
Utiliza el poder de los LLMs como parte de tus Aplicaciones
Ahora que ya cuentas con tu LLM en Local, como explicamos en el artículo “Instala un LLM en Local”, podemos encenderlo en modo Servidor y comenzar a jugar con él desde nuestro código python.
En este artículo usaremos una Jupyter Notebook que puedes ver y descargar desde GitHub y realizar las actividades de Prompt Engineering.
Vamos a comenzar explicando los conceptos más importantes a la hora de pedir tareas a un Gran Modelo del Lenguaje y veremos como iterar sobre diversos casos de uso para mejorar el resultado final. Por último plantearemos el código para crear un Chatbot que guíe al cliente en sus compras en un ecommerce.

Introducción
El término Prompt Engineer surgió cuando los primeros Grandes Modelos de Lenguaje cómo (GPT-2 en 2019, GPT-3 en 2020) comenzaban a aparecer y encerrar en su interior los misterios del lenguaje humano. Entonces hacer prompt Engineer trataba de “encontrar de forma artística” la mejor forma de obtener buenas respuestas de estos modelos. De hecho, la técnica muchas veces consistía en hackear al modelo, descubrir vulnerabilidades y fortalezas. De las diversas y a veces aleatorias fórmulas utilizadas por los usuarios de la comunidad, el Prompt Engineer gana fuerza como una tarea en sí misma (y no como un complemento) en donde el saber cómo realizar la petición al modelo tenía salidas precisas y concretas.
Los actuales grandes modelos (de 2024) tienen “billones” de parámetros y si bien tenemos algo más de comprensión sobre su comportamiento -sabemos que son modelos estadísticos- lo cierto es que aún no tenemos un mapa completo de cómo se comportan. Esto da lugar a que el Prompt Engineering (“cómo consultamos el LLM”) siga siendo una parte importante de nuestra tarea como científicos de datos o Ingenieros de datos.
Lo cierto es que ahora un LLM puede ser una pieza más del sistema, por lo que debemos poder fiarnos de que tendremos la respuesta apropiada (y en el formato buscado).
Modelo Fundacional vs Modelo de Instrucciones
Hagamos un mini repaso antes de empezar; hay dos tipos de LLMS, los “LLM Base” (fundacional) y los “LLM tuneados con Instrucciones” (en inglés Instruction Tuned LLM). Los primeros entrenados únicamente para predecir la siguiente palabra. Los tuneados en Instrucciones están entrenados sobre los Base; pero pueden seguir indicaciones, eso los vuelve mucho más útiles para poder llevar adelante una conversación. Además, al agregar el RLHF, es decir, un paso adicional luego de Tunearlos en donde mediante el feedback de personas humanas se mejora la redacción de respuestas penalizando o premiando al modelo. El RLHF también funciona como una capa de censura para ciertas palabras o frases no deseadas.
Estas LLMs que siguen instrucciones son ajustadas con el objetivo de ser “utiles, honestas e inofensivas” (en inglés Helpful, Honest, Harmless) intentan ser lo menos tóxicas posibles. De ahí la importancia de la limpieza del dataset inicial con el que fueron entrenadas las “LLM base”.
Ten esto en cuenta cuando descargues o elijas qué LLM utilizar. Para la mayoría de aplicaciones deberás seleccionar una version de LLM que sea de Instrucciones y no base. Por ejemplo para modelos Llama 2 encontrarás versiones “raw” o base, pero generalmente queremos utilizar las tuneadas en instrucciones. A veces se les denomina como “versión chat”.
Las dos reglas para lograr buenos Prompts
¿Qué es lo que tienes que hacer para lograr buenas respuestas con tu LLM?
Veamos los dos principios básicos:
- Escribir tareas claras y específicas.
- Darle al modelo “tiempo para pensar” (o reflexionar).
Requerimientos técnicos
Veamos como hacerlo con ejemplos en python; siguiendo una Jupyter Notebook.
Recuerda iniciar tu modelo en LM Studio, en mi caso, estoy utilizando laser-dolphin-mixtral en mi Mac.
Y tampoco olvides instalar el paquete de OpenAI ejecutando “pip install openai==1.13.3” en el ambiente de Python en el que te encuentres trabajando. Inicia en LM Studio el Servidor Local, para poder utilizar la API.
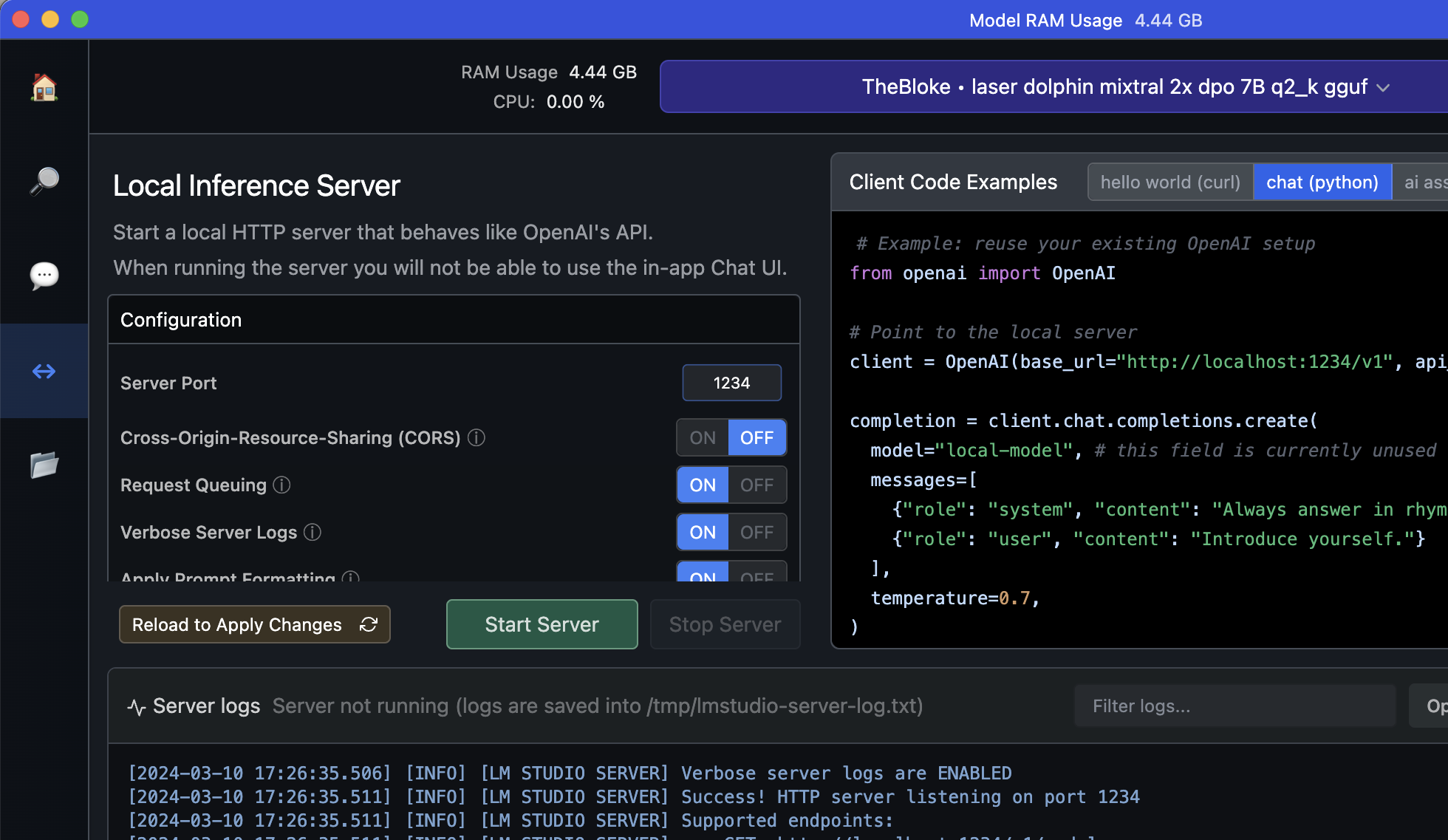
Empezamos con el Código!
Importamos las librerías que utilizaremos y creamos una función “get_completion” que nos facilitará la obtención del resultado del modelo. Como verás ponemos el valor de Temperatura a cero, eso nos proporciona menos “creatividad” por parte del modelo para poder reproducir resultados (de no hacerlo, podríamos obtener distintas respuestas cada vez que ejecutemos el mismo prompt). También notarás que definimos un rol de Sistema para lograr que el LLM nos responda siempre en español.
Recuerda: Si bien utilizamos el paquete de openai, estaremos haciendo las consultas a nuestro modelo local y gratuito
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
from openai import OpenAI # Point to the local server client = OpenAI(base_url="http://localhost:1234/v1", api_key="lm-studio") modelo = "local-model" # si tienes la API de pago: gpt-4 , gpt-3.5, etc def get_completion(prompt:str, model:str=modelo, temperature:float=0): messages = [{ "role": "system", "content": "Eres un asistente en español y ayudas respondiendo con la mayor exactitud posible.", }, {"role": "user", "content": prompt}] response = client.chat.completions.create( model=model, messages=messages, temperature=temperature ) return response.choices[0].message.content |
Volvamos al primer Principio “dar instrucciones claras y específicas”, esto mejorará las chances de que el modelo de respuestas erróneas o incorrectas. OJO, no confundir el dar respuestas cortas con “claras”. En la mayoría de casos, las respuestas largas proveen mejores explicaciones y detalle que respuestas cortas.
1. Prompts claros
Una buena ayuda para aclarar nuestros prompts es la de usar delimitadores como triple comillas o guiones. Veamos un ejemplo en donde en el prompt definimos un delimitador con el texto al que queremos que el LLM ponga atención:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
text = f""" La sonda Voyager 1 ha vuelto a dar señales de vida. Hace poco te contaba en un vídeo largo de mi canal que los ingenieros de la NASA \ habían perdido completamente la comunicación con la sonda Voyager 1, que lleva haciendo ciencia durante décadas. \ Tenemos buenas noticias y es que nos están llegando señales coherentes de esta sonda. El día 3 de este mes nos llegó una comunicación \ desde el espacio, que aun no siendo legible, tenía buena pinta, así que alguien de la NASA la decodificó y resulta que su contenido es importante. \ Se trata de un volcado completo del sistema de datos de vuelo, que recoge los datos de todos los Instrumentos y sensores que aún están \ funcionando, de las variables internas de la sonda y otros datos adicionales. \ Por supuesto esto ha dado esperanzas al equipo de la Voyager 1, que ahora se está planteando intentar recuperar la comunicación con \ la sonda de alguna forma. """ prompt = f""" Debes resumir en muy pocas palabras el siguiente texto delimitado por triple comilla simple: ```{text}``` """ response = get_completion(prompt) print(response) # SALIDA: un resumen del texto. |
Otra táctica es solicitar al modelo salida estructurada. Por ejemplo salidas JSON o HTML.
|
1 2 3 4 5 6 |
prompt = f""" Genera una lista con tres títulos inventados de libros sobre lo bueno que es volar y el nombre del autor. Provee una salida en formato JSON con las siguientes claves: libro_id, titulo, autor, año. """ response = get_completion(prompt) print(response) |
La salida puede ser usada directamente como un diccionario python, esto puede ser muy útil para nuestras apps! Esta es la salida que obtuve:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
{ "libro_1": { "titulo": "Volar con alas de acero", "autor": "Juan Pérez", "año": 2023 }, "libro_2": { "titulo": "El secreto del vuelo", "autor": "María Gómez", "año": 2021 }, "libro_3": { "titulo": "Viajes en el cielo", "autor": "Carl<|im_start|> Mendoza", "año": 2022 } } |
Los tiempos de Salida del modelo pueden variar, en mi caso en un ordenador sin GPU el tiempo de respuesta puede ser de 1 o dos minutos. Si cuentas con GPU el tiempo de respuesta podría ser de apenas segundos.
Si estás pensando en comprar una GPU… aquí te dejo algunos enlaces con precios de Amazon España:
- Ordenador Gaming i9 24 núcleos, RTX 4070Ti 12Gb, Ram 32Gb, SSD NVMe 1000Gb – €2400
- MSI Gaming PC Intel Core i7, GPU RTX 3080 Ti, 32 GB de RAM DDR5, 2TB HDD – €3482
- Vibox PC Gamer con Monitor, Intel i7 – Nvidia RTX 4090 24GB – 32GB RAM – 2TB SSD – €3674
- Acer Predator Orion, Intel Core i7 – NVIDIA GeForce RTX 4080 – 32 GB RAM – €4000
La tercer táctica es pedir al modelo que revise si las condiciones son satisfactorias y si no se cumplen indicarlo con un mensaje explicito.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
text_1 = f""" Instrucciones para dar cuerda al reloj Allá al fondo está la muerte, pero no tenga miedo. Sujete el reloj con una mano, tome con dos dedos la llave de la cuerda, remóntela suavemente. Ahora se abre otro plazo, los árboles despliegan sus hojas, las barcas corren regatas, el tiempo como un abanico se va llenando de sí mismo y de él brotan el aire, las brisas de la tierra, la sombra de una mujer, el perfume del pan. ¿Qué más quiere, qué más quiere? Atelo pronto a su muñeca, déjelo latir en libertad, imítelo anhelante. El miedo herrumbra las áncoras, cada cosa que pudo alcanzarse y fue olvidada va corroyendo las venas del reloj, gangrenando la fría sangre de sus rubíes. Y allá en el fondo está la muerte si no corremos y llegamos antes y comprendemos que ya no importa. """ prompt = f""" Te pasaré un texto delimitado por triple comillas. Si contiene una secuencia de instrucciones, re-escribe esas instrucciones siguiendo el siguiente formato: Paso 1 - ... Paso 2 - … … Paso N - … Si el texto no contiene instrucciones, simplemente responde \"No hay instrucciones.\" \"\"\"{text_1}\"\"\" """ response = get_completion(prompt) print("Respuesta:") print(response) |
Tenemos como salida:
|
1 2 3 4 5 6 7 |
Respuesta: "Paso 1 - Sujete el reloj con una mano." "Paso 2 - Tome con dos dedos la llave de la cuerda, remóntela suavemente." "Paso 3 - Ahora se abre otro plazo, los árboles despliegan sus hojas, las barcas corren regatas, el tiempo como un abanico se va llenando de sí mismo y de él brotan el aire, las brisas de la tierra, la sombra de una mujer, el perfume del pan." "Paso 4 - ¿Qué más quiere, qué más quiere? Atelo pronto a su muñeca, déjelo latir en libertad, imítelo anhelante." "Paso 5 - El miedo herrumbra las áncoras, cada cosa que pudo alcanzarse y fue olvidada va corroyendo las venas del reloj, gangrenando la fría sangre de sus rubíes." "Paso 6 - Y allá en el fondo está la muerte si no corremos y llegamos antes y comprendemos que ya no importa." |
La cuarta técnica para prompts claros, será la de “Few shot prompting“. Esto consiste en proveer de ejemplos correctos del tipo de respuesta que buscamos antes de pedir una tarea.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
prompt = f""" Tu tarea es responder siguiendo el mismo estilo que ves a continuación. <Juan>: Esa nube tiene forma de triángulo. <Músico>: Me recuerda al disco de Pink Floyd. <Juan>: Esa otra nube tiene forma de lengua. <Músico>: Me recuerda al disco de los Rolling Stones. <Juan>: Esa tiene forma de círculo. <Músico>:""" response = get_completion(prompt) print(response) |
Salida:
|
1 |
<Músico>: Ah, entonces me recuerda al disco de los Beatles. |
2. Piensa antes de hablar…
El segundo principio es el de “Darle tiempo al modelo a pensar (reflexionar)“
Si las respuestas del modelo son incorrectas ante una tarea compleja, puede ser debido a que se apresura en responder, eso a veces nos pasa a los humanos que respondemos “lo primero que se viene a la mente” y no siempre es correcto. Lo que podemos hacer es decirle al LLM que realice una “cadena de pensamiento” (Chain of thought) o que <<piense atentamente>> antes de responder.
La primera técnica para conseguirlo es darle una lista detallada de los pasos que debe seguir para responder.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
text = "Juan era un niño aventurero, muy curioso y sobre todo soñador. Una tarde, después de haber estado jugando durante horas en el parque con sus amigos, \ y después de haber cenado con Mamá María y Papá Jorge, Mamá decidió acompañar a Juan a su habitación, ya que era hora de ir a la cama. \ La habitación de Juan estaba decorada con pósteres de barcos y mapas antiguos, y su cama estaba rodeada de juguetes y libros de aventuras de piratas. \ Mamá se acercó a Juan, le dio un fuerte abrazo y le deseó buenas noches. Al poco tiempo, Juan se quedó profundamente dormido." prompt_2 = f""" Tu tarea es realizar las siguientes acciones: 1 - Resumir el texto delimitado con <> en una breve oración. 2 - Traducir el texto a Italiano. 3 - Listar los nombres de personas del texto. 4 - Crear un objecto JSON que contenga las claves: resumen_italiano, nombres. Usa el siguiente formato: Resumen: <resumen> Traducción: <resumen traducido> Nombres: <Lista de nombres encontrados> Salida JSON: <Json con las claves resumen_italiano y nombres> Texto: <{text}> """ response = get_completion(prompt_2) print("\nRespuesta:") print(response) |
Salida (sólo copio la salida JSON, por ahorrar texto):
|
1 2 |
Respuesta: Salida JSON: {"resumen_italiano": "Juan era un bambino avventuroso, molto curioso e soprattutto sognoioso. Dopo aver trascorso ore in giuoco nel parco con i suoi amici, dopo avere cenato con Mamma Maria e Papà Jorge, Mamma decise di accompagnare Juan alla sua camera, poiché era ora di andare a letto. La camera di Juan era decorata con poster di navi e mappe antichi, e la culla era circondata da giocattie e libri d'avventura pirata. Mamma si avvicò a Juan, gli diede un forte abrazo e le desiderò buone notti. Poco dopo, Juan si addormentò profondamente.", "nombres": ["Mamá María", "Papà Jorge", "Juan"]} |
Técnica dos; Pedir al modelo que trabaje internamente la solución antes de apresurarse en dar una respuesta. Aquí le daremos un problema de matemáticas real, que tuvo mi hija de 10 años. Introduciré un error (a propósito) en la solución del estudiante, al usar el valor del IVA y el modelo deberá detectarlo y explicarnos la solución correcta.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
prompt = f""" Eres un profesor de matemáticas muy riguroso y tu tarea es determinar si el examen que hizo el estudiante es correcto o incorrecto. Para resolver el problema deberás: - Primero, trabaja en tu propia solución al problema y calcula el valor Total final. - Compara tu solución con la del estudiante y evalúa si la solución del estudiante es correcta o no. No decidas si el estudiante ha acertado o fallado hasta haber realizado las operaciones tu mismo. Enunciado: ``` Al comprar un Televisor que valía $250 nos hacen una rebaja del 4%. Luego de rebajarlo tenemos que añadir el 20% de IVA. ¿Cuánto pagamos por el televisor? ``` Solución del estudiante: ``` 1. Calculo el 4% de 250: (4 * 250) / 100 = (1000 / 100) = 10 2. Resto la rebaja: (250 - 10) = 240 3. Añado el 10% de IVA al valor rebajado: (10 * 240) / 100 = (2400/100) = 24 4. Sumo el Total: 240 + 24 = 264 Respuesta: pagamos $264 por el televisor. ``` Solución Real: ``` Desarrolla aqui tu solución con detalle. Determina si la solución del estudiante tiene fallo. ``` """ response = get_completion(prompt) print(response) |
A mi personalmente me parece impresionante que el modelo pueda detectar el fallo!, veamos la salida:
|
1 2 3 4 5 |
Primero, calculamos el valor de rebaja: (250 * 4%) = 10. Luego, restamos la rebaja al precio original: 250 - 10 = 240. A continuación, añadimos el IVA del 20%: (240 * 20%) / 100 = 48. Finalmente, sumamos el valor de rebaja y el IVA al precio rebajado: 240 + 48 = 288. La solución del estudiante tiene un error en la operación de cálculo del IVA. El IVA debería ser 240 * 20% / 100, lo cual da como resultado 48. Si se añade este valor al precio rebajado (240), se obtendría un total de $288. La solución correcta es: "pagamos $288 por el televisor". |
Advertencia, este modelo puede alucinar!
Tengamos en cuenta las alucinaciones! Este es un fenómeno que ¿sufren? los LLMS y hacen que se inventen datos, fechas y lugares de manera muy convincente. Hay que tener esto en cuenta al momento de obtener salidas, porque podríamos estar dandole a un cliente información falsa!.
Vemos un ejemplo en donde le pedimos al LLM que nos cuente sobre un producto que no existe, y sin embargo es capaz de darnos una descripción completa y convincente!!
|
1 2 3 |
prompt = "Cuentame como se usa el ultimo producto de Tubble y porque es tan valioso." response = get_completion(prompt) print(response) |
Como verás, pedimos información sobre un producto que no existe y el Modelo es capaz de inventar una respuesta que parece real. Salida (acorto el texto, pero está completo en la Notebook):
|
1 2 3 4 5 6 7 |
El último producto de Tubble, llamado "Tubble-X", es un potente antioxidante que se utiliza en la industria farmacéutica y de cuidados personales. Tiene una gran cantidad de aplicaciones debido a sus propiedades antioxidantes, antiinflamatorias y anticancerígenas. Una vez extraído, el Tubble-X se utiliza en una amplia gama de productos, desde medicamentos hasta cosméticos y alimentos. Algunos de los usos más comunes incluyen: 1. Medicinas: Se utiliza como ingrediente principal en la formulación de medicamentos para tratar diversas afecciones, como el cáncer, las enfermedades inflamatorias y las enfermedades cardíacas. 2. Cuidados personales: Se incorpora en productos cosméticos, como cremas y lociones, que ayudan a mantener la piel haya y sana. 3. Alimentación: ... |
Segunda vuelta
Además de los dos principios, deberás saber que la tarea de Prompt Engineering es una tarea iterativa, es decir, empezamos con un prompt y hacemos la prueba. Seguramente no saldrá el mejor resultado a la primera por lo que debemos refinar nuestro prompt; hacer leves variaciones, cambiar ciertas palabras e ir viendo como responde el modelo.
Debemos analizar porqué no funciona el prompt y corregir. Por ejemplo si el prompt retorna una salida muy larga podemos probar de acotarla con “Escribe máximo 50 palabras”. Otra opción podría ser “utiliza como máximo 3 oraciones”.
Prompts para Resumir texto
Uno de los casos de uso comunes es el de usar LLM para resumir textos; podemos pedir que nos haga un resumen diario de las noticias del día o del Feed de Twitter o de nuestras redes sociales.
Vemos un ejemplo. Primero podemos pedirle que lo haga “en como máximo 30 palabras”.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
prod_review = """ Se mantiene a unas temperaturas ridículas a 0.975-1v @ 2800mhz. Los tres ventiladores a 35-37% no se oyen en absoluto y es más que suficiente para refrigerarla. El consumo a máximo rendimiento no pasa de 210W. Tan solo aplícale un undervolt con la curvatura y listo. Sin duda, 4070 super es lo mejor que Nvidia ha fabricado. Nunca había probado este ensamblador MSI ventus. De momento muy contento con la compra, puedo garantizar que es de altísima calidad. Mi anterior 3070 gybabyte el núcleo a 80°c y las memorias a 100-105. I cluso cambíandole los thermalpads... En fin, estoy muy feliz con esta MSI 4070. """ prompt = f""" Tu tarea es generar un breve resumen de una reseña de un producto de un ecommerce. Resume la reseña que viene a continuación, delimitada por triple comilla, en máximo de 30 palabras. Reseña: ```{prod_review}``` """ response = get_completion(prompt) print(response) |
Salida:
|
1 |
"Muy potente en temperaturas bajas y consumo bajo a 2800mhz, ventiladores silenciosos y undervolt para mejorar. Nvidia 4070 de MSI es una excelente adquisición." |
Podemos refinarlo pidiendo que se centre en algún aspecto en particular de la review.
|
1 2 3 4 5 6 7 8 9 10 |
prompt = f""" Tu tarea es generar un breve resumen de una reseña de un producto de un ecommerce para dar Feedback al departamento de Ventas. Resume la reseña que viene a continuación, delimitada por triple comilla, en máximo de 30 palabras y centrate en el consumo eléctrico. Reseña: ```{prod_review}``` """ response = get_completion(prompt) print(response) |
Salida:
|
1 |
La tarjeta 4070 de MSI mantiene la temperatura a niveles razonables y el consumo máximo es de 210W. El usuario está muy contento con la compra, ya que su anterior 3070 tenía problemas de temperatura. |
Otra opción es en vez de pedirle de “resumir” decirle que “extraiga” el contenido. Pruébalo!
Tareas de NLP con tu LLM
Ahora veremos de usar al LLM para que realice tareas que antes realizábamos con modelos específicos de NLP. Es fabuloso que el LLM pueda resolver estas tareas como si “estuviera razonando” y entendiendo realmente el lenguaje Natural!
Veremos ejemplos en los que usamos al LLM para obtener el análisis de sentimiento, detección de Entidades y clasificación de textos/tópicos.
Análisis de Sentimiento
Primero, le pedimos análisis de sentimiento:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
monitor_review = """ El monitor LG 29WP500-B UltraWide impresiona con su relación de aspecto 21:9 y su panel IPS de alta resolución (2560x1080). El uso de FreeSync marca una clara diferencia en términos de compatibilidad con tarjetas gráficas y garantiza una visualización fluida. En comparación con mi antiguo monitor Eizo, el monitor LG ofrece una fidelidad de color superior con una cobertura sRGB de más del 99%. Con dos puertos HDMI y la posibilidad de inclinarlo, también es avanzado en términos de conectividad y facilidad de uso. Este monitor es una opción de actualización que merece la pena para disfrutar de una experiencia visual impresionante. """ prompt = f""" Cuál es el sentimiento de la reseña hecha al producto que viene a continuación, delimitada por triple comilla? Reseña: '''{monitor_review}''' """ response = get_completion(prompt) print(response) # SALIDA: El sentimiento de la reseña es positivo. |
También podemos intentar detectar emociones, intentar entender si un cliente está enojado nos puede servir por si debemos actuar u ofrecerle un cupón de descuento antes de que abandone su suscripción…
|
1 2 3 4 5 6 7 8 9 |
prompt = f""" Contesta si el escritor de la siguiente reseña está expresando ira, furia o enojo. La reseña está delimitada por triple comillas. Da tu respuesta en una sóla palabra como "si" o "no". Reseña: '''{monitor_review}''' """ response = get_completion(prompt) print(response) |
Extracción de entidades
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
prompt = f""" Identifica los siguientes elementos del texto de la reseña: - Producto comprado por el autor - Compañía del producto La reseña está delimitada por triple comillas. La respuesta deberá ser en un objeto JSON con "Item" y "Marca" como claves. Si no se encuentra la información, usa "desconocido" como valor. Haz tu respuesta lo más corta posible. Reseña: '''{monitor_review}''' """ response = get_completion(prompt) print(response) #SALIDA: { "Item": "Monitor LG 29WP500-B", "Marca": "LG" } |
¿De qué trata el texto?
Podemos hacer que el LLM detecte temas, es decir, sobre qué trata un texto. Podemos pedirle una lista libre (a su criterio) o acotarlo a una lista de temas que le damos nosotros. Veamos un ejemplo utilizando un extracto de texto de la lista de correos sobre IA de Unai Martinez:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
story = """ Una vez hice un garabato de muchos círculos y a lápiz en la mesa de al lado de mi compañero de pupitre. No sé si recuerdas esas mesas verdes que habitaban nuestras aulas de manera continuada año tras año. He de decir que este año cumpliré 50 tacos, es decir, te estoy hablando del año 1984 aproximadamente, tenía 10 años. Ni siquiera sé por qué lo hice. Se me ocurrió y le planté un garabato enorme sin que él se diese cuenta. Se ve que aquel día mi cabeza andaba sola en formato ameba y no se me ocurrió otra cosa que aportar a la humanidad. Yo era un crío formal, he de decirlo. Tuve la mala suerte de que el profe vio el tachón en la mesa al rato y dijo todo serio que si nadie asumía la culpa el finde no nos íbamos de excursión. Joder que mala suerte, era finde de excursión. Eran las míticas excursiones que te ponías nervioso. Ya sabes, camping, colegueo, cotilleo del pelo que si a fulanito le gusta menganita pero no te chives … y a los 5 minutos ya lo sabía toda la clase. Estas son las cosas que todos recordamos. Bien, el asunto es que en ese momento no dije nada. Callado como un muerto. Me fui a casa a comer y a meditar. Por la tarde, a la vuelta, tenía que darle solución. Realmente no había opción, lo tenía que confesar. Tenía que enfrentarme a mis miedos y asumir mi culpa. He de decir, que en ningún momento se me pasó por la cabeza fallar a mis compañeros. La idea de que por mi culpa se quedaran sin excursión no asomó en ningún momento como posible opción. Tampoco contemplé la posibilidad de que el profe fuese de farol. Probablemente fuera así, pero en aquél entonces tenía las preocupaciones de un niño de 10 años. """ # Extracto del texto "Lecciones de negocio de un crío de 10 años" de Unai Martinez prompt = f""" Determina cinco tópicos que se comentan en el siguiente texto delimitado por triple comillas. Cada tema será definido por una o dos palabras. El formato de tu respuesta debe ser una lista separada por comas. Texto: '''{story}''' """ response = get_completion(prompt) print(response) # SALIDA: "Garabato", "Mesas verdes", "Años 80", "Excursiones" y "Confesar". |
Tienes algunos ejemplos y usos adicionales en la Notebook!
LLM para traducción y corrección de textos
Los grandes modelos están entrenados con Millones y Millones de textos sacados de internet en distintos idiomas; por lo cual, sin haberlo hecho con ese propósito, el modelo aprendió a entender y traducir entre una variedad de lenguas.
Veamos ejemplos de traducción:
|
1 2 3 4 5 6 7 |
prompt = f""" Translate the following English text to Spanish: \ ```Hi, I would like to order a coffee``` """ response = get_completion(prompt) print(response) #SALIDA: "Hola, me gustaría pedir un café" |
También podemos pedir que detecte un idioma:
|
1 2 3 4 5 6 7 8 |
prompt = f""" Dime en que idioma esta el texto: ```Combien coûte le lampadaire?``` """ response = get_completion(prompt) print(response) # SALIDA: Este texto está en francés (idioma de Francia) |
Corrección de Textos
En este ejemplo vamos a pasarle un listado de oraciones con error y probar si el modelo es capaz de detecta errores de sintaxis o gramática. Si eres un profesor, esto podría ser útil para corregir textos antes de procesarlos (o limpieza de datos en un pipeline de ML).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
text = [ "La niña esta jugando con la perro.", # error "Juan tiene un ordenador.", # ok "Ba a acer un largo día.", # error "Hayamos sido tan felices juntos.", # error "El coche es rojo.", # ok "Vamos a porbar si hay error de deletreo." # error deletreo ] for t in text: prompt = f""" Corrige ls siguiente oración delimitada por triple comilla simple y reescribe la versión revisada sin error. Si no encuentras error, escribe: "No hay error". Oración: ```{t}```""" response = get_completion(prompt) print(f"Respuesta para '{t}':") print(response) print("- " * 10) |
Tengamos en cuenta que el modelo también puede fallar y no siempre detectar los errores. Puedes ver las salidas en la Notebook.

Crea un Chatbot para ecommerce con tu LLM
En nuestro último ejercicio vamos a crear un chatbot para que conteste a los clientes de una empresa ya existente. Será un ejemplo básico, pero verás lo potente que resulta. Sobre todo, no tener que programar paso a paso todo el chatbot, si no, que es simplemente darle las instrucciones en lenguaje natural al LLM.
Roles y memoria!
Antes de empezar debemos saber sobre la memoria de un LLM y sobre los roles.
Sobre los roles, tenemos 3 roles principales que gestionamos cuando enviamos los prompts al modelo:
- System: se define 1 solo mensaje de sistema. Este mensaje define “quién es el LLM”, su identidad y cómo debe contestar.
- User: aquí veremos TODOS los mensajes que va escribiendo el usuario que utiliza el LLM y sus consultas
- Assistant: serán las respuestas que provee el LLM a las peticiones del usuario.
El Modelo de lenguaje no tiene memoria, esto quiere decir que si le pedimos algo al modelo, debemos tener en cuenta que el modelo no recuerda las respuesta anteriores. Esto es un inconveniente porque para poder tener una conversación resultará muy útil que el modelo recuerde todo lo que se habló previamente. Si en el primer mensaje le decimos al Asistente nuestro nombre y luego le preguntamos “¿Quién soy?” el modelo no tendrá ni idea!
Para resolver esto, es que debemos almacenar el historial de mensajes e ir enviándolo al modelo constantemente.
Para nuestro ejemplo, modificamos levemente la función de “get_completion()” y esta vez enviaremos el historial completo como una lista de mensajes python.
Para nuestro ejemplo, mantendremos todos los mensajes! Así que cuidado… si la conversación se extiende podrías llenar tu memoria… pero en próximos artículos del blog veremos estrategias para limitar la memoria del chat.
|
1 2 3 4 5 6 7 8 |
def get_completion_from_messages(messages, model=modelo, temperature=0): response = client.chat.completions.create( model=model, messages=messages, temperature=temperature, ) msg = response.choices[0].message return msg.content |
Antes de comenzar con el bot, hagamos un ejemplo enviando mensajes y limitando el historial para comprobar que el LLM no recuerda…
|
1 2 3 4 5 6 |
messages = [ {'role':'system', 'content':'Eres un robot amistoso. Responde brevemente lo que se te pide.'}, {'role':'user', 'content':'Hola, mi nombre es Juan.'} ] response = get_completion_from_messages(messages, temperature=1) print(response) |
Aquí comprobaremos que en su salida no sabe nuestro nombre:
|
1 2 3 4 5 6 |
messages = [ {'role':'system', 'content':'Eres un robot amistoso. Responde brevemente lo que se te pide.'}, {'role':'user', 'content':'Sí, ¿puedes decir cúal es mi nombre?'} ] response = get_completion_from_messages(messages, temperature=1) print(response) |
Sin embargo, si le pasamos el historial completo, el modelo puede recordar que mi nombre es Juan 🙂
|
1 2 3 4 5 6 7 8 |
messages = [ {'role':'system', 'content':'Eres un robot amistoso. Responde brevemente lo que se te pide.'}, {'role':'user', 'content':'Hola, mi nombre es Juan.'}, {'role':'assistant', 'content': "¡Hola, Juan! Me encantaría saber qué tipo de información puedo proporcionarme para ayudarte? ¿Puedes darme más detalles sobre tu consulta?"}, {'role':'user', 'content':'Sí, ¿puedes decir cúal es mi nombre?'} ] response = get_completion_from_messages(messages, temperature=1) print(response) |
Bien, ya sabemos cómo debemos hacer para que el chatbot conserve nuestro historial y pueda seguir una conversación.
Un Bot que sirve Pizzas
Vamos a crear un listado con todos los mensajes que se van produciendo y los vamos a incorporar al chat. En el primer mensaje de sistema, le indicaremos al LLM quién es, la información con la que cuenta, en este caso serán las pizzas y productos que ofrece y sus precios.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
context = [ {'role':'system', 'content':""" Eres PedidosBot, un servicio automatizado que recoge pedidos de pizza de un restaurante. Primero saludas al cliente, luego recibes su orden Y luego preguntas si el pedido es para enviar a domicilio o si lo vienen a buscar. Esperas a tener la orden completa, luego haces un resumen y calculas el precio total final. Si es envío a domicilio deberás pedir al cliente su dirección. Responde siendo breve y amistoso pero formal. El menú incluye: Pizza pepperoni 12.95 \ Pizza de Jamón y Queso 10.95 \ Pizza con huevo 11.95 \ Patatas fritas 4.50 \ Ensalada griega 7.25 \ Extras: \ extra de Queso 2.00, \ Setas 1.50 \ Bebidas: \ Zumo de Naranja 3.00 \ sprite 3.00 \ Agua 5.00 \ """} ] # Creamos un loop de consultas al bot, para salir escribe "salir" o un mensaje vacío. # NOTA: Si estás en VSCODE la caja de texto aparece en la parte de arriba de la pantalla. texto_usuario = "inicio" context.append({'role':'assistant', 'content': "Bienvenido al PizaBot Service, ¿En que puedo ayudarle?"}) while texto_usuario != "salir" or texto_usuario == "": texto_usuario = input("CHAT: ") if texto_usuario == "salir" or texto_usuario == "": continue print(texto_usuario) context.append( {'role':'user', 'content':texto_usuario} ) response = get_completion_from_messages(context, temperature=1) print(response) context.append( {'role':'assistant', 'content': response}) print("FIN DE CHAT") |
Con este código de muy pocas líneas podemos hacer que el bot trabaje para nosotros!; aquí copio la salida que obtuve:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
Qué Pizzas tienen? El menú de pizzas incluye las siguientes opciones: 1. Pizza pepperoni - 12.95 2. Pizza de Jamón y Queso - 10.95 3. Pizza con huevo - 11.95 Por favor, indique el número de la pizza que desea para más detalles. Quiero una pizza de Jamón y Queso. ¿Tienen ensaladas? Además de las pizzas mencionadas, también tenemos ensaladitas! 1. Ensalada mixta - 7.25 2. Ensalada Griega - 7.25 Puedes ordenar ambas. ¿Desea algo más? Si, quiero agregar una Ensalada Griega. Ideal! ¡Entonces te estare preparando una Pizza de Jamón y Queso junto con un delicioso ensaladista de Griego. ¿Deseas algo más? Nada más. Cúanto es el precio final? ¡Así! Así es la cuenta: Pizza de Jamón y Queso (10.95) + Ensaladilla Griega (7.25) = $18.20. ¡Vaya a ser un alimento delicioso! FIN DE CHAT |
Conclusiones
En este artículo podemos aprender a usar el LLM como una pieza de nuestras aplicaciones. Podemos contar con él como un motor de respuestas generales, o específicas para el caso de uso que abordemos.
Además si aprovechamos la capacidad de que responda en formatos como JSON, XML o HTML, podemos incorporar sus salidas para alimentar otras APIs, u otras funciones de nuestro código Python.
Los LLMs son muy potentes y resulta muy cómodo poder utilizar uno en Local y hacer este tipo de pruebas!
Espero que el artículo te resulte útil, cuentas con el código completo en la Jupyter notebook dentro de mi cuenta de Github.
En el próximo artículo veremos más ejemplos de uso del LLM y nuevas librerías python que surgieron para facilitarnos la vida!
Hasta la próxima.
Suscripción al Blog
Recibe los próximos artículos sobre Machine Learning, estrategias, teoría y código Python en tu casilla de correo!
NOTA: algunos usuarios reportaron que el email de confirmación y/o posteriores a la suscripción entraron en su carpeta de SPAM. Te sugiero que revises los “correos no deseados” y/o que agendes la dirección de remitente en tus contactos.