
Puedes instalar Llama 2, Claude, Mistral, Falcon, StableLM ó cualquier otro LLM en tu computadora para ejecutar proyectos en Local. Tu propio ChatGPT privado. En este artículo te explicaremos cómo hacerlo paso a paso.
En pocos minutos podrás tener instalado un Gran Modelo de Lenguaje en tu ordenador y podrás chatear con él, pedir que escriba tus correos, sugerir ideas, consultas legales y hasta aprovecharlo como un servidor en local y que provea de valor a tus aplicaciones. Todo gracias al software libre LM Studio.

Los grandes modelos de Lenguaje (LLMs) se convirtieron en un asistente indispensable para trabajar, para resolver dudas, para programar y hasta para reemplazar al buscador. Hay quienes lo utilizan a diario y lo cuentan como una herramienta indispensable como un lápiz, el Excel o StackOverflow.
Seguramente conozcas ChatGPT que se popularizó a finales de 2022 y tomó gran relevancia con sus modelo GPT4 ya en 2023. A partir de ese momento surgieron muchos otros modelos GPT como Llama de Meta, Claude, Mistral, Gemini de Google ó Falcon. Muchos de ellos Open Source y/o con licencias de uso comercial.
Algunos también ofrecen la posibilidad de uso en la nube para probarlos, pero también tenemos la opción de descargarlos desde HuggingFace y correrlos en local.
Ventajas de tener un LLM en local
¿Por qué querríamos ejecutar un LLM en local?
- Primero que nada, para experimentar libremente! es genial poder tener un LLM en tu ordenador y jugar a diario con él 24hs, sin necesidad de conexión a internet.
- Todas las consultas que hagas serán tuyas, privadas, no compartirás datos en la nube ni con terceros.
- Gratuito!, no tienes un límite de tokens ó consultas diarias. Puedes hacer uso extensivo. Si utilizas el servicio de OpenAI, sabes que es de Pago y hay servicios en la nube como Azure o AWS que ofrecen modelos pero que también deberás pagar por uso.
- Para tus propios proyectos: puedes empezar a crear apps que hagan uso de tu LLM local por ejemplo para que retorne archivos JSON con análisis de sentimiento, resumen, clasificación, (tareas de PLN) y finalmente “hacerte millonario”
¿Qué Hardware necesito para correr un LLM en local?
Requerimientos:
Disco
Los Grandes Modelos de Lenguaje son modelos con Miles de Millones (Billion en inglés) de parámetros; esto hace que sean muy pesados. Los modelos actuales publicados por Google, META, etc suelen lanzar versiones Small, Medium y Large de 7B, 40B y 70B respectivamente. Los tamaños de esos modelos son de decenas de Gigabytes, lo cual no sería gran problema, porque la mayoría de ordenadores cuentan con discos duros de Terabytes. El problema está en la memoria RAM.
Memoria RAM
Como recordarás; las redes neuronales son capas de neuronas que se interconectan para formar una matriz que “realiza multiplicaciones” por lo tanto esos tensores deben estar cargados en Memoria para poder operar. Los ordenadores actuales suelen contar RAM de 8GB, 16GB o con 32Gb, por lo que si un modelo es de 40 GB no podremos cargarlo completo en memoria.
Por suerte la comunidad OpenSource ha salido con diversas estrategias para poder reducir el tamaño de los modelos LLM sin afectar sus resultados (ó haciendo muy levemente).
Por ejemplo, un truco reside en utilizar menor precisión en el valor de los pesos de la red. Es decir, si por ejemplo una neurona artificial tiene un valor 3,141516 lo podríamos truncar a 3,141 y con ello reducimos el espacio que ocupan sus decimales en las 7 mil millones de neuronas “a la mitad”. Un modelo de 40Gygas ahora ocupa 20Gygas. Hay otras técnicas como cargar parcialmente la red en memoria RAM y Disco.
Velocidad: CPU y GPU
¿Y en cuanto a la velocidad? ¿Necesito una GPU?
Obviamente si contamos con GPU los tiempos de respuesta serán veloces. Con un modelo mediano, buena RAM y GPU podemos escribir un prompt y al apretar la tecla “Intro” veremos de inmediato cómo se va escribiendo la respuesta a 15 tokens por segundo.
Si usamos un CPU con procesador potente y un modelo pequeño, puede que tengamos una velocidad de decente, deberemos tener mayor paciencia para leer la respuesta completa. Las pruebas que he hecho funcionaron bastante bien.

GPU o no GPU, esa es la cuestión
No es necesario contar con GPU para hacer pruebas caseras en los modelos pequeños de 7B Parámetros con tu CPU normal debería alcanzar. Si estás pensando en comprar un ordenador con GPU, te dejo estos enlaces (afiliado) de Amazon España con las opciones que he encontrado disponibles (precios marzo 2024) y con los que podrás ejecutar modelos medianos de unos 40B:
- Ordenador Gaming i9 24 núcleos, RTX 4070Ti 12Gb, Ram 32Gb, SSD NVMe 1000Gb – €2400
- MSI Gaming PC Intel Core i7, GPU RTX 3080 Ti, 32 GB de RAM DDR5, 2TB HDD – €3482
- Vibox PC Gamer con Monitor, Intel i7 – Nvidia RTX 4090 24GB – 32GB RAM – 2TB SSD – €3674
- Acer Predator Orion, Intel Core i7 – NVIDIA GeForce RTX 4080 – 32 GB RAM – €4000
Una breve comparación de precios a tener en cuenta (Marzo 2024):
- Si utilizas la API de OpenAI con GPT 4-turbo, te costará €40.- por millón de Tokens de entrada y salida.
- La API de Mistral en su modelo más potente (70B) costará €27.- por Millón de Tokens de entrada y salida.
- Si utilizas Llama 2 en la nube con Azure te costará €1000.- al mes si lo tienes encendido 8hs/20 días (ilimitado de tokens).
- Si te compras un ordenador con GPU por €2400.- podrás utilizarlo con tokens ilimitados las 24 horas del día!
NOTA: Recuerda que tienes que sumar el coste de electricidad. Las tarjetas NVIDIA pueden consumir más de 200W, por lo que dependiendo de tu país, día de la semana y hora del día puedes tener un coste adicional elevado. Evalúa bien el uso que le darás a tu tarjeta y si te conviene comprar una o utilizar un servicio en la nube.
NOTA2: Ten en cuenta que mi recomendación no es para ambientes productivos con una alta demanda.
Instalar LMStudio en tu ordenador
Vamos a ello! Utilizaremos LM Studio, un software gratuito que podemos descargar desde aquí. Esta es su página web.
Elige la versión para Windows, Mac ó Linux, descarga y luego instala en tu ordenador.
Este programa nos permitirá elegir modelos compatibles con nuestro ordenador y luego ejecutarlos.
Una vez instalado, lo abrimos y vemos la barra de buscador que nos posibilita buscar modelos dentro de toda la base de HuggingFace.
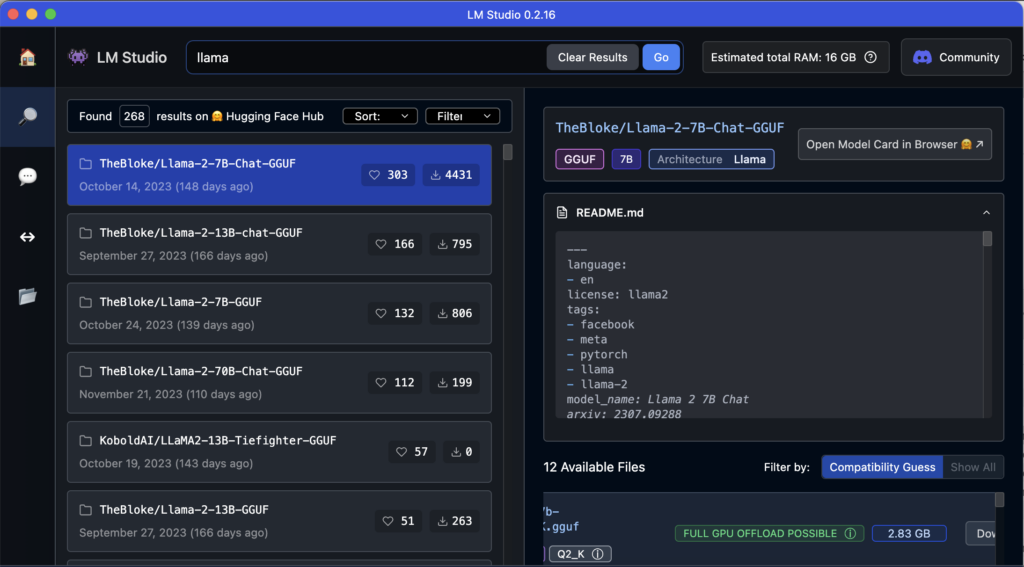
Descarga tu LLM favorito!
Los modelos que te recomiendo para empezar, dependiendo de tu ordenador son:
Si tienes CPU y 8G RAM
- Modelo de Google lmstudio-ai gemma-2b-it-GGUF – 2.6 GB
Si tienes CPU y +16G RAM
- Modelo TheBloke laser-dolphin-mixtral – 4.7 GB
Si tienes GPU y 16G RAM (ó Mac con M1/M2)
- Modelo ecastera eva-mistral-7b-spanish-GGUF – 7.7 GB
Si tienes GPU y 32G RAM
- Modelo TheBloke Mixtral-8x7B-Instruct-v0.1-GGUF – 15 GB
Puedes usar el buscador, filtrar modelos e instalar todos los que quieras, probarlos y quedarte con los mejores. Si quieres instalar un modelo demasiado grande para tu equipo, leerás un advertencia: “Likely too large for this machine” en rojo.
Podrás encontrar algunos modelos específicos para programación como “CodeLlama“. Si lo descargas podrás pedirle que te ayude con el código, a crear funciones, hacer Code Review u optimización, y hasta a debuguear tu código para encontrar errores.
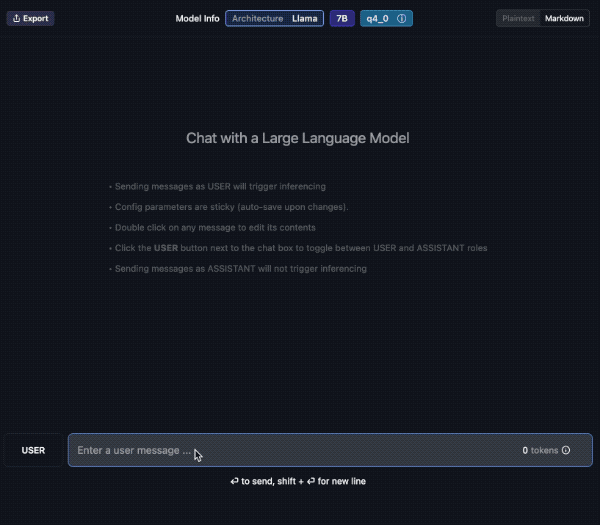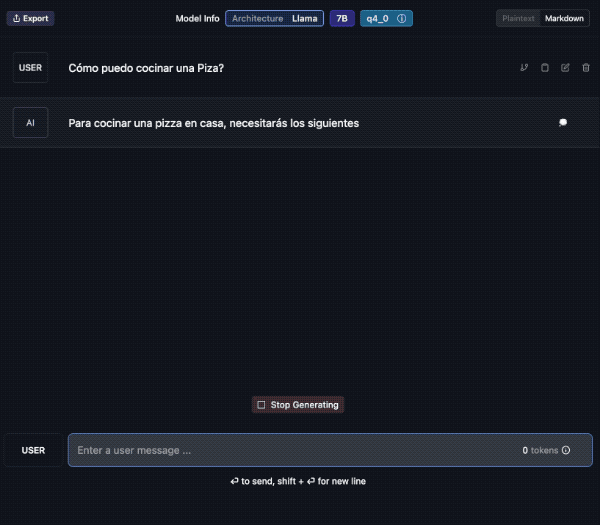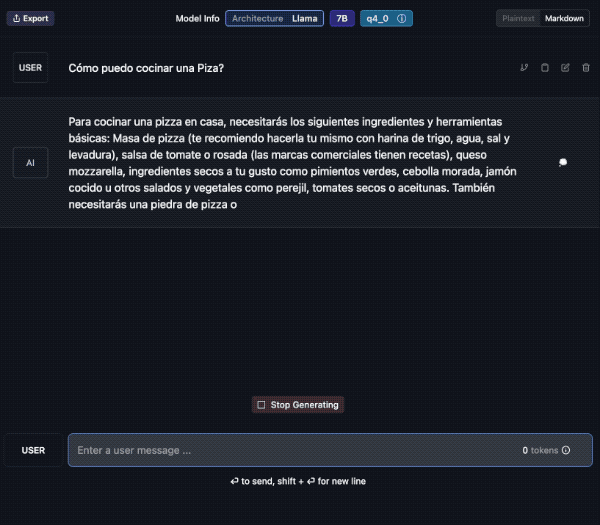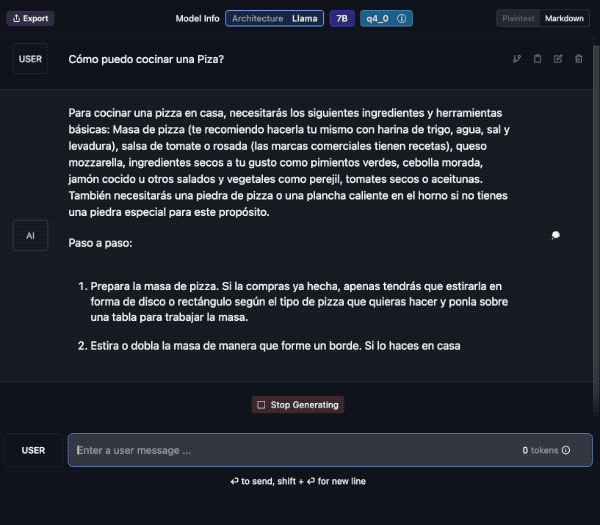
Tu propio Chat (privado!)
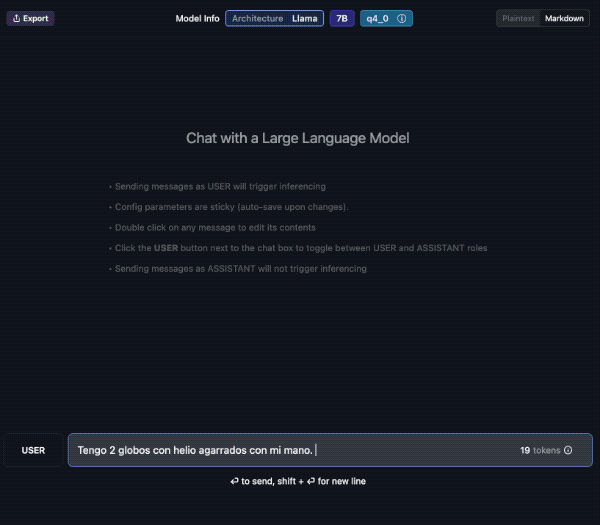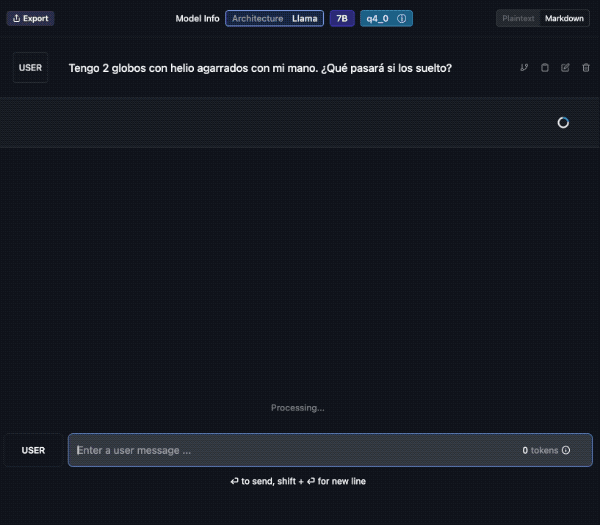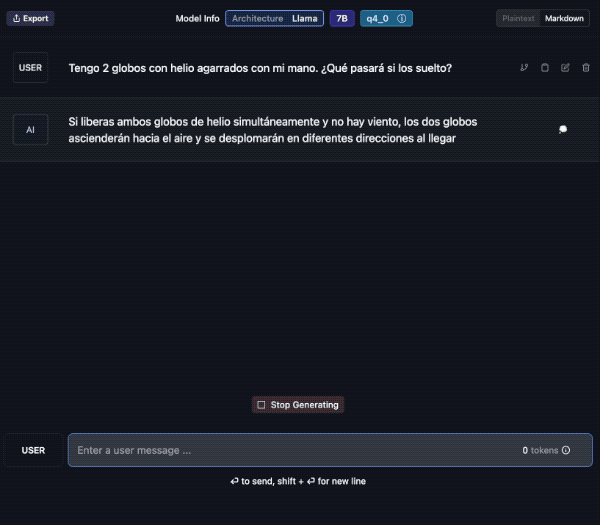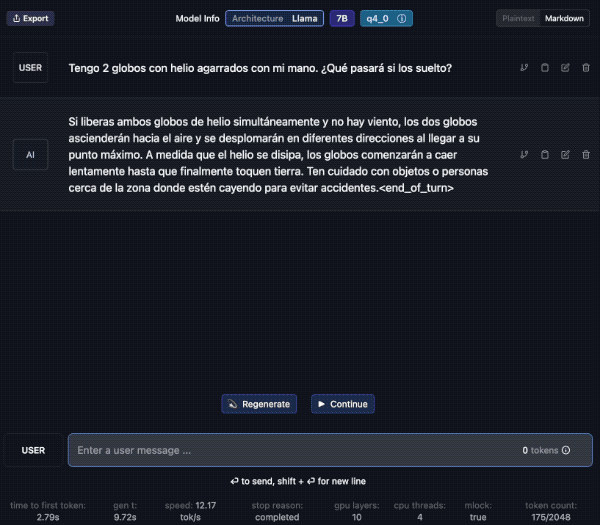
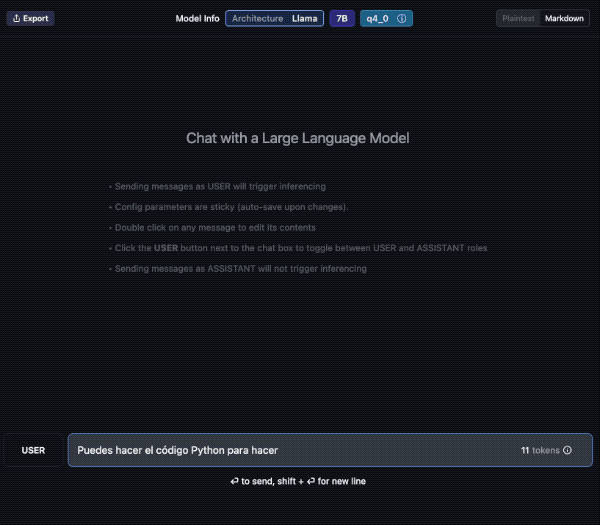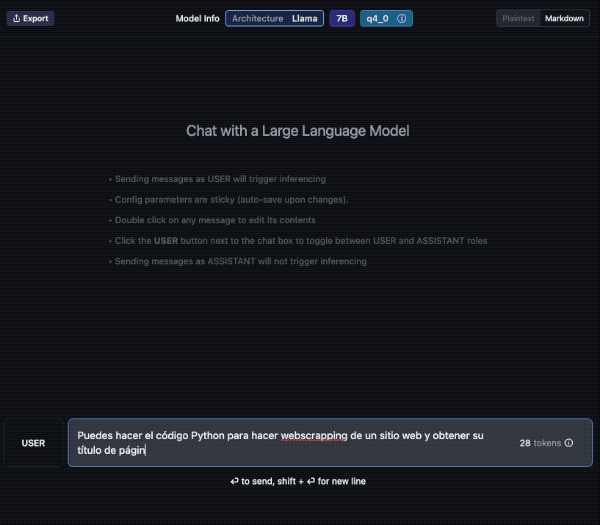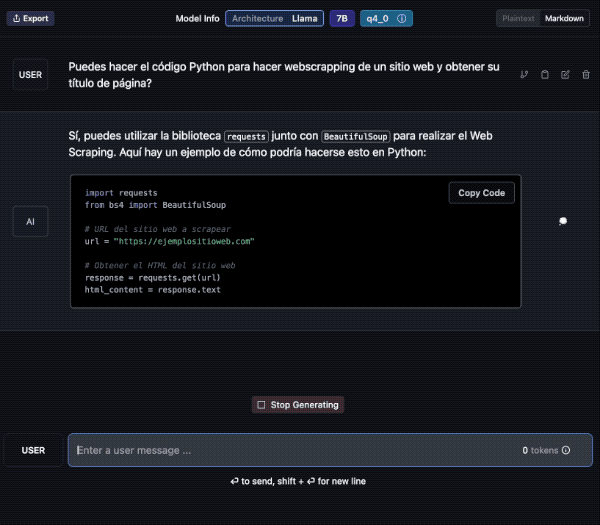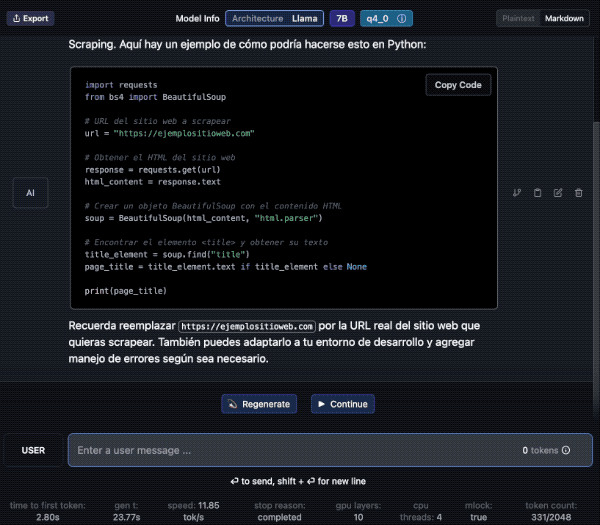
Veamos un ejemplo; aquí descargo el modelo “laser dolphin mixtral” en mi Mac. Una vez descargado, podemos ir a la opción de CHAT para probarlo (el tercer ícono de la izquierda, comenzando de arriba).
Debes elegir el modelo, en la caja de selección central. Tarda unos segundos en cargar y ya lo puedes usar. Además verás que puedes crear diversos chats con conversaciones a tu antojo.
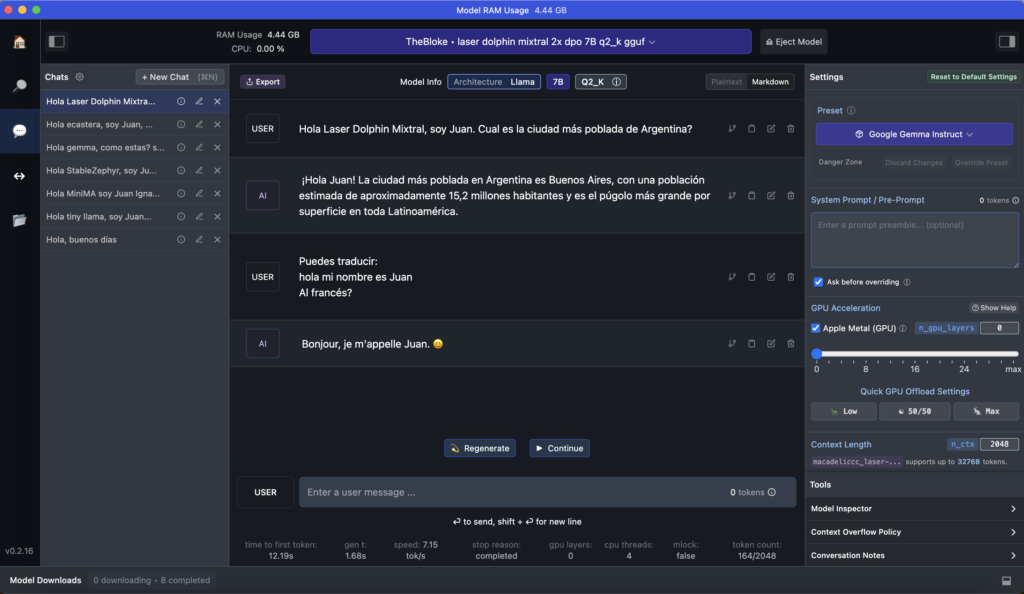
Aquí le pido una traducción al Francés y lo hace sin problemas. Además en la barra inferior contabiliza el uso de tokens y la velocidad. En el panel de la derecha podemos cambiar ajustes del modelo si fuera necesario.
Modo Servidor – a jugar se ha dicho!
Y llegamos a lo interesante: poder utilizar los modelos como si fueran tu propio API, sin tener que pagarle a ningún proveedor 🙂 y manteniendo la privacidad.
Si vas a la opción “Local Server” (el cuarto ícono de la izquierda) y presionas el botón verde “Start Server”, habrás arrancado el modelo para ser consumido desde Python u otro lenguaje de programación. Podemos ir al Visual Studio Code (o cualquier editor de texto) y crear un archivo con unas pocas líneas de código y conectarlo con nuestras Apps…
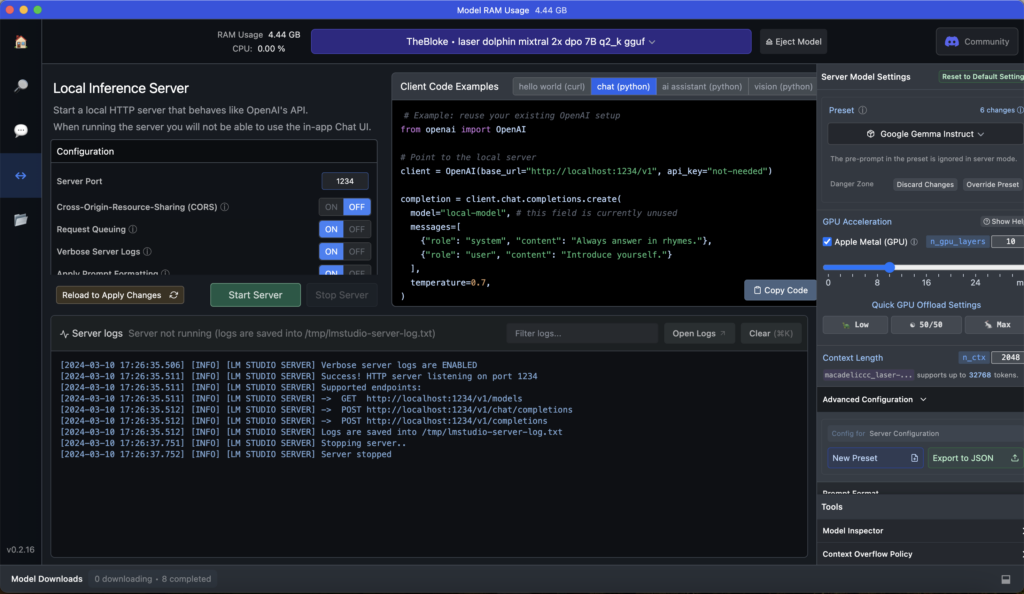
Veamos un ejemplo de uso en código Python. Para ello nos aseguramos de tener instalado en nuestro ambiente de desarrollo la librería de OpenAI. Es curioso porque utilizamos el paquete de OpenAI pero NO utilizaremos el modelo de pago de OpenAI, si no el modelo que hayamos instalado en local!. La librería de openai nos sirve de Wrapper (interface) para conectar cualquier modelo LLM. Se podría decir que es “un hack”… (ó una trampa mortal… broma). Instalamos la librería ejecutando en la terminal:
|
1 |
pip install openai |
Y ahora copia y pega el siguiente código en un notebook Jupyter ó en un archivo Python (“test.py”) y luego ejecútale para consultar cuántos días llueve en Paris al año:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
from openai import OpenAI client = OpenAI(base_url="http://localhost:1234/v1", api_key="not-needed") completion = client.chat.completions.create( model="local-model", # this field is currently unused messages=[ {"role": "system", "content": "Eres un asistente en español y ayudas con respuestas breves."}, {"role": "user", "content": "Buenos días, ¿cuantos días llueve en Paris al año?"} ], temperature=0.7, ) msg = completion.choices[0].message print(msg.content) |
Al cabo de unos segundos (depende tu Ordenador/RAM) obtenemos una respuesta similar a:
|
1 |
En promedio, París experimenta entre 150 y 160 días de lluvia al año. Esto varía cada año y depende del clima general. |
Con esto puedes hacer distintos prompts para poner a prueba tu LLM. Recuerda que el modelo no fue entrenado en Español, sin embargo es capaz de escribir y responder la mayoría de veces correctamente.
Le puedes pedir que te de recetas, que te ayude a planear un viaje, a escribir un libro, poesía, consultar cómo tratar un dolor de estómago (no recomendado) o a en qué acciones de la bolsa invertir tu dinero (menos recomendado).
También le puedes pedir que escriba código python, que genere datasets artificiales en pandas ó que te ayude a conseguir un trabajo con una buena descripción de perfil para tu LinkedIn.
DISCLAIMER: recuerda que el modelo tiene una capacidad limitada y puede dar respuestas falsas o erróneas, no te fíes al 100% de sus respuestas. Por otra parte ten cuidado/sé responsable de preguntar por asuntos delicados o ilegales. Las LLM sufren de una anomalía llamada “alucinaciones” y pueden dar respuetas que suenen muy convincentes pero que sean completamente equivocadas.
En próximos artículos veremos cómo utilizar Prompt Engineering y a realizar tareas de clasificación, soporte técnico, conversar con tus PDF o bases de datos, a usar LangChain y hasta la creación de Agentes!.
Puedes conocer más acerca de la arquitectura GPT en este artículo sobre Transformers
Conclusiones
Espero que estés tan emocionado como yo de poder instalar tu propio modelo LLM en local y poder jugar con él. Debo advertirte que puede llegar a resultar adictivo tener un asistente disponible las 24 horas sólo para ti! Puedes pasarte horas y horas charlando y consultando información. De alguna manera también te pone a prueba a ti… ¿Qué es lo que te interesa saber? ¿Cómo te puede ayudar? ¿Puedes confiar en sus afirmaciones?
En el artículo aprendemos los requerimientos básicos que tenemos para poder ejecutar un LLM en tu ordenador y aprovechamos el software LM Studio que nos facilita la descarga de modelos y su ejecución. Además podemos ejecutar el modo “Servidor Local” que nos permite utilizar el modelo LLM como un componente más de nuestras aplicaciones!
En los próximos artículos podremos realizar nuestros primeros pasos en Prompt Engineering y empezar a sacarle partido a nuestro LLM.
Enlaces de Interés
- Generación de texto en Español con GPT-2
- ¿Qué son los grandes modelos del Lenguaje?
- ¿Cómo funcionan los Transformers?
Suscripción al Blog
Recibe los próximos artículos sobre Machine Learning, estrategias, teoría y código Python en tu casilla de correo!
NOTA: algunos usuarios reportaron que el email de confirmación y/o posteriores a la suscripción entraron en su carpeta de SPAM. Te sugiero que revises los “correos no deseados” y/o que agendes la dirección de remitente en tus contactos.