
Crea tu propio bot-influencer, basado en Ibai Llanos, en Python ¿Qué puede salir mal?
Crearemos nuestra propia IA de generación de texto basada en los diálogos y entrevistas de Ibai Llanos publicados en Youtube. Usaremos un modelo pre-entrenado GPT-2 en castellano disponible desde HuggingFace y haremos el fine-tuning con Pytorch para que aprenda el estilo de escritura deseado.
En este artículo comentaremos brevemente el modelo GPT-2 y crearemos un entorno en Python desde donde poder entrenar y generar texto!

¿Qué son los modelos GPT?
GPT significa “Generative Pre-Training” y es un modelo de Machine Learning creado por OpenAI para la generación de texto. El modelo de Procesamiento del Lenguaje Natural, es un caso particular de Transformers. GPT propone el pre-entrenamiento de un enorme corpus de texto para luego -opcionalmente- realizar el fine-tuning.
El fine-tuning es el proceso de realizar un “ajuste fino” de los parámetros ó capas de la red neuronal, en nuestro caso con un dataset adicional para guiar al modelo a obtener las salidas deseadas.
¿Entonces es aprendizaje no supervisado? Sí; se considera que es aprendizaje no supervisado porque estamos pasando al modelo enormes cantidades de texto, que el modelo organizará automáticamente y le pedimos que “prediga la siguiente palabra” usando como contexto todos los tokens previos (con posicionamiento!). El modelo ajusta sin intervención humana los embeddings y los vectores de Atención. Algunos autores lo consideran aprendizaje “semi-supervisado” porque consideran como “etiqueta de salida” el token a predecir.
Ejemplo: Si tenemos la oración “Buenos días amigos”, el modelo usará “Buenos días” para predecir como etiqueta de salida “amigos”.
Este modelo puede usarse directamente como modelo generativo luego de la etapa de aprendizaje no supervisado (sin hacer fine-tuning).
Al partir de este modelo en crudo y realizar un fine-tuning a nuestro antojo, podemos crear distintos modelos específicos: de tipo Question/Answering, resumen de textos, clasificación, análisis de sentimiento, etc.
Eso es lo que haremos en el ejercicio de hoy: descargar el modelo GPT y realizar el fine-tuning!
¿Cómo es la arquitectura de GPT-2?
GPT es un modelo Transformer. Utiliza sólo la rama “Tansformer-Decoder” a diferencia de modelos como BERT que utilizan la rama Encoder. De esta manera se elimina la Atención cruzada, pues ya no es necesaria y mantiene la “Masked Self-Attention”.
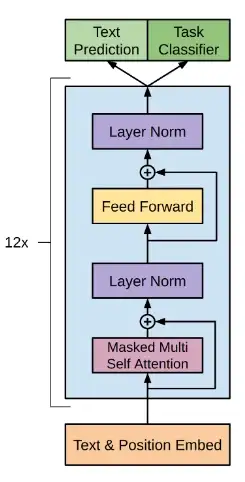
Entre sus características:
- El Transformer Decoder utiliza Masked Self-Attention. Sólo utiliza los tokens precedentes de la oración para calcular la atención del token final.
- GPT es un modelo con posicionamiento absoluto de embeddings.
- GPT fue entrenado con “Causal Language Modelling” y es poderoso para predecir el “siguiente token” de la oración. Esto le permite generar texto coherente, imitando al lenguaje de los humanos.
- GPT-2 fue entrenado con el texto de 8 millones de páginas web que acumulan más de 40GB.
- GPT-2 tiene 1500 millones de parámetros en su versión Extra-Large.
- El tamaño de vocabulario es de 50.257 tokens.
- Existen 4 modelos de distinto tamaño de GPT-2 según la cantidad de decoders y la dimensionalidad máxima.
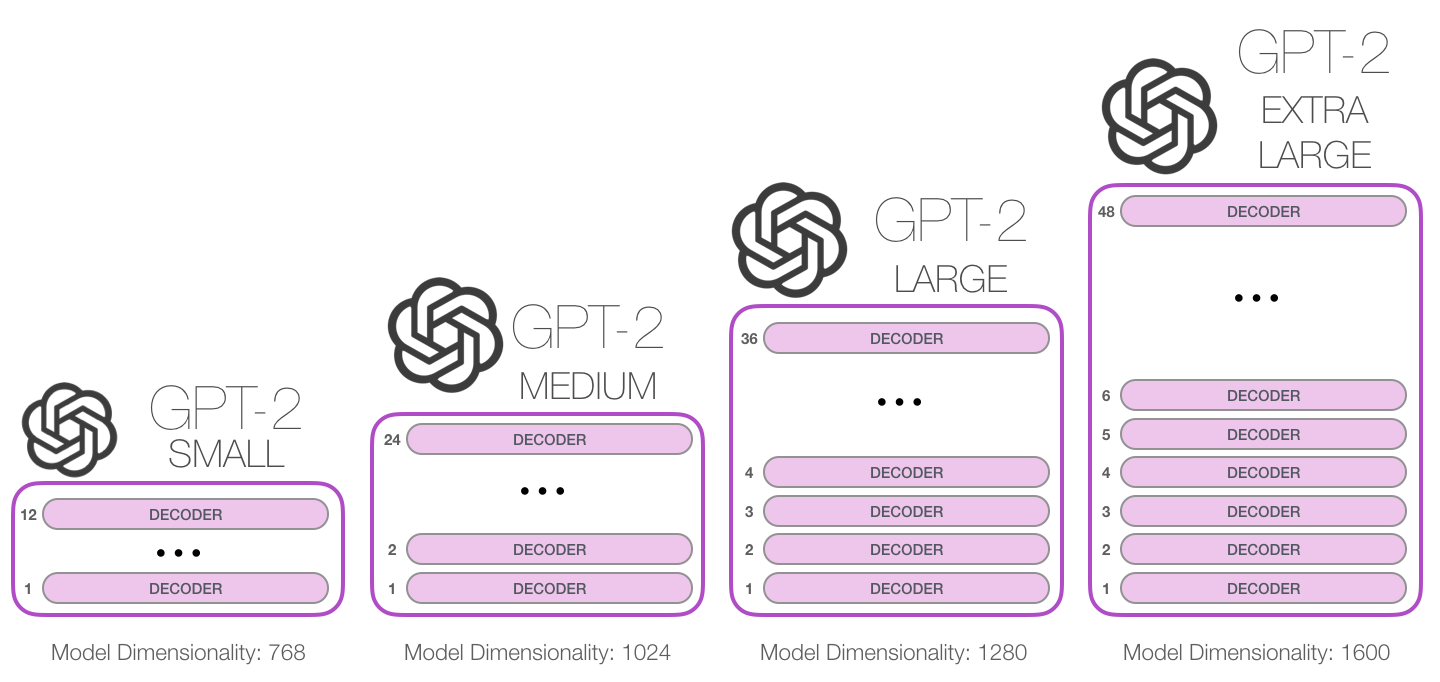
Como vemos, la versión pequeña tiene un tamaño aún manejable para entrenar en un ordenador “normal”. Es la versión del modelo que utilizaremos en el ejercicio.
Zero shot Learning
Una ventaja que se consigue al entrenar al modelo con millones de textos de conocimiento general (en contraposición a utilizar textos sobre un sólo tema) es que el modelo consigue habilidades “zero shot”, es decir, logra realizar satisfactoriamente algunas tareas para las que no ha sido entrenado específicamente. Por ejemplo, GPT-2 puede traducir textos de inglés a francés sin haber sido entrenado para ello. También consigue responder a preguntas ó generar código en Java.
¿Por qué usar GPT-2?
Puede que sepas de la existencia de GPT-3 y hasta puede que hayas escuchado hablar sobre el recientemente lanzado “ChatGPT” que algunos denominan como GPT-3.5 ó GPT-4. Entonces, ¿porqué vamos a usar al viejo GPT-2 en este ejercicio?
La respuesta rápida es porque GPT-2 es libre!, su código fue liberado y tenemos acceso al repositorio y a su implementación desde HuggingFace. Existen muchos modelos libres tuneado de GPT-2 y publicados que podemos usar. Si bien cuenta con un tamaño de parámetros bastante grande, GPT-2 puede ser reentrenado en nuestro propio ordenador.
En cuanto a resultados, GPT-2 fue unos de los mejores de su época (Feb 2019), batiendo records y con valores -en algunos casos- similares a los del humano:
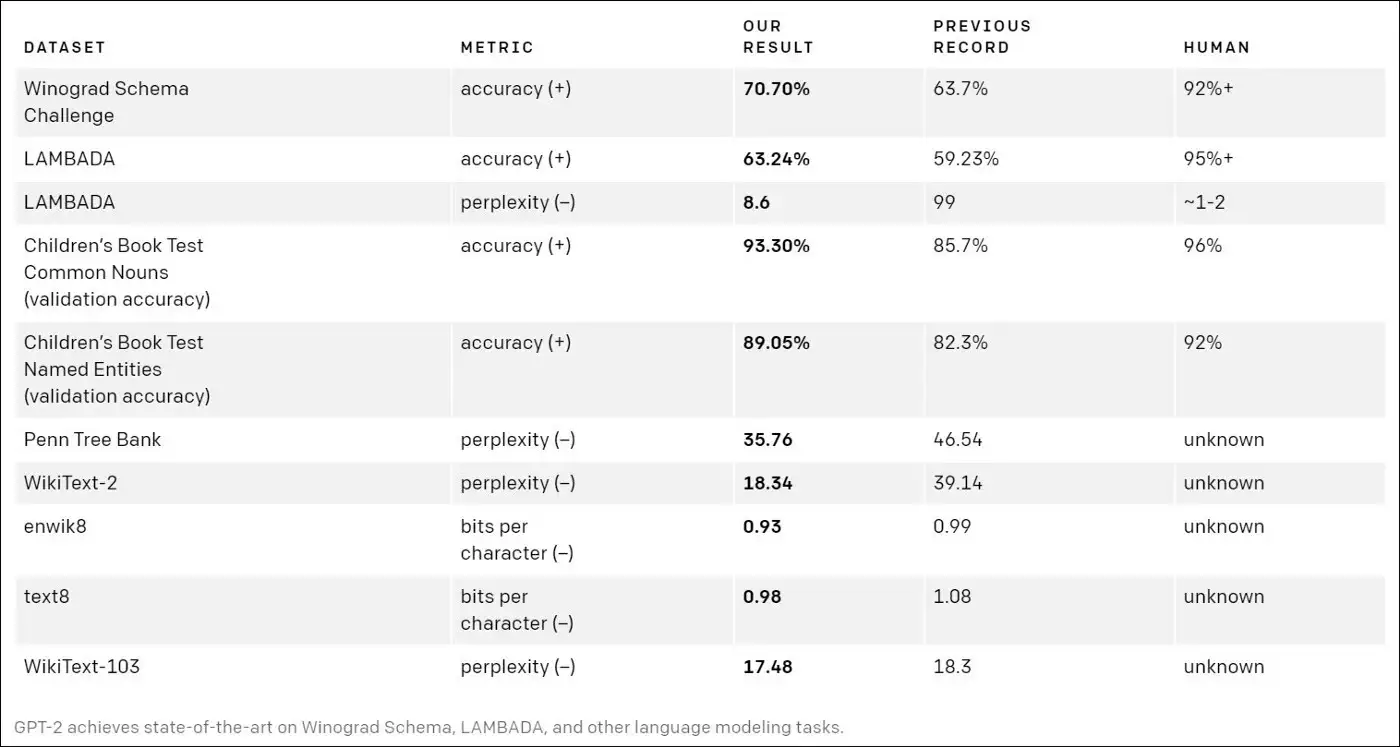
En cambio GPT-3 aún no ha sido liberado, ni su código ni su red pre-entrenada, además de que tiene un tamaño inmensamente mayor a su hermano pequeño, haciendo casi imposible que lo podamos instalar ó usar en nuestra computadora de casa ó trabajo.
Es cierto que puedes utilizar GPT-3 mediante la API de pago de OpenAI y también se puede utilizar ChatGPT de modo experimental desde su web. Te animo a que lo hagas, pero no dejes de aprender a utilizar GPT-2 que será de gran ayuda para comprender como ajustar uno de estos modelos de lenguaje para tus propios fines.
¿Qué tiene que ver HuggingFace en todo esto?
HuggingFace se ha convertido en el gran repositorio de referencia de modelos pre-entrenados. Es un sitio web en donde cualquier persona ó insitutición pueden subir sus modelos entrenados para compartirlos.
HuggingFace ofrece una librería python llamada transformers que permite descargar modelos preentrenados de NLP (GPT, BERT, BART,ELECTRA, …), utilizarlos, hacer el fine tuning, reentrenar.
En el ejercicio que haremos instalaremos la librería de HuggingFace para acceder a los modelos de GPT.
Modelo pre-entrenado en Español
Dentro de HuggingFace podemos buscar modelos para NLP y también para Visión Artificial, cómo el de Stable Diffusion, para crear imágenes, como se explica en un anterior post del blog!).
Y podemos encontrar Modelos con distintos fines. En nuestro caso, estamos interesados en utilizar un modelo en Español.
Usaremos el modelo llamado “flax-community/gpt-2-spanish“, puedes ver su ficha aquí, y desde ya, agradecemos enormemente al equipo que lo ha creado y compartido gratuitamente. Ocupa unos 500MB.
Un detalle, que verás en el código: realmente cargaremos una red pre-entrenada con los pesos y el embeddings PERO también usaremos el tokenizador! (es decir, cargaremos 2 elementos del repositorio de HuggingFace, no sólo el modelo).
El proyecto Python: “Tu propio bot influencer”
En otros artículos de NLP de este tipo, utilizan textos de Shakespeare porque es un escritor reconocido, respetado y porque no tiene derechos de autor. Nosotros utilizaremos textos de Ibai Llanos generados a partir de transcripciones generadas automáticamente por Whisper de sus videos de Youtube. Ibai es un reconocido Streamer español de Twitch. ¿Porqué Ibai? Para hacer divertido el ejercicio! Para que sea en castellano, con jerga actual 
El proyecto consiste en tomar un modelo GPT-2 pre-entrenado en castellano y realizar el fine-tuning con nuestro propio dataset de texto. Como resultado obtendremos un modelo que será capaz de crear textos “con la manera de hablar” de Ibai.
Aquí puedes encontrar la Jupyter notebook completa en mi repo de Github con el ejercicio que realizaremos. En total son unas 100 líneas de código.
El Dataset educacional: Diálogos de Ibai

El dataset es una selección totalmente arbitraría de videos de Youtube de Ibai con entrevistas y charlas de sus streams en Twitch. En algunos videos juega videojuegos en vivo, entrevista cantantes, futbolistas ó realiza compras de productos usados que le llaman la atención.
Utilicé un notebook de Google Colab con Whisper que es un modelo de machine learning lanzado hace pocos meses (en 2022) que realiza la transcripción automática de Audio a Texto. Usaremos como entradas esos textos. Disclaimer: Pueden contener errores de mala transcripción y también es posible que hubiera palabras que el modelo no comprenda del español.
El archivo de texto que utilizaremos como Dataset con fines educativos, lo puedes encontrar aquí.
Creación del entorno Python con Anaconda
Si tienes instalado Anaconda, puedes crear un nuevo Environment python para este proyecto. Si no, instala anaconda siguiendo esta guía, ó utiliza cualquier manejador de ambientes python de tu agrado.
También puedes ejecutar el código una notebook en la nube con Google Colab y aprovechar el uso de GPU gratuito. En este artículo te cuento sobre cómo usar Colab.
En este ejercicio utilizaremos la librería Pytorch para entrenar la red neuronal. Te recomiendo ir a la web oficial de Pytorch para obtener la versión que necesitas en tu ordenador, porque puede variar la instalación si usas Windows, Linux ó Mac y si tienes o no GPU.
Ejecuta las siguientes líneas en tu terminal:
Importamos las librerías
Ahora pasamos a un notebook o una IDE Python y empezamos importando las librerías python que utilizaremos, incluyendo transformers de HuggingFace:
Uso de CPU ó GPU
Haremos una distinción; si vamos a utilizar GPU para entrenar ó CPU, definiendo una variable llamada device. Nótese que también alteramos el tamaño que usaremos de batch. En el caso de GPU, podemos utilizar valores 2 ó 3 según el tamaño de memoria RAM que tenga la tarjeta gráfica.
Cargamos el Modelo de HuggingFace
La primera vez que ejecutemos esta celda, tomará unos minutos en descargar los 500MB del modelo y el tokenizador en Español desde HuggingFace, pero luego ya se utilizará esa copia desde el disco, siendo una ejecución inmediata.
Para este ejercicio estamos creando un “token especial” (de control) que llamaremos “ibai” con el que luego indicaremos al modelo que queremos obtener una salida de este tipo.
Cargamos el Dataset “Ibai_textos.txt”
Creamos una clase python que hereda de Dataset que recibe el archivo txt que contiene los textos para fine-tuning.
Instanciamos la clase, pasando el nombre de archivo “ibai_textos.txt” a utilizar
Entrenamos haciendo el Fine-Tuning
Realizando entre 1 y 3 epochs debería ser suficiente para que el modelo quede tuneado.
Ahora si, a entrenar el modelo durante cerca de 2 horas si tenemos GPU ó durante un día entero en CPU.
El código es bastante estándar en PyTorch para entreno de redes neuronales profundas; un loop principal por epoch donde procesamos por batches las líneas de texto del dataset y hacemos backpropagation.
Guardar el modelo, para uso futuro
El tiempo de entreno varía según tu ordenador, memoria RAM y si tienes o no placa de video con GPU.
Luego de varias horas de entreno, mejor guardar el modelo para no tener que reentrenar cada vez y reutilizar el modelo que hicimos. Para guardar hacemos:
En la notebook con el ejercicio verás también una celda con el código de ejemplo para cargar tu modelo ya entrenado.
Crear Texto al estilo influencer
Generamos 3 salidas preguntando ¿Qué es el fútbol? con máximo de 300 caracteres. Puedes variar estos parámetros para obtener más párrafos y con un máximo de 764 letras.
Fijate que agregamos al prompt el token de control de inicio (startoftext) pero también nuestro token de control que llamamos “ibai”.
Y obtenemos como salidas:
- <|ibai|>¿ qué es el fútbol? porque yo creo que son los mejores momentos de la vida del mundo. eh no se. eh y eso es lo que me llama la atención. eh ¡gracias! gracias.
- <|ibai|>¿ qué es el fútbol? fútbol es la suma de sus defectos, del mal que uno puede poner en uno, de un mal que tú quieres que la gente haga como si nada, es decir, yo soy el contrario, yo soy el mejor, soy el peor. es decir, que tú eres el mejor y yo soy el peor. ¡joder, yo soy del mejor! ¡pero, bueno, ya está! ¿ tú eres el que está ahí para que me lo diga? ¿ me crees que estás bueno? no, no.
- <|ibai|>¿ qué es el fútbol? para empezar, el que se mueve por el interés de los futbolistas es increíble. ¿ de quién eres? en el mejor sentido, y además de lo que eres. te he dicho que ya sé que a ti te gusta eso de hacer las cosas, pero eres muy, muy, muy, muy, muy, muy especial, ¿ no? un niño. te lo voy a decir un poco de corazón.
Ahora ya puedes jugar y probar tú mismo con distintas salidas!
Aquí te dejo algunos ejemplos divertidos que conseguí (pinto en negrita el comienzo del prompt enviado al modelo):
- <|ibai|>para mi la vida es una cosa en la que te tienes que esforzar por lo que te gusta, porque quieres algo. cuando me pongo de acuerdo en algo me siento preparado para el momento. el ego que te llevas es la presión de no ser perfecto. y claro, si quieres, no quieres ser tan bueno, eres tú.
- <|ibai|>la música que me gusta escuchar, claro. hay muchas personas que no nos conocen de nada, se nota. es un tío muy, muy, muy directo y creo que a lo mejor es un poco directo, de hecho, hay mucho ego en su actitud. la gente en general está bastante influenciada por él.
- <|ibai|>un día todos deberíamos tener una vida, que es el futuro, una vida en paz con uno mismo, con la sociedad, y eso no es tan complicado como parece. y te digo lo de
- <|ibai|>la felicidad es cuando hay armonía, que el mundo entero tiene su armonía. bueno, amigos, es que estamos unidos, a mí la música me relaja. bueno, es que no quiero dejar de escucharme ni de escuchar. y la música, de hecho, no es mi música, es mi vida.
- <|ibai|>si voy a un restaurante, voy a un restaurante de argentina. me voy a un restaurante argentino. ¡ah, la verdad que me lo estoy pasando bien!
- <|ibai|>la navidad es muy importante, porque es la época que vivimos. ¿ no crees que la navidad sería algo diferente de como la vivimos nosotros? en vez de algo muy tradicional, de un poco de juerga y de hacer una noche loca. no sé si la navidad es de las fechas en las que más fiesta hay. de verdad, no sé si es de las fechas en las que más fiesta hay o más fiesta no hay.
- <|ibai|>en el próximo mes voy a empezar el segundo año. me llevo la bici para el club. de momento, voy a aprender a convivir con mis seguidores. y de hecho, hoy estoy hablando de eso.
- <|ibai|>la inteligencia artificial, la realidad aumentada, ¿ qué pasa, tío? en este mundo hay gente que intenta crear un juego de magia que le pueda pasar un poquito de mal. bueno, que sí, que le pasa con las personas.
- <|ibai|>la inteligencia artificial se está dando en todos los ámbitos. se está dando en todos los ámbitos, es cierto. en general, es un mundo donde la inteligencia artificial y el cerebro humano son los dos primeros motores.
- <|ibai|>¿ qué es la inteligencia artificial? inteligencia artificial, es la de verdad. si la inteligencia artificial es más potente, es más fácil trabajar con ella. y es más difícil tener más inteligencia. porque la inteligencia artificial es la de verdad.
- <|ibai|>yo sé mucho sobre el tema, pero me hace un poco de gracia. y también quiero que vosotros tengáis una gran audiencia, que leéis un libro, porque yo creo que eso es una idea que está muy bien. y es que si a tu amiga le pasa lo mismo que a ti, se va al final. por eso te pido que se ponga a grabar el libro, porque yo creo que eso, como el libro ya está hecho, le va a quedar espectacular.
- <|ibai|>el amor es el camino, y no te vas a quedar ahí, a las 9. 40 am. el amor es un sentimiento que debe de ser muy fuerte en tu vida. a ver, yo creo que en la vida hay un tipo de personas que te hacen sentir una persona especial en tu vida. y el amor, que es la otra persona, también lo es.

Resumen
En estos días estamos viendo cómo ChatGPT está siendo trending topic por ser el modelo GPT más poderoso y versátil de OpenAI, con capacidad de responder a cualquier pregunta, traducir idiomas, dar definiciones, crear poesía, historias y realizar snippets de código python.
En este artículo te acercamos un poco más a conocer qué son los modelos GPT que están revolucionando el campo del NLP mediante un ejercicio práctico.
Ya conoces un poco más sobre la librería transformers de HuggingFace, sobre los distintos modelos que puedes descargar en tu ordenador y personalizar. Como siempre, esto es sólo la punta del iceberg, te invito a que sigas investigando y aprendiendo más sobre todo ello y me dejes tus comentarios al respecto.
Nos vemos en el próximo post!
Puedes descargar la notebook con el ejercicio completo y el archivo con los textos de Ibai.
Otros Enlaces de interés
Suscripción al Blog
Recibe los próximos artículos sobre Machine Learning, estrategias, teoría y código Python en tu casilla de correo!
NOTA: algunos usuarios reportaron que el email de confirmación y/o posteriores a la suscripción entraron en su carpeta de SPAM. Te sugiero que revises y recomiendo que agregues nuestro remitente info @ aprendemachinelearning.com a tus contactos para evitar problemas. Gracias!
El libro del Blog
Si te gustan los contenidos del blog y quieres darme tu apoyo, puedes comprar el libro en papel, ó en digital (también lo puede descargar gratis!).
Excelente articulo. Muchas. muchas gracias.
Una duda, al entrenar, aparece que el attention mask no se configuraron. Sin embargo, veo que en la clase de entrada se establece:
self.attn_masks.append(torch.tensor(encodings_dict[‘attention_mask’]))
Cómo solventar el warning?
Gracias!!
======== Epoch 1 / 1 ========
Training…
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input’s attention_mask to obtain reliable results.
Setting pad_token_id to eos_token_id:50256 for open-end generation.
Batch 500 of 3,397. Loss: 0.18576528131961823. Elapsed: 0:06:19.
0: ladrones, aunque en este caso es que ha puesto, aunque no pueda, su vida patas arribas con que no es de su cuerda.
En fin, que me gustaría que fuese. a b. que son los de la de si si si. a mí que lo voy a decir.
– a mí que me encanta ser el mejor, y que le ponga un freno a su carrera, a la mía que, sin él, no quiero ser el mejor.
– ¡qué va! si a que soy el mejor y a lo que voy a decir, a ser el mejor. o sea, no sé qué pensar en mi casa, yo
Excelente post Juan!
¿Podrías contarnos como has realizado la transcripción automática de audio a texto en Whisper?
Hola Pedro, para la conversión usando Whisper sigue los pasos de esta notebook: Whisper to Youtube.
Me gustaría hacer un artículo sobre Whisper en el futuro.
Saludos!
El notebook me ha ido perfecto pero he tenido problemas con Python en Visual Studio Code porque no me instalaba Pytorch.
Al final resulta que Pytorch no funciona con la última versión de Python. Si que se instala bien con la 3.10.9. Parece que es un problema histórico y siempre van en Pytorch una versión por detrás de Python.