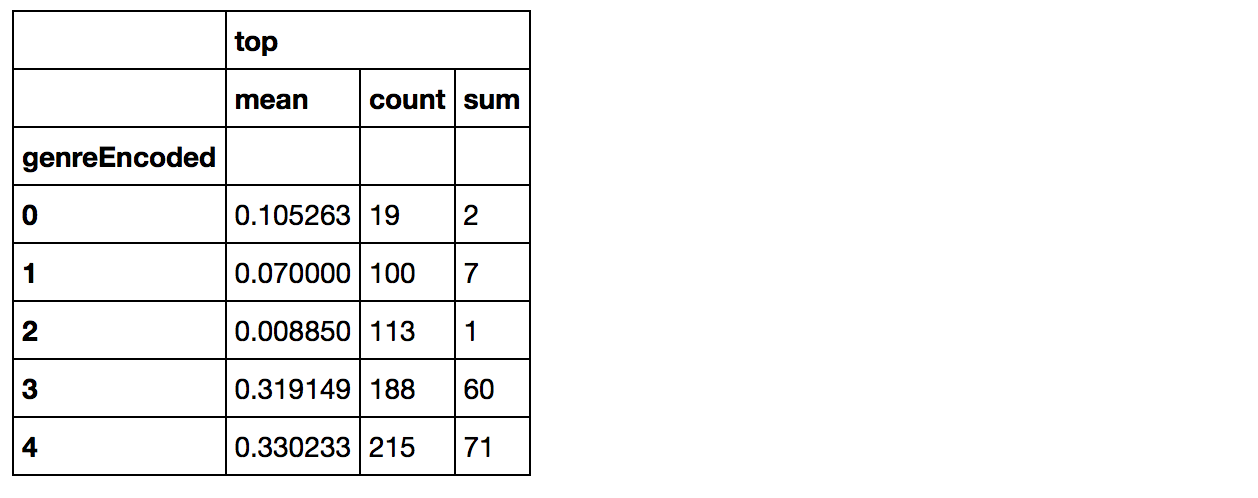
|
1 |
artists_encoded[['tempoEncoded', 'top']].groupby(['tempoEncoded'], as_index=False).agg(['mean', 'count', 'sum']) |

|
1 |
artists_encoded[['durationEncoded', 'top']].groupby(['durationEncoded'], as_index=False).agg(['mean', 'count', 'sum']) |
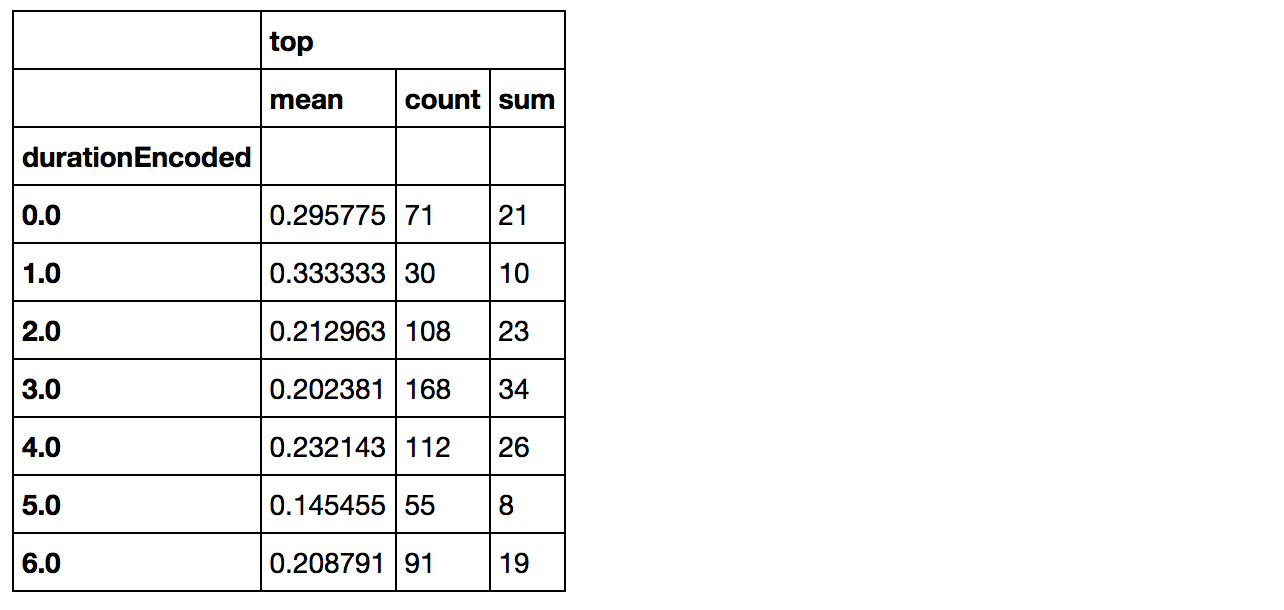
|
1 |
artists_encoded[['edadEncoded', 'top']].groupby(['edadEncoded'], as_index=False).agg(['mean', 'count', 'sum']) |
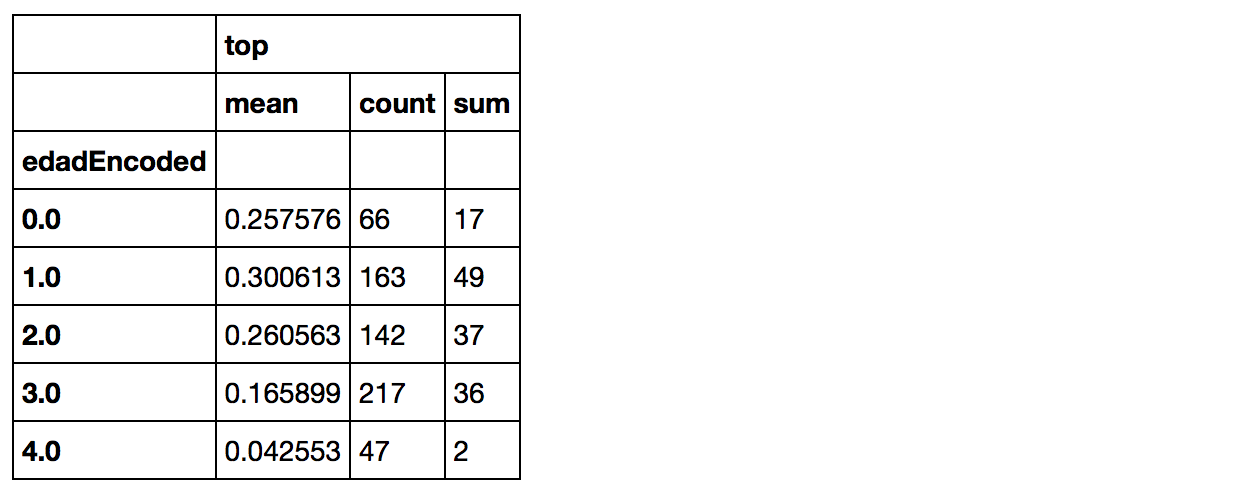
Buscamos la profundidad para nuestro árbol de decisión
Ya casi tenemos nuestro árbol. Antes de crearlo, vamos a buscar cuántos niveles de profundidad le asignaremos. Para ello, aprovecharemos la función de KFold que nos ayudará a crear varios subgrupos con nuestros datos de entrada para validar y valorar los árboles con diversos niveles de profundidad. De entre ellos, escogeremos el de mejor resultado.
Creamos el árbol y lo tuneamos
Para crear el árbol utilizamos de la librería de sklearn tree.DecisionTreeClasifier pues buscamos un árbol de clasificación (no de Regresión). Lo configuramos con los parámetros:
- criterion=entropy ó podría ser gini, pero utilizamos entradas categóricas
- min_samples_split=20 se refiere a la cantidad mínima de muestras que debe tener un nodo para poder subdividir.
- min_samples_leaf=5 cantidad mínima que puede tener una hoja final. Si tuviera menos, no se formaría esa hoja y “subiría” un nivel, su antecesor.
- class_weight={1:3.5} IMPORTANTíSIMO: con esto compensamos los desbalances que hubiera. En nuestro caso, como venía diciendo anteriormente, tenemos menos etiquetas de tipo top=1 (los artistas que llegaron al número 1 del ranking). Por lo tanto, le asignamos 3.5 de peso a la etiqueta 1 para compensar. El valor sale de dividir la cantidad de top=0 (son 494) con los top=1 (son 141).
NOTA: estos valores asignados a los parámetros fueron puestos luego de prueba y error (muchas veces visualizando el árbol, en el siguiente paso y retrocediendo a este).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
cv = KFold(n_splits=10) # Numero deseado de "folds" que haremos accuracies = list() max_attributes = len(list(artists_encoded)) depth_range = range(1, max_attributes + 1) # Testearemos la profundidad de 1 a cantidad de atributos +1 for depth in depth_range: fold_accuracy = [] tree_model = tree.DecisionTreeClassifier(criterion='entropy', min_samples_split=20, min_samples_leaf=5, max_depth = depth, class_weight={1:3.5}) for train_fold, valid_fold in cv.split(artists_encoded): f_train = artists_encoded.loc[train_fold] f_valid = artists_encoded.loc[valid_fold] model = tree_model.fit(X = f_train.drop(['top'], axis=1), y = f_train["top"]) valid_acc = model.score(X = f_valid.drop(['top'], axis=1), y = f_valid["top"]) # calculamos la precision con el segmento de validacion fold_accuracy.append(valid_acc) avg = sum(fold_accuracy)/len(fold_accuracy) accuracies.append(avg) # Mostramos los resultados obtenidos df = pd.DataFrame({"Max Depth": depth_range, "Average Accuracy": accuracies}) df = df[["Max Depth", "Average Accuracy"]] print(df.to_string(index=False)) |

Podmeos ver que en 4 niveles de splits tenemos el score más alto, con casi 65%.
Ahora ya sólo nos queda crear y visualizar nuestro árbol de 4 niveles de profundidad.
Visualización del árbol de decisión
Asignamos los datos de entrada y los parámetros que configuramos anteriormente con 4 niveles de profundidad. Utilizaremos la función de export_graphviz para crear un archivo de extensión .dot que luego convertiremos en un gráfico png para visualizar el árbol.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# Crear arrays de entrenamiento y las etiquetas que indican si llegó a top o no y_train = artists_encoded['top'] x_train = artists_encoded.drop(['top'], axis=1).values # Crear Arbol de decision con profundidad = 4 decision_tree = tree.DecisionTreeClassifier(criterion='entropy', min_samples_split=20, min_samples_leaf=5, max_depth = 4, class_weight={1:3.5}) decision_tree.fit(x_train, y_train) # exportar el modelo a archivo .dot with open(r"tree1.dot", 'w') as f: f = tree.export_graphviz(decision_tree, out_file=f, max_depth = 7, impurity = True, feature_names = list(artists_encoded.drop(['top'], axis=1)), class_names = ['No', 'N1 Billboard'], rounded = True, filled= True ) # Convertir el archivo .dot a png para poder visualizarlo check_call(['dot','-Tpng',r'tree1.dot','-o',r'tree1.png']) PImage("tree1.png") |
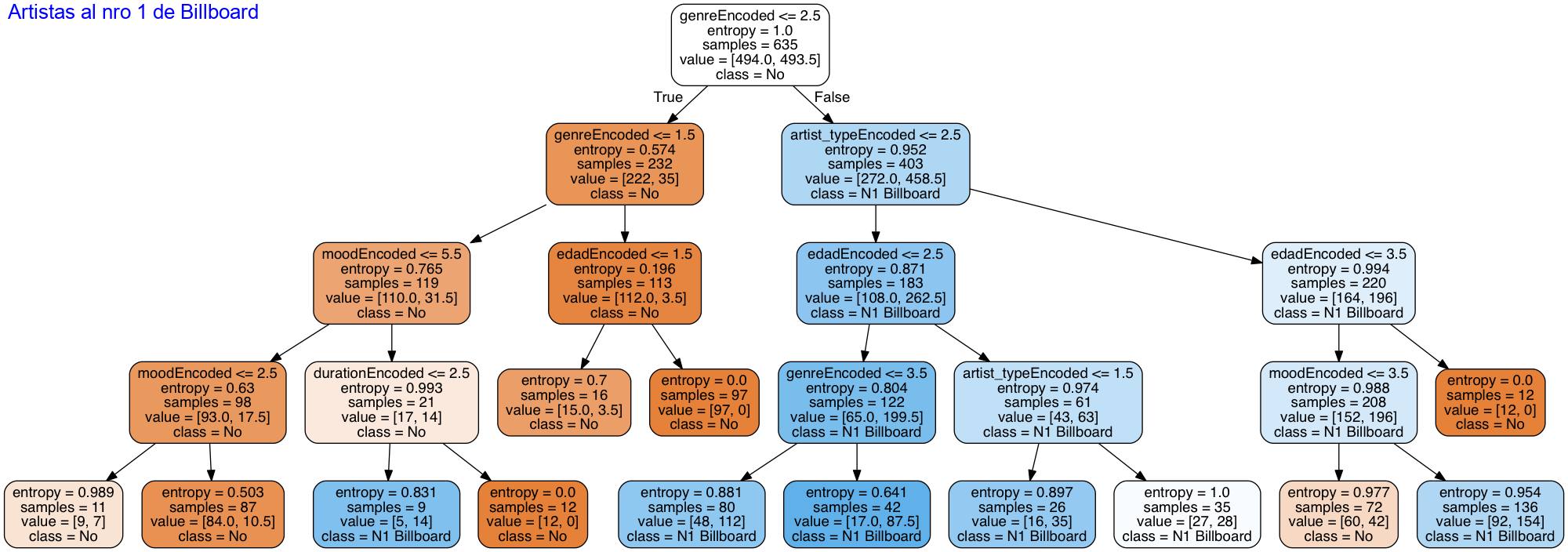
Al fin nuestro preciado árbol aparece en pantalla!. Ahora tendremos que mirar y ver si lo podemos mejorar (por ejemplo tuneando los parámetros de entrada).
Conclusiones y análisis del árbol
En la gráfica vemos, un nodo raíz que hace una primer subdivisión por género y las salidas van a izquierda por True que sea menor a 2.5, es decir los géneros 0, 1 y 2 (eran los que menos top=1 tenían) y a derecha en False van los géneros 3 y 4 que eran Pop y Urban con gran cantidad de usuarios top Billboard.
En el segundo nivel vemos que la cantidad de muestras (samples) queda repartida en 232 y 403 respectivamente.
A medida que bajamos de nivel veremos que los valores de entropía se aproximan más a 1 cuando el nodo tiene más muestras top=1 (azul) y se acercan a 0 cuando hay mayoría de muestras Top=0 (naranja).
En los diversos niveles veremos divisiones por tipo de artista , edad, duración y mood. También vemos algunas hojas naranjas que finalizan antes de llegar al último nivel: esto es porque alcanzan un nivel de entropía cero, o porque quedan con una cantidad de muestras menor a nuestro mínimo permitido para hacer split (20).
Veamos cuál fue la precisión alcanzada por nuestro árbol:
|
1 2 |
acc_decision_tree = round(decision_tree.score(x_train, y_train) * 100, 2) print(acc_decision_tree) |
Nos da un valor de 64.88%. Notamos en que casi todas las hojas finales del árbol tienen samples mezclados sobre todo en los de salida para clasificar los top=1. Esto hace que se reduzca el score.
Pongamos a prueba nuestro algoritmo
Predicción de Canciones al Billboard 100
Vamos a testear nuestro árbol con 2 artistas que entraron al billboard 100 en 2017: Camila Cabello que llegó al numero 1 con la Canción Havana y Imagine Dragons con su canción Believer que alcanzó un puesto 42 pero no llegó a la cima.
|
1 2 3 4 5 6 7 8 9 |
#predecir artista CAMILA CABELLO featuring YOUNG THUG # con su canción Havana llego a numero 1 Billboard US en 2017 x_test = pd.DataFrame(columns=('top','moodEncoded', 'tempoEncoded', 'genreEncoded','artist_typeEncoded','edadEncoded','durationEncoded')) x_test.loc[0] = (1,5,2,4,1,0,3) y_pred = decision_tree.predict(x_test.drop(['top'], axis = 1)) print("Prediccion: " + str(y_pred)) y_proba = decision_tree.predict_proba(x_test.drop(['top'], axis = 1)) print("Probabilidad de Acierto: " + str(round(y_proba[0][y_pred]* 100, 2))+"%") |
Nos da que Havana llegará al top 1 con una probabilidad del 83%. Nada mal…
|
1 2 3 4 5 6 7 8 9 |
#predecir artista Imagine Dragons # con su canción Believer llego al puesto 42 Billboard US en 2017 x_test = pd.DataFrame(columns=('top','moodEncoded', 'tempoEncoded', 'genreEncoded','artist_typeEncoded','edadEncoded','durationEncoded')) x_test.loc[0] = (0,4,2,1,3,2,3) y_pred = decision_tree.predict(x_test.drop(['top'], axis = 1)) print("Prediccion: " + str(y_pred)) y_proba = decision_tree.predict_proba(x_test.drop(['top'], axis = 1)) print("Probabilidad de Acierto: " + str(round(y_proba[0][y_pred]* 100, 2))+"%") |
Nos da que la canción de Imagine Dragons NO llegará con una certeza del 88%. Otro acierto.
Veamos los caminos tomados por cada una de las canciones:
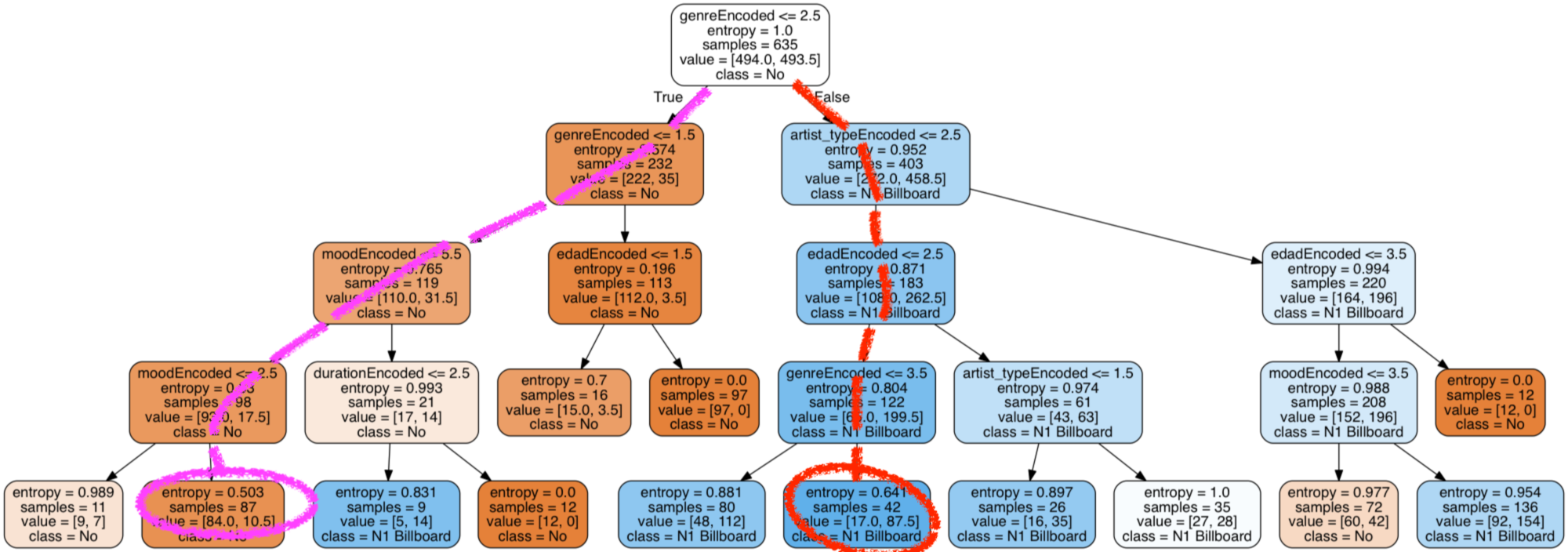
Te atreves con un ejercicio de Aprendizaje No supervisado? Utiliza K-means con este ejemplo práctico
Conclusiones Finales
Pues hemos tenido un largo camino, para poder crear y generar nuestro árbol. Hemos revisado los datos de entrada, los hemos procesado, los pasamos a valores categóricos y generamos el árbol. Lo hemos puesto a prueba para validarlo.
Obtener un score de menos de 65% en el árbol no es un valor muy alto, pero tengamos en cuenta que nos pusimos una tarea bastante difícil de lograr: poder predecir al número 1 del Billboard y con un tamaño de muestras tan pequeño (635 registros) y desbalanceado. Ya quisieran las discográficas poder hacerlo 🙂
Espero que hayan disfrutado de este artículo y si encuentran errores, comentarios, o sugerencias para mejorarlo, siempre son bienvenidas. Además pueden escribirme si tienen problemas en intentaré responder a la brevedad.
Como siempre los invito a suscribirse al blog para seguir creciendo como comunidad de desarrolladores que estamos aprendiendo mediante ejemplos a crear algoritmos inteligentes.
Suscribirme al Blog
Recibir el próximo artículo quincenal sobre Machine Learning y prácticas en Python
Y si quieres aprender otros ejercicios en Python puedes hacer nuestros Ejercicios paso a paso de Regresión Lineal, Regresión Logística o de Aprendizaje no supervisado clustering K-means.
Recursos y enlaces del ejercicio
- Descarga la Jupyter Notebook y el archivo de entrada csv
- ó puedes visualizar online
- o ver y descargar desde mi cuenta github
- Artículo Ejemplo Webscraping en Python
- Cómo balancear tus set de datos
Ahora que sabes árboles de decisión, ya puedes aprender Random Forest
Otros enlaces con Artículos sobre Decisión Tree (en Inglés)
- introduction-to-decision-trees-titanic-dataset
- Decision Trees in Python
- Decision Trees with Scikit learn
- Building decision tree algorithm
El libro del Blog (en desarrollo)
Puedes colaborar comprando el libro ó lo puedes descargar gratuitamente. Aún está en borrador, pero apreciaré mucho tu ayuda! Contiene Extras descargares como el “Lego Dataset” utilizado en el artículo de Detección de Objetos.
Muy bueno, te sigo constantemente con tus articulos, te felicito por tomarte el tiempo para compartir tu conocimiento
Gracias Sebastian! Me alegra que me escribas y que sirvan mis artículos! Este en particular me llevó mucho más de lo que pensaba… Pues iba a ser un árbol “normal” y fueron apareciendo muchos obstáculos para alcanzar el objetivo. Pero creo que sirve ver como encarar los problemas que surgen al enfrentarse con los datos y como irlos resolviendo. Saludos y espero que sigamos en contacto!
Muy buen artículo. Gracias por compartirlo!
Hola Lautaro, muchas gracias a vos por compartir el blog! Saludos y espero seguir en contacto
Tengo una pregunta, y disculpa mi ignorancia respecto al tema: para ambas predicciones el código es prácticamente el mismo…lo que cambia es x_test.loc[0]…ahora mi pregunta es como x_test.loc[0] = (1,5,2,4,1,0,3) se traduce en “#predecir artista CAMILA CABELLO featuring YOUNG THUG
con su canción Havana llego a numero 1 Billboard US en 2017”
Hola Robert, gracias por escribir. Te cuento que los valores salen de los valores reales de la canción de Camila Cabello obtenidos con las APIs de música (Gracenote) y luego mapeados a valores discretos. Por ejemplo la edad era menor a 21 años al momento de publicar la canción y se mapea con un 0
Excelente Juan Ignacio…esta tarde voy a tratar de replicar y rutear tu repositorio para llenar los espacios en blanco…Muchas gracias
Me alegro mucho! Espero que te sirva y cualquier cosa me escribes. Puede que tarde en responder a veces (pues tengo 4 hijos pequeños…) Pero en cuanto pueda, lo haré
Creo que ya lo entendí…la canción havana y la believer no están en el dataset original que se uso para entrenar el modelo…lo que hiciste fue consultar la api de gracenote para la canción habana que te retorno los valores 1,5,2,4,1,0,3, para ‘top’,’moodEncoded’, ‘tempoEncoded’, ‘genreEncoded’,’artist_typeEncoded’,’edadEncoded’,’durationEncoded’….armas tu dataframe de test(x_test) y luego con esa data le preguntas al modelo sobre la probabilidad de que llegue al número 1…tengo que cambiar el mindset, espero mi background como desarrollador me ayude, esto se ve muy entretenido!. Gracias de nuevo por tu tiempo.
Podrías explicar como x_test.loc[0] = ?? se traduce en uno u otro de ambos casos. Muchas gracias.
Pues lo que estamos haciendo es crear una tabla de Pandas. Al declararla enumeramos las columnas (top, mood, tempo,etc) y con test.loc[0] lo que decimos es que inserte esos valores a la primer fila (su índice es cero)
Ya lo entendí, la respuesta de gracenote api + el mapeo que usas me debiese dar los valores, por ejemplo edadEncoded <= 21 se mapea a cero. Muchas gracias!!
Hola mi nombre es Wilma y estaba viendo si el codigo funcionaba y me tope con que el archivo tree1.dot no existe, hay que generarlo o este archivo se debe crear?
Hola Wilma, disculpa la tardanza en responder. El archivo tree.dot se genera al ejecutar el código. Y luego se utiliza para generar el gráfico PNG (o jpg).
Gracias por comentar y espero sigas visitando el blog!
Buenas tardes, mi problema es que me genera el archivo tree1.dot pero a partir de ahi como genero el gráfico PNG ? me da este error al ejecutar el código:
FileNotFoundError: [WinError 2] El sistema no puede encontrar el archivo especificado
Para resolverlo lo que hice fue:
Instalar externamente graphivz desde aqui https://graphviz.gitlab.io/_pages/Download/Download_windows.html
2.a Agregar a las variables de sistemas ‘PATH’, tanto la carpeta BIN, como sale en este video.
.
2.b Agregar también: C:\Program Files (x86)\Graphviz2.38\bin\dot.exe a las variables de sistema PATH
Abrir la consola o la consola de CONDA y aplicar en este ORDEN:
A. pip install graphviz
B. conda install graphviz
Instalar en el mismo ambiente de trabajo [en lineas de codigo en mi caso en celda del jupyter notebook) (Estoy seguro que esto es redudante y quizas no sería necesario, probar solo como último recurso)
A.
!pip install pydot
!pip install graphviz
!pip install Pillow
Importar las librerias (Aqui asumo que igual puede haber algo de redundancia, que no quiero averiguar por ahora que funciona jajaj)
import PIL
import pydot
import graphviz
En el link 1 que puse, en los post relacionados que pueden mirar, el ejecutar en la consola o conda:
dot -version para verificar que esta bien instalado ese ejecutable.
pd: Grande Juan Ignacio por tu curso. De hecho luego de 3 meses de estudio a fondo en ML en varios cursos, lo estoy tomando como mi curso PRACTICO de implementacion final para darme por auto-Licenciado y salir a un mercado laboral sabiend y diciendo que he aplicado cada MODELO importante en código. Tu blog completo lo tomé como mi prueba de examen final para graduarme jaja
Fuentes:
1. http://www.programmersought.com/article/7318590508/;jsessionid=56943218C2A9F8AB97577678F17A2371
https://github.com/conda/conda/issues/1851
Demáses foros, stackoverflow, etc….
Hola. Mi nombre es Jaime. Intento hacer el ejercicio completo pero no encuentro el archivo donde estan los 6 mil y tantos registros de los artistas. Me puedes apoyar en publicarlo para que lo pueda bajar y seguir tu ejercicio please?
Hola Jaime, gracias por escribir y participar. El archivo está en el enlace que dice “archivo entrada csv” al final del artículo bajo el título de Recursos y enlaces. Te dejo el mismo enlace aqui: descarga archivo csv ejercicio
Hola Juan Ignacio!!
Yo tenía la misma duda. Excelente tu libro y Blog, realmente una gran ayuda. Muchas gracias !!!!
Hola Rodrigo, gracias por escribir!, un saludo
Hola. Soy Jaime. Apenas empiezo en este mundo de Python y ML. Me pueden explicar para que sirve la linea %matplotlib inline. Ya que cuando la corro en el prompt de Python me marca error (invalid sintax). Pero si la corro en Jupiter no me marca error.
Esa linea es exactamente para que grafique la librería matplot dentro de las Jupyter Notebooks. Te dejo el enlace Plotting with Matplotlib
hola podrias compartirnos el datasent para practicar, porfavor!
Claro!, el dataset está al final del artículo y es este mismo archivo csv
Hola Juan Ignacio.
Estoy intentando que me aparezca la imagen del árbol y no hay manera.
El archivo tree1.dot lo tengo ubicado en la misma carpeta donde se encuentra el artists_billboard.csv y el archivo .ipynb de Jupyter.
FileNotFoundError Traceback (most recent call last)
in ()
23
24 # Convertir el archivo .dot a png para poder visualizarlo
—> 25 check_call([‘dot’,’-Tpng’,r’tree1.dot’,’-o’,r’tree1.png’])
26 PImage(“tree1.png”)
FileNotFoundError: [WinError 2] El sistema no puede encontrar el archivo especificado
¿Me podrías decir donde ubicar el tree1.dot?
Gracias por tu gran blog!
Hola Pedro, para poder ayudarte, dime si estás usando Anaconda u otra suite ó Python 3.6 desde línea de comandos.
A su vez, comprueba si tienes instalado el modulo PIL que es el que convierte de tree.dot a imagen.
Si no lo tienes puedes instalarlo via:
Por último, imagino que tienes permisos de escritura en el directorio donde estás ejecutando el código, no? pues tanto el archivo dot como el png se generan “on the fly” y el programa necesita poder escribir en esos directorios.
Saludos, dime si se corrige o me comentas si da otro error
Gracias Nacho por tu rápida respuesta.
Tengo permisos de administrador.
Tengo anaconda y la versión de Python es la 3.5.5
Al intentar instalar el pàquete PIL da este error:
(py35) C:\Users\Administrador>conda install -c anaconda pil
Solving environment: failed
UnsatisfiableError: The following specifications were found to be in conflict:
– pil
– tensorboard
Use “conda info ” to see the dependencies for each package.
Prueba instalar con la interfaz gráfica:
Abre Anaconda Navigator
Environments
Marca “ALL” en el combobox
En Search Package escribes “pip”
Del listado marca donde la columna Name ponga “pil”
Le das a Apply
Con eso te lo debería descargar e instalar.
Hola ! Tengo una pregunta, que significan los valores del atributo “values” [222, 35] (por ejemplo) dentro de cada nodo del arbol?
Hola Simon, gracias por escribir. Te respondo: Como verás el campo samples pone la cantidad de muestras que están en ese nodo del árbol, por ejemplo en el nodo que tu indicas son 232 de las 635 iniciales. Pues en el campo de values nos indica cuántas muestras se corresponde con True o con False de la condición. Te preguntarás: ¿pero si 222 + 35 no es igual a 232? Es cierto PERO esto tiene explicación: cuando creamos el DecisionTreeClassifier le indicamos class_weight={1:3.5} y con esto le dimos un valor de 3.5 a las muestras de “rama del False”. Entonces si hacemos 35/3.5 nos da 10. Y ahora si sumas 222 + 10 = 232… y ahí está la magia 😉
Saludos
Hola, muy bueno por cierto, solo en la parte de “Visualicemos los top y no top de acuerdo a sus fechas en los Charts:” me atoré un poco hasta que encontré el por que no funcionaba mi código, para los novatos (como yo) que lo lean en un futuro agreguen las siguientes lineas antes del for:
colores = [‘orange’,’blue’]
tamanios = [30, 50]
Exito a todos!
Hola Angel, muchas gracias por el comentario y me parece buena la recomendación. Como en el código completo esas variables estaban inicializadas antes, no las puse para no repetir código, pero para el artículo puede que falten, por lo tanto lo edité tal cual lo sugieres. Muchas gracias por la ayuda!
Saludos,
Hola, he intentado reproducir todo el ejercicio y casi al final cuando se ejecuta la línea:
check_call([‘dot’,’-Tpng’,r’tree1.dot’,’-o’,r’tree1.png’])
me muestra el siguiente error:
[WinError 2] El sistema no puede encontrar el archivo especificado
me había creado el fichero tree1.dot previamente, pero sale este error.
¿Me podrías ayudar?
Saludos. Alfredo.
Hola alfredo, eso me suena a que falta tener algo instalado… probaste con graphviz? en windows debes hacer el pip install pero también tienes que agregar “manualmente” unas variables de entorno. Revisa la doc https://pypi.org/project/graphviz/
Saludos y si puedes me cuentas si pudiste resolverlo o te hecho una mano de nuevo
Gracias Na8 por tu ayuda. Voy a probar eso y ya te digo …
Saludos.
Hola Na8, probé el ejemplo del enlace que me diste, y tengo un problema similar, o sea, me crea el fichero .dot pero ni me lo convierte a un fichero gráfico, ni me muestra el árbol de decisión.
Estuve buscando más información al respecto en internet, y parece que el paquete pydot cuando se instala viene roto y la solución es bastante arriesgada, ya que hay que modificar la variable de entorno del “PATH”.
Encontré este sitio:
https://www.analyticslane.com/2018/11/09/visualizacion-de-arboles-de-decision-en-python-con-pydotplus/
donde explica lo mismo con un paquete más actual, el PyDotPlus, pero me sigue pasando lo mismo, o sea, me genera el fichero .dot pero ni me sol convierte a un fuchero gráfico ni me muestra el árbol de decisión.
Ya no sé que hacer. Creo que lo mejor es, no tocar nada más y ver el árbol de decisión en la gráfica de tu artículo.
Saludos. Alfredo.
Hola Na8, cuando ya desistí, resulta que encontré información en internet y haciendo unos cambios ya me creaba el fichero .png, aunque no me lo mostraba. Al final modifiqué unas líneas y por fin ya lo hace todo. Los cambios son los siguientes (por si a alguien le pasa lo que mí):
import pydot
(graph,) = pydot.graph_from_dot_file(r”Datas\tree.dot”)
graph.write_png(r”Datas\tree.png”)
ahora abrimos el fichero con la imagen y la mostramos en una ventana.
img = Image.open(r”Datas\tree.png”)
img.show() # muetra la imagen con el visualizador de fotos de windows.
también mostramos la imagen en la terminal de IPython.
plt.imshow(img) #, cmap = ‘gray’, interpolation = ‘bicubic’)
plt.show()
P.D. Antes de nada habrá que instalar el paquete pydot desde una ventana terminal del PC con :
pip install pydot
Saludos. Alfredo.
Genial Alfredo! Gran contribución! Muchas gracias y saludos
Hola tengo una consulta, en esta
parte
pydot.graph_from_dot_file(r»Datas\tree.dot»)
tu archivo .dot esta en una carpeta llamada “Datas” y no en la misma ruta que tu codigo vdd?. es que me vota el siquiente error [WinError 2] “dot” not found in path.
UUUfff
Soy psicólogo especializado en formación profesional, analfabeto en estas cosas, pero tu artículo me hizo explotar la cabeza…gracias
Hola Jaime me encanta que te explote la cabeza jajaja! Me encanta la psicología! soy argentino, con eso te lo digo todo jajja… Saludos y espero que sigas visitando!
Hola …. segui tu tutorial al pie de la letra sin embargo al querer realizar la prediccion me sale el siguiente error :
ValueError Traceback (most recent call last)
in
5 x_test = pd.DataFrame(columns=(‘top’,’moodEncoded’, ‘tempoEncoded’, ‘genreEncoded’,’artist_typeEncoded’,’edadEncoded’,’durationEncoded’))
6 x_test.loc[0] = (0,4,2,1,3,2,3)
—-> 7 y_pred = decision_tree.predict(x_test.drop([‘top’], axis = 1))
8 print(“Prediccion: ” + str(y_pred))
9 y_proba = decision_tree.predict_proba(x_test.drop([‘top’], axis = 1))
~\Anaconda3\lib\site-packages\sklearn\tree\tree.py in predict(self, X, check_input)
414 “””
415 check_is_fitted(self, ‘tree_’)
–> 416 X = self.validate_X_predict(X, check_input)
417 proba = self.tree.predict(X)
418 n_samples = X.shape[0]
~\Anaconda3\lib\site-packages\sklearn\tree\tree.py in validate_X_predict(self, X, check_input)
386 “match the input. Model n_features is %s and ”
387 “input n_features is %s ”
–> 388 % (self.n_features, n_features))
389
390 return X
ValueError: Number of features of the model must match the input. Model n_features is 7 and input n_features is 6
Puedes ayudarme diciendome por que se produce el error ?
Hola Anthony, gracias por escribir.
Te cuento, el error dice que cuando entrenaste el modelo, tiene como input 7 features pero debería tener 6, pues la etiqueta “top” no es realmente un feature de entrada.
Yo supongo que en alguna de las líneas del código, antes de hacer train, te debes haber olvidado de poner el “drop” de la columna top, por ejemplo en
x_train = artists_encoded.drop(['top'], axis=1).values
Si puedes revisarlo y confirma si es eso.
Saludos
Hola Juan, he seguido el tutorial al pie de la letra, pero al intentar predecir si las canciones que porpones llegan al prmer lugar me encuentro con un error, más precisamente en estas 2 líneas:
y_proba = decision_tree.predict_proba(x_test.drop([‘top’], axis = 1))
print(“Probabilidad de Acierto: ” + str(round(y_proba[0][y_pred]* 100, 2))+”%”)
El error que me dice es que el método “round” no esta definido para un array de numpy, asi que pregunte que forma tiene con
y_proba.shape
Y me dice que es un arreglo (1,2)
Finalmente opté por imprimir
print(y_proba)
[[0.28571429 0.71428571]]
print(y_proba[0])
[0.28571429 0.71428571]
¿Podrías indicarme que he hecho mal?
Hola Auriga, tiene un error esa línea que indicas. Estaba corregido en Github pero no en el artículo, lo correcto debía ser:
print("Probabilidad de Acierto: " + str(round(y_proba[0][y_pred][0]* 100, 2))+"%")
Gracias por escribir!!!
Saludos
Hola Juan, antes que nada quiero agradecerte por el gran conocimiento que has compartido en tu blog, te cuento que he tenido inconvenientes al momento de ejecutar el código para “Creamos el Arbol de Decisión” ya que me despliega que no encuentra el archivo.
Codigo que estoy ejecutando:
Crear arrays de entrenamiento y las etiquetas que indican si llegó a top o no
y_train = artists_encoded[‘top’]
x_train = artists_encoded.drop([‘top’], axis=1).values
Crear Arbol de decision con profundidad = 4
decision_tree = tree.DecisionTreeClassifier(criterion=’entropy’,
min_samples_split=20,
min_samples_leaf=5,
max_depth = 4,
class_weight={1:3.5})
decision_tree.fit(x_train, y_train)
exportar el modelo a archivo .dot
with open(r”tree1.dot”, ‘w’) as f:
f = tree.export_graphviz(decision_tree,
out_file=f,
max_depth = 7,
impurity = True,
feature_names = list(artists_encoded.drop([‘top’], axis=1)),
class_names = [‘No’, ‘N1 Billboard’],
rounded = True,
filled= True )
Convertir el archivo .dot a png para poder visualizarlo
check_call([‘dot’,’-Tpng’,r’tree1.dot’,’-o’,r’tree1.png’])
PImage(“tree1.png”)
Error:
FileNotFoundError Traceback (most recent call last)
in
23
24 # Convertir el archivo .dot a png para poder visualizarlo
—> 25 check_call([‘dot’,’-Tpng’,r’tree1.dot’,’-o’,r’tree1.png’])
26 PImage(“tree1.png”)
~\AppData\Local\Continuum\anaconda3\lib\subprocess.py in _execute_child(self, args, executable, preexec_fn, close_fds, pass_fds, cwd, env, startupinfo, creationflags, shell, p2cread, p2cwrite, c2pread, c2pwrite, errread, errwrite, unused_restore_signals, unused_start_new_session)
1176 env,
1177 os.fspath(cwd) if cwd is not None else None,
-> 1178 startupinfo)
1179 finally:
1180 # Child is launched. Close the parent’s copy of those pipe
FileNotFoundError: [WinError 2] El sistema no puede encontrar el archivo especificado
Prueba instalar como dijo otro usuarios:
pip install pydot
A su vez revisaría instalación de https://scikit-image.org si fuera necesario, puede que en un entorno windows requiera que agregues a mano algunas variables de entorno
men una consulta, una vez decidido el numero de max_depth, en tu caso salio 4, no deberia dividir la data en test y train? o sea en tu caso usaste toda pero si uso de nuevo el train_test_split, crees que altere la forma de predecir el modelo?
Buenas noches,
lo he intentado todo!! 🙁 Llevo dos semanas con el mismo error que ya han comentado algunos compañeros y he intentado 1000 cosas para resolverlo y nada. Así que os quería hacer 2 preguntas:
1.- Una vez tenemos el fichero .dot, se puede transfomar en un árbol de decisión de alguna forma externa, es decir con algún programa o aplicación de Windows? Gracias!!
2.- Por otra parte os dejo el error que me sale por si me podeis ayudar
Traceback (most recent call last):
File “C:\Users\migue\Anaconda3\lib\site-packages\pydot.py”, line 1915, in create
working_dir=tmp_dir,
File “C:\Users\migue\Anaconda3\lib\site-packages\pydot.py”, line 136, in call_graphviz
**kwargs
File “C:\Users\migue\Anaconda3\lib\subprocess.py”, line 775, in __init__
restore_signals, start_new_session)
File “C:\Users\migue\Anaconda3\lib\subprocess.py”, line 1178, in _execute_child
startupinfo)
FileNotFoundError: [WinError 2] El sistema no puede encontrar el archivo especificado
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File “5_Arbol_Decision_ClasificayPredic.py”, line 257, in
graph.write_png(r”tree1.png”)
File “C:\Users\migue\Anaconda3\lib\site-packages\pydot.py”, line 1734, in new_method
encoding=encoding)
File “C:\Users\migue\Anaconda3\lib\site-packages\pydot.py”, line 1817, in write
s = self.create(prog, format, encoding=encoding)
File “C:\Users\migue\Anaconda3\lib\site-packages\pydot.py”, line 1922, in create
raise OSError(*args)
FileNotFoundError: [WinError 2] “dot” not found in path.
he probado muchas de las cosas que comentan en Internet,
pydot y graphdev instalado con última version
He probado también a añadir partes de código como esta:
import os
os.environ[“PATH”] += os.pathsep + ‘C:\Program Files (x86)\Graphviz2.38\bin’
os.environ[“PATH”] += os.pathsep + ‘C:\Program Files (x86)\Graphviz2.38\bin\dot.exe’
O esta otra:
(graph,) = pydot.graph_from_dot_file(r”tree1.dot”)
graph.write_png(r”tree1.png”)
Pero nada.
Muchas gracias y disculpar por el rollo 😉
Lo he resuelto aunque de forma poco “elegante”. He accedido a la librería pydot.py y le he harcodeado la ruta en el prog ;). No es la solución ideal, pero mientras la encuentro, me ha funcionado.
como podria hacer un chatbot con arboles de decision ayudame pls
como obtuviste la base de datos de billboard?
Hola Nacho, he visto que tienes en cuenta que las clases están desbalanceadas en el árbol de decisión. En concreto veo que calculas cómo de desbalanceados están y usas “class_weight={1:3.5}” para que scikit-learn lo tenga en cuenta. Te quería comentar que en scikit-learn también puedes especificar class_weight=”balanced” y te calcula el peso de las clases automáticamente
Felicidades Nacho!!!! Acabo de empezar en el mundo del machine learning y este blog es lo que estaba buscando. Tengo una duda en esta parte del codigo.
f1 = artists_billboard[‘chart_date’].values
f2 = artists_billboard[‘durationSeg’].values
#¿repite propiedad de tamaño y color?
colores=[‘orange’,’blue’] # azul que no son del2014 y 2015
tamanios=[60,10] # tamaño circulos 60_top_0 & 40_top_1
asignar=[]
asignar2=[]
for index, row in artists_billboard.iterrows():
asignar.append(colores[row[‘top’]])
asignar2.append(tamanios[row[‘top’]])
for i in asignar,asignar2:
print(i)
plt.scatter(f1, f2, c=asignar, s=tamanios)# ¿¿¿ Aqui en vez de tamanios seria Asignar2??
plt.axis([20030101,20160101,0,600])
plt.show()
Buenas tardes,
Antes que nada muchas gracias por el esfuerzo realizado al escribir este artículo, es increible.
Perdone si es muy simple mi duda pero llevo tiempo intentando solucionarlo y no doy con ello, tengo el código tal cual, sin embargo me salta el siguiente error al ejecutar el programa:
NameError: name ‘artists_billboard’ is not defined
He intenado esto pero tampoco me ayudó:
artists_billboard = pd.read_csv(“artists_billboard_fx3” , header = 0)
Disculpe las molestias y muchas gracias.
Ya me di cuenta, faltaba la extensión al final del arichivo la cual era .csv
¡Hola! He visto que varios tienen problema para mostrar la gráfica. El rollo es que deben tener instalado externamente graphviz y añadir ciertas cosas. Aquí les dejo un link para la instalación, está bastante completo. Con eso ya me funcionó perfectamente.
[youtube=https://www.youtube.com/watch?v=WkLhdBbf-3E&w=640&h=360]
Hola laura, tengo el mismo problema y resulta que bajaron el vídeo de youtube, me puedes decir como lo solucionaste? gracias
Hola: Por desgracia el video ya no esta.
Hola! Yo lo que hice para no complicarme en la visualización con pil fue esto:
from sklearn.tree import plot_tree
y_train = df[«top»]
x_train = df.drop([«top»], axis=1)
Crear Arbol de decision con profundidad = 4
decision_tree = tree.DecisionTreeClassifier(criterion=’entropy’,
min_samples_split=20,
min_samples_leaf=5,
max_depth = 4
class_weight={1:3.5})
decision_tree.fit(x_train, y_train)
plot_tree(
decision_tree = decision_tree,
feature_names = df.drop([«top»], axis=1).columns,
filled = True,
class_names = [‘No Top ‘, ‘Top’]
)
Espero les sirva! Saludos. Y agradecer al autor por este articulo, me sirvio demasiado y estaré atento a futuras publicaciones. Me ha gustado mucho este mundo de machine learning.
Muchas gracias por comentar y ayudar con tu solución!.
Un saludo
Hola como va todo, primero agradecerte por compartir tus conocimientos, soy nuevo en este tema pero cada día me emociona mas, en segundo punto al comprobar el algoritmo me sale este error,
Prediccion: [1]
TypeError Traceback (most recent call last)
in ()
4 print(“Prediccion: ” + str(y_pred))
5 y_proba = decision_tree.predict_proba(x_test.drop([‘top’], axis = 1))
—-> 6 print(“Probabilidad de Acierto: “, str(round(y_proba[0][y_pred]* 100, 2)),”%”)
TypeError: type numpy.ndarray doesn’t define round method
estoy buscando en foros, pero no he podido solucionarlo, puede ser algo sencillo pero te agradezco si tienes la solución, estoy usan google colab por si algo, gracias feliz día
Hola Edar, si no me equivoco esto está solucionado en la Notebook de GitHub. Debes reemplazar la línea con:
print("Probabilidad de Acierto: " + str(round(y_proba[0][y_pred][0]* 100, 2))+"%")
Fíjate que agrega un [0] en y_pred.
Saludos!
Excelente Klaus, ya tenía dolor de cabeza con este error. Fiel testigo que funciona. Gracias!
He buscado “pil” y no aparece en el listado de name, hay alguna otra forma de agregarlo?
Hola Juan Ignacio,
Comencé a seguir tu blog hace un tiempo y me ha gustado mucho. Te agradezco darte el tiempo para compartir tu conocimiento!
Te quería hacer una consulta respecto a los árboles de regresión ¿existe una muestra mínima que permita que los resultados tengan validez para realizar predicciones y evitar el sobreajuste?
Gracias y saludos!
Mario
Hola, Na8
Quisiera decirte que en la parte de “Visualicemos los top y no top de acuerdo a sus fechas en los Charts:”
Hay una parte en la que has puesto un valor a la variable s que creo que no es el correcto, en tu caso tienes lo siguiente:
plt.scatter(f1, f2, c=asignar, s=tamanios)
Pero como me salía un error de que los tamaños no son los mismos, usé asignar2 en ese lugar y me funcionó e incluso la gráfica que obtuve era la misma
Hola! Agradezco enormemente este blog. Tu conocimiento compartido me ayudará mucho para la elaboración de mi tesis. Está todo claro y funciona de maravilla. Lo mejor de todo es que no me aburrí jamás.
Hola Geovanny, jajaja, tu comentario me gustó mucho!! Parte de mi propósito era que los artículos fueran entretenidos, me alegra que no hayan resultado aburridos!
Un saludo!
Hola! Como estas? Gracias por la explicación! Quería hacerte una consulta en la parte que explicas el árbol hablas de dos ramas y que se podrían más. Me podrías explicar cómo poder hacer más de dos ramas en un mismo nodo ?? Gracias !!
Hola Carolina, la verdad que estuve buscando y no encontré implementaciones en Python, habría que hacerlas manualmente. Sin embargo con las soluciones existentes binarias, pueden resolver las problemáticas comunes, haciendo “más split”, es decir, con algo más de altura en el árbol.
¿Para que lo necesitas? si quieres cuéntame y veo cómo puedo ayudarte.
Saludos!
Muchas gracias por compartir tu conocimiento.
Veo que a varios de nosotros nos está generando error cuando se va a graficar el árbol en:
Convertir el archivo .dot a png para poder visualizarlo
check_call([‘dot’,’-Tpng’,r’tree1.dot’,’-o’,r’tree1.png’])
PImage(«tree1.png»)
En lugar de estas dos lineas de código coloqué la siguiente:
tree.plot_tree(decision_tree)
Y con esto ya se grafica !! Espero les sirva.
module ‘seaborn’ has no attribute ‘factorplot’. Did you mean: ‘scatterplot’
El enlace de Jupiter notebook no me funciona: http://data-speaks.luca-d3.com/2018/03/python-para-todos-2-jupyternotebook.html
Posiblemente haya cambiado a https://empresas.blogthinkbig.com/python-para-todos-2-jupyternotebook/
que se llama igual