
Crea en Python un motor de recomendación con Collaborative Filtering
Una de las herramientas más conocidas y utilizadas que aportó el Machine Learning fueron los sistemas de Recomendación. Son tan efectivas que estamos invadidos todos los días por recomendaciones, sugerencias y “productos relacionados” aconsejados por distintas apps y webs.

Sin dudas, los casos más conocidos de uso de esta tecnología son Netflix acertando en recomendar series y películas, Spotify sugiriendo canciones y artistas ó Amazon ofreciendo productos de venta cruzada <<sospechosamente>> muy tentadores para cada usuario.
Pero también Google nos sugiere búsquedas relacionadas, Android aplicaciones en su tienda y Facebook amistades. O las típicas “lecturas relacionadas” en los blogs y periódicos.
Todo E-Comerce que se precie de serlo debe utilizar esta herramienta y si no lo hace… estará perdiendo una ventaja competitiva para potenciar sus ventas.
¿Qué son los Sistemas ó Motores de Recomendación?
Los sistemas de recomendación, a veces llamados en inglés “recommender systems” son algoritmos que intentan “predecir” los siguientes ítems (productos, canciones, etc.) que querrá adquirir un usuario en particular.
Antes del Machine Learning, lo más común era usar “rankings” ó listas con lo más votado, ó más popular de entre todos los productos. Entonces a todos los usuarios se les recomendaba lo mismo. Es una técnica que aún se usa y en muchos casos funciona bien, por ejemplo, en librerías ponen apartados con los libros más vendidos, best sellers. Pero… ¿y si pudiéramos mejorar eso?… ¿si hubiera usuarios que no se guían como un rebaño y no los estamos reteniendo?…
Los Sistemas de Recomendación intentan personalizar al máximo lo que ofrecerán a cada usuario. Esto es ahora posible por la cantidad de información individual que podemos recabar de las personas y nos da la posibilidad de tener una mejor tasa de aciertos, mejorando la experiencia del internauta sin ofrecer productos a ciegas.
Tipos de motores
Entre las estrategias más usadas para crear sistemas de recomendación encontramos:
- Popularity: Aconseja por la “popularidad” de los productos. Por ejemplo, “los más vendidos” globalmente, se ofrecerán a todos los usuarios por igual sin aprovechar la personalización. Es fácil de implementar y en algunos casos es efectiva.
- Content-based: A partir de productos visitados por el usuario, se intenta “adivinar” qué busca el usuario y ofrecer mercancías similares.
- Colaborative: Es el más novedoso, pues utiliza la información de “masas” para identificar perfiles similares y aprender de los datos para recomendar productos de manera individual.
En este artículo comentaré mayormente el Collaborative Filtering y realizaremos un ejercicio en Python.
¿Cómo funciona Collaborative Filtering?
Para explicar cómo funciona Collaborative Filtering vamos a entender cómo será el dataset.
Ejemplo de Dataset
Necesitaremos, “ítems” y las valoraciones de los usuarios. Los ítems pueden ser, canciones, películas, productos, ó lo que sea que queremos recomendar.
Entonces nos quedará una matriz de este tipo, donde la intersección entre fila y columna es una valoración del usuario:

Entonces veremos que tenemos “huecos” en la tabla pues evidentemente no todos los usuarios tienen o “valoraron” todos los ítems. Por ejemplo si los ítems fueran “películas”, es evidente que un usuario no habrá visto <<todas las películas del mundo>>… entonces esos huecos son justamente los que con nuestro algoritmo “rellenaremos” para recomendar ítems al usuario.
Una matriz con muchas celdas vacías se dice -en inglés- que es sparce (y suele ser normal) en cambio si tuviéramos la mayoría de las celdas cubiertas con valoraciones, se llamará dense.
Tipos de Collaborative Filtering
- User-based: (Este es el que veremos a continuación)
- Se identifican usuarios similares
- Se recomiendan nuevos ítems a otros usuarios basado en el rating dado por otros usuarios similares (que no haya valorado este usuario)
- Item-based:
- Calcular la similitud entre items
- Encontrar los “mejores items similares” a los que un usuario no tenga evaluados y recomendárselos.
Predecir gustos (User-based)
Collaborative Filtering intentará encontrar usuarios similares, para ofrecerle ítems “bien valorados” para ese perfil en concreto (lo que antes llamé “rellenar los huecos” en la matriz). Hay diversas maneras de medir ó calcular la similitud entre usuarios y de ello dependerá que se den buenas recomendaciones. Pero tengamos en cuenta que estamos hablando de buscar similitud entre “gustos” del usuario sobre esos ítems, me refiero a que no buscaremos perfiles similares por ser del mismo sexo, edad ó nivel educativo. Sólo nos valdremos de los ítems que ha experimentado, valorado (y podría ser su secuencia temporal) para agrupar usuarios “parecidos”.
Una de las maneras de medir esa similitud se llama “distancia por coseno de los vectores“ y por simplificar el concepto, digamos que crea un espacio vectorial con n dimensiones correspondientes a los n items y sitúa los vectores siendo su medida el “valor rating” de cada usuario -a ese item-. Luego calcula el ángulo entre los vectores partiendo de la “coordenada cero”. A “poca distancia” entre ángulos, se corresponde con usuarios con mayor similitud.
Este método no es siempre es perfecto… pero es bastante útil y rápido de calcular.
Calcular los Ratings
Una vez que tenemos la matriz de similitud, nos valdremos de otra operación matemática para calcular las recomendaciones.
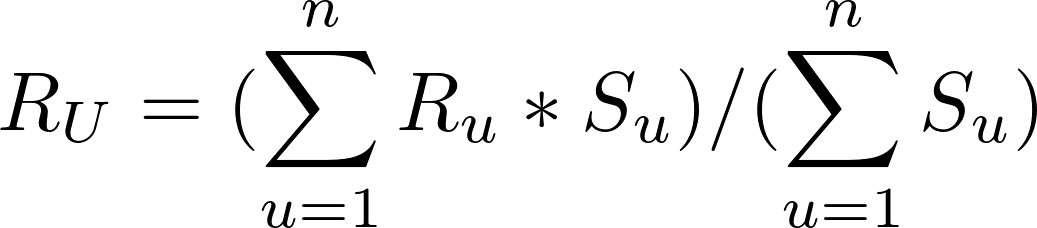
Lo haremos es: cada rating se multiplica por el factor de similitud de usuario que dio el rating. La predicción final por usuario será igual a la suma del peso de los ratings dividido por la “suma ponderada”.
Bueno, no te preocupes que este cálculo luego lo verás en código y no tiene tanto truco…
Ejercicio en Python: “Sistema de Recomendación de Repositorios Github”
Vamos a crear un motor de recomendación de repositorios Github. Es la propuesta que hago en el blog… porque los recomendadores de música, películas y libros ya están muy vistos!.
La idea es que si este recomendador le parece de interés a los lectores, en un futuro, publicarlo online para extender su uso. Inicialmente contaremos con un set de datos limitado (pequeño), pero que como decía, podremos llevar a producción e ir agregando usuarios y repositorios para mejorar las sugerencias.
Vamos al código!
Cargamos las librerías que utilizaremos
|
1 2 3 4 5 6 7 |
import pandas as pd import numpy as np from sklearn.metrics import mean_squared_error from sklearn.model_selection import train_test_split from sklearn.neighbors import NearestNeighbors import matplotlib.pyplot as plt import sklearn |
Cargamos y previsualizamoás los 3 archivos de datos csv que utilizaremos:
|
1 2 3 4 5 6 |
df_users = pd.read_csv("users.csv") df_repos = pd.read_csv("repos.csv") df_ratings = pd.read_csv("ratings.csv") print(df_users.head()) print(df_repos.head()) print(df_ratings.head()) |



Vemos que tenemos un archivo con la información de los usuarios y sus identificadores, un archivo con la información de los repositorios y finalmente el archivo “ratings” que contiene la valoración por usuario de los repositorios. Como no tenemos REALMENTE una valoración del 1 al 5 -como podríamos tener por ejemplo al valorar películas-, la columna rating es el número de usuarios que tienen ese mismo repositorio dentro de nuestra base de datos. Sigamos explorando para comprende un poco mejor:
|
1 2 3 4 |
n_users = df_ratings.userId.unique().shape[0] n_items = df_ratings.repoId.unique().shape[0] print (str(n_users) + ' users') print (str(n_items) + ' items') |
30 users
167 items
Vemos que es un dataset reducido, pequeño. Tenemos 30 usuarios y 167 repositorios valorados.
|
1 |
plt.hist(df_ratings.rating,bins=8) |

Tenemos más de 80 valoraciones con una puntuación de 1 y unas 40 con puntuación en 5. Veamos las cantidades exactas:
|
1 |
df_ratings.groupby(["rating"])["userId"].count() |
rating
1 94
2 62
3 66
4 28
5 40
6 12
7 14
8 8
Name: userId, dtype: int64
|
1 |
plt.hist(df_ratings.groupby(["repoId"])["repoId"].count(),bins=8) |
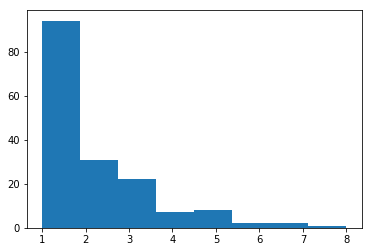
Aquí vemos la cantidad de repositorios y cuantos usuarios “los tienen”. La mayoría de repos los tiene 1 sólo usuario, y no los demás. Hay unos 30 que los tienen 2 usuarios y unos 20 que coinciden 3 usuarios. La suma total debe dar 167.
Creamos la matriz usuarios/ratings
Ahora crearemos la matriz en la que cruzamos todos los usuarios con todos los repositorios.
|
1 2 |
df_matrix = pd.pivot_table(df_ratings, values='rating', index='userId', columns='repoId').fillna(0) df_matrix |
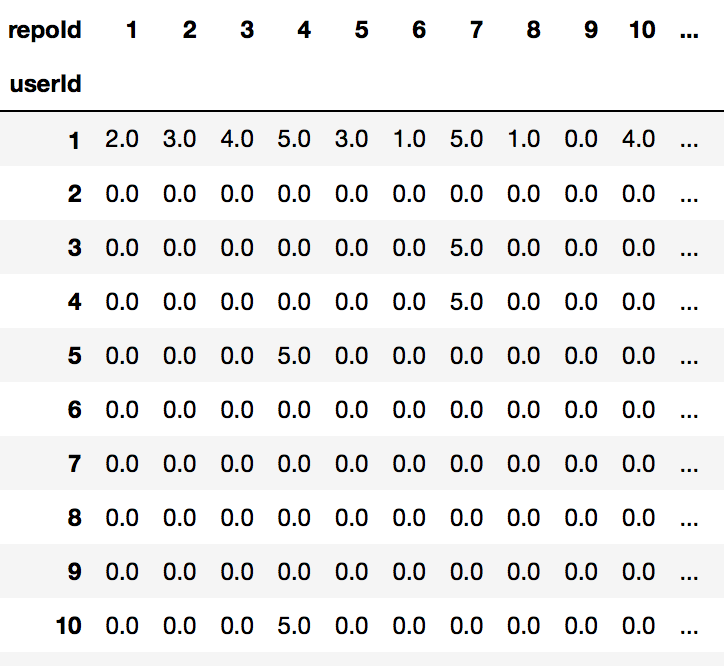
Vemos que rellenamos los “huecos” de la matriz con ceros. Y esos ceros serán los que deberemos reemplazar con las recomendaciones.
Sparcity
Veamos el porcentaje de sparcity que tenemos:
|
1 2 3 4 5 |
ratings = df_matrix.values sparsity = float(len(ratings.nonzero()[0])) sparsity /= (ratings.shape[0] * ratings.shape[1]) sparsity *= 100 print('Sparsity: {:4.2f}%'.format(sparsity)) |
Sparsity: 6.43%
Esto serán muchos “ceros” que rellenar (predecir)…
Dividimos en Train y Test set
Separamos en train y test para -más adelante- poder medir la calidad de nuestras recomendaciones.
¿Porqué es tan importante dividir en Train, Test y Validación del Modelo?
|
1 2 3 |
ratings_train, ratings_test = train_test_split(ratings, test_size = 0.2, random_state=42) print(ratings_train.shape) print(ratings_test.shape) |
(24, 167)
(6, 167)
Matriz de Similitud: Distancias por Coseno
Ahora calculamos en una nueva matriz la similitud entre usuarios.
|
1 2 |
sim_matrix = 1 - sklearn.metrics.pairwise.cosine_distances(ratings) print(sim_matrix.shape) |
(30, 30)
|
1 2 3 |
plt.imshow(sim_matrix); plt.colorbar() plt.show() |
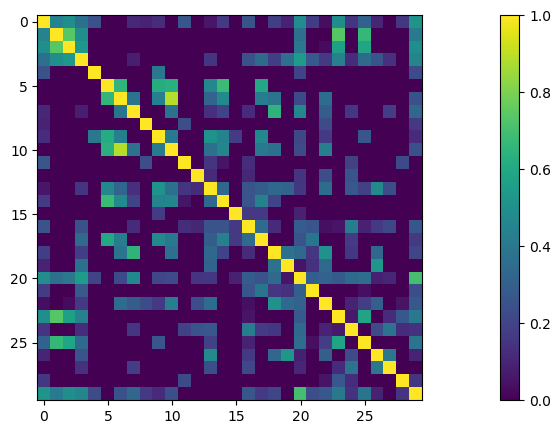
Cuanto más cercano a 1, mayor similitud entre esos usuarios.
Predicciones -ó llamémosle “Sugeridos para ti”-
|
1 2 3 4 5 |
#separar las filas y columnas de train y test sim_matrix_train = sim_matrix[0:24,0:24] sim_matrix_test = sim_matrix[24:30,24:30] users_predictions = sim_matrix_train.dot(ratings_train) / np.array([np.abs(sim_matrix_train).sum(axis=1)]).T |
|
1 2 3 4 |
plt.rcParams['figure.figsize'] = (20.0, 5.0) plt.imshow(users_predictions); plt.colorbar() plt.show() |
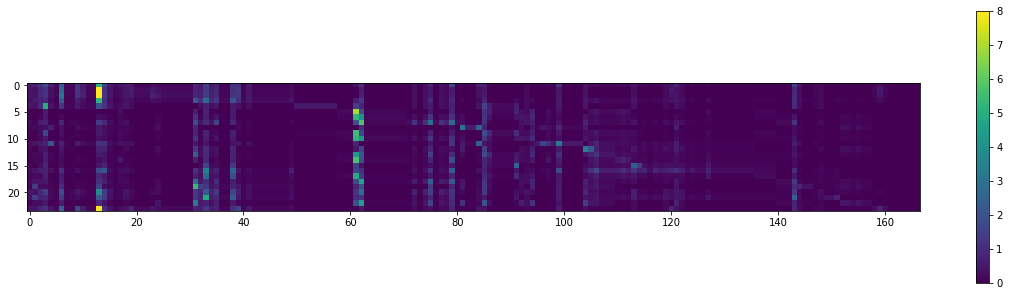
Vemos pocas recomendaciones que logren puntuar alto. La mayoría estará entre 1 y 2 puntos. Esto tiene que ver con nuestro dataset pequeño.
Vamos a tomar de ejemplo mi usuario de Github que es jbagnato.
|
1 2 3 4 5 6 7 8 9 10 |
USUARIO_EJEMPLO = 'jbagnato' data = df_users[df_users['username'] == USUARIO_EJEMPLO] usuario_ver = data.iloc[0]['userId'] - 1 # resta 1 para obtener el index de pandas. user0=users_predictions.argsort()[usuario_ver] # Veamos los tres recomendados con mayor puntaje en la predic para este usuario for i, aRepo in enumerate(user0[-3:]): selRepo = df_repos[df_repos['repoId']==(aRepo+1)] print(selRepo['title'] , 'puntaje:', users_predictions[usuario_ver][aRepo]) |
4 ytdl-org / youtube-dl
Name: title, dtype: object puntaje: 2.06
84 dipanjanS / practical-machine-learning-with-py…
Name: title, dtype: object puntaje: 2.44
99 abhat222 / Data-Science–Cheat-Sheet
Name: title, dtype: object puntaje: 3.36
Vemos que los tres repositorios con mayor puntaje para sugerir a mi usuario son el de Data-Science–Cheat-Sheet con una puntuación de 3.36, practical-machine-learning-with-py con 2.44 y youtube-dl con 2.06. Lo cierto es que no son puntuaciones muy altas, pero tiene que ver con que la base de datos (nuestro csv) tiene muy pocos repositorios y usuarios cargados.
Validemos el error
Sobre el test set comparemos el mean squared error con el conjunto de entrenamiento:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
def get_mse(preds, actuals): if preds.shape[1] != actuals.shape[1]: actuals = actuals.T preds = preds[actuals.nonzero()].flatten() actuals = actuals[actuals.nonzero()].flatten() return mean_squared_error(preds, actuals) get_mse(users_predictions, ratings_train) # Realizo las predicciones para el test set users_predictions_test = sim_matrix.dot(ratings) / np.array([np.abs(sim_matrix).sum(axis=1)]).T users_predictions_test = users_predictions_test[24:30,:] get_mse(users_predictions_test, ratings_test) |
3.39
4.72
Vemos que para el conjunto de train y test el MAE es bastante cercano. Un indicador de que no tiene buenas predicciones sería si el MAE en test fuera 2 veces más (ó la mitad) del valor del de train.
Hay más…
En la notebook completa -en Github-, encontrarás más opciones de crear el Recomendador, utilizando K-Nearest Neighbors como estimador, y también usando la similitud entre ítems (ítem-based). Sin embargo para los fines de este artículo espero haber mostrado el funcionamiento básico del Collaborative Filtering. Te invito a que luego lo explores por completo.
Conclusiones
Vimos que es relativamente sencillo crear un sistema de recomendación en Python y con Machine Learning. Como muchas veces en Data-Science una de las partes centrales para que el modelo funcione se centra en tener los datos correctos y un volumen alto. También es central el valor que utilizaremos como “rating” -siendo una valoración real de cada usuario ó un valor artificial que creemos adecuado-. Recuerda que me refiero a rating como ese puntaje que surge de la intersección entre usuario e ítems en nuestro dataset. Luego será cuestión de evaluar entre las opciones de motores user-based, ítem-based y seleccionar la que menor error tenga. Y no descartes probar en el “mundo real” y ver qué porcentaje de aciertos (o feedback) te dan los usuarios reales de tu aplicación!
Existen algunas librerías que se utilizan para crear motores de recomendación como “surprise”. También te sugiero que las explores.
Por último, decir que -como en casi todo el Machine Learning- tenemos la opción de crear Redes Neuronales con Embeddings como recomendados y hasta puede que sean las que mejor funcionan para resolver esta tarea!… pero queda fuera del alcance de este tutorial. Dejaré algún enlace por ahí abajo 😉
Forma parte del Blog!
Recibe los próximos artículos sobre Machine Learning, estrategias, teoría y código Python en tu casilla de correo!
NOTA: algunos usuarios reportaron que el email de confirmación y/o posteriores a la suscripción entraron en su carpeta de SPAM. Te sugiero que revises y recomiendo que agregues nuestro remitente a tus contactos para evitar problemas. Gracias!
Recursos del Artículo
Descarga los 3 archivos csv y el Notebook con el ejercicio Python completo (y adicionales!)
- users.csv
- repos.csv
- ratings.csv
- Ejercicio-Sistemas-de-Recomendación – Jupyter Notebook
Muy completo e interesante, Juan!
Hola David, gracias! Saludos
Gracias por mantenernos informados Juan, abrazo
Hola Hector, gracias por participar en el Blog!, abrazo
Hola Juan, me encanta tu blog!!!
Te quería hacer unas consulta, arranqué un curso de data mining, y la parte practica la hacen con wekas y R. Todavía no termino de entender las diferencias entre, data mining / data science, pero veo que hay métodos que son parecidos en ambos, como k-meas, arboles de decisión, clustering, etc…
Tengo 2 consultas:
1- Hay alguna herramienta de python o notebook de júpiter para hacer lo mismo que con R o wekas?
2- Cuando termine el curso de data mining, puedo empezar con tu guía de aprendizaje inicial de ML? son lo mismos contenidos que veré? o es otra disciplina?. No si me expliqué.. 😛
Hola Walter, gracias por escribir. Se me ocurre responderte que una de las librerías usadas en python (y usada en este blog) es la de sklearn que tiene muchas de las implementaciones de los modelos y algoritmos de Machine Learning para DataScience.
En cuanto a la guía creo que te puede ayudar pues tiene bastante equilibrio -creo yo- entre teoría y práctica en python y con Jupyter Notebooks, visualizaciones gráficas, descargar los datasets con casos prácticos.
Espero haber ayudado!,
Saludos
Hola Juan, gracias por tu respuesta, genial, voy a enfocarme en sklearn, voy a ir viendo en paralelo la guía desde el comienzo, gracias por compartir todo lo que sabes, saludos!
aunque el concepto queda claro, y lo importante es saber el porcentaje de espacios vacios..
la mencion que haces de sparsity es incorrecta.
density (lo que tu llamas sparsity) es 6.43 %
sparsity = 100(%)- 6.43% = 93.57 %
saludos,
Jose
Hola Jose, gracias por el comentario, estás en lo cierto! Luego lo editaré, saludos!
muy bien, no es un “error” importante,
por otra parte si mencionar que los posts que haces son en general de muy buena calidad! enhorabuena!
Un saludo,
Jose
Muchas gracias Juan por compartir ese conocimiento!! Saludos desde Colombia
Hola que tal, veo que el sistema de recomendacion te recomienda 3 repositorios, los cuales son las 3 mas altas puntuaciones para tu usuario, pero esos repositorios ya habian sido calificadas por ti, por lo que el sistema no deberia recomendar repositorios no calificados por ti?. saludos
Excelente artículo, y no existe el mismo codigo en R?
Gracias. No tengo el Código en R. Por el momento todos los ejercicios son Python.
Saludos
Hola, que tal? Te consulto
Porque para train es??:
users_predictions = sim_matrix_train.dot(ratings_train) / np.array([np.abs(sim_matrix_train).sum(axis=1)]).T
Y para test es??:
users_predictions_test = sim_matrix.dot(ratings) / np.array([np.abs(sim_matrix).sum(axis=1)]).T
users_predictions_test = users_predictions_test[24:30,:]
En vez de ser??:
users_predictions_test = sim_matrix_test.dot(ratings_test) / np.array([np.abs(sim_matrix_test).sum(axis=1)]).T
Gracias desde ya
Pues puede que estés en lo correcto 😀
Hola, Felicitaciones y Gracias por el blog.
Como puedo conseguir la lista de usuarios de github, con los repositorios x usuario.
Hola Juan! un placer encontrar tu blog. Es lo que necesitaba desde hace un tiempo. Estoy aprendiendo Python y Machine learning.
Una consulta super básica, No he podido descargar los archivos .csv
automaticamente me lleva a github pero no puedo extraerlos ni con el copy (pegando en excel me pega solo el texto)
Me encantaria hacer el ejercicio por mi cuenta pero requiero la base de datos.
Te dejo el mail por las dudas.
Saludos y muchas gracias por invertir tu tiempo en la comunidad.
Hola Juan, gracias por escribir, te paso los archivos por email, Saludos
Hola, excelente blog, tengo una pequeña consulta,
USUARIO_EJEMPLO = ‘jbagnato’ # debe existir en nuestro dataset de train!
data = df_users[df_users[‘username’] == USUARIO_EJEMPLO]
usuario_ver = data.iloc[0][‘userId’] -1 # resta 1 para obtener el index de pandas
user0=users_predictions.argsort()[usuario_ver]
En esta parte cuando se realiza el ejemplo se ingresa el nombre del usuario, como cambiaría si solo se tuviera los id de los usuarios y desconocemos el nombre para realizar las predicciones?
Muchas gracias!
El id lo utiliza en la línea:
usuario_ver = data.iloc[0][‘userId’] -1¿te referías a ese id?
Saludos
Hola que tal, veo que el sistema de recomendacion te recomienda 3 repositorios, los cuales son las 3 mas altas puntuaciones para tu usuario, pero esos repositorios ya habian sido calificadas por ti, por lo que el sistema no deberia recomendar repositorios no calificados por ti?. saludos
Hola Eduardo, gracias por tu comentario. Sí, es correcto lo que dices, esos repos ya estaban calificados, por lo que realmente habría que hacer, es tomar más valores (ranciados) de las predicciones y excluir los que el usuario YA tiene.
Saludos!
Hola, soy algo nuevo en pytho, y tengo dos dudas, la primera, si los rating están cambiando regularmente, es decir se agregan o modifican, el mdelo no tomaría esos rating? es decir, el conjunto de datos utilizados para entrenamiento sirve tambien para predicción y este no cambia? o se ajusta y puedo agregar nuevos repositorios y ratings siempre que quiera predecir, y la segunda es más sencilla, este modelo se puede exportar, si es así, como se hace, solo se exportar con tensorflow
Gracias!