
 by
by Contrarrestar problemas con clases desbalanceadas
Estrategias para resolver desequilibrio de datos en Python con la librería imbalanced-learn.

Tabla de contenidos:
- ¿Qué son las clases desequilibradas en un dataset?
- Métricas y Confusión Matrix
- Ejercicio con Python
- Estrategias
- Modelo sin modificar
- Penalización para compensar / Métricas
- Resampling y Muestras sintéticas
- subsampling
- oversamplig
- combinación
- Balanced Ensemble
Empecemos!
¿Qué son los problemas de clasificación de Clases desequilibradas? (imbalanced data)
En los problemas de clasificación en donde tenemos que etiquetar por ejemplo entre “spam” o “not spam” ó entre múltiples categorías (coche, barco, avión) solemos encontrar que en nuestro conjunto de datos de entrenamiento contamos con que alguna de las clases de muestra es una clase “minoritaria” es decir, de la cual tenemos muy poquitas muestras. Esto provoca un desbalanceo en los datos que utilizaremos para el entrenamiento de nuestra máquina.
Un caso evidente es en el área de Salud en donde solemos encontrar conjuntos de datos con miles de registros con pacientes “negativos” y unos pocos casos positivos es decir, que padecen la enfermedad que queremos clasificar.
Otros ejemplos suelen ser los de Detección de fraude donde tenemos muchas muestras de clientes “honestos” y pocos casos etiquetados como fraudulentos. Ó en un funnel de marketing, en donde por lo general tenemos un 2% de los datos de clientes que “compran” ó ejecutan algún tipo de acción (CTA) que queremos predecir.
¿Cómo nos afectan los datos desbalanceados?
Por lo general afecta a los algoritmos en su proceso de generalización de la información y perjudicando a las clases minoritarias. Esto suena bastante razonable: si a una red neuronal le damos 990 de fotos de gatitos y sólo 10 de perros, no podemos pretender que logre diferenciar una clase de otra. Lo más probable que la red se limite a responder siempre “tu foto es un gato” puesto que así tuvo un acierto del 99% en su fase de entrenamiento.
Métricas y Confusion Matrix
Como decía, si medimos la efectividad de nuestro modelo por la cantidad de aciertos que tuvo, sólo teniendo en cuenta a la clase mayoritaria podemos estar teniendo una falsa sensación de que el modelo funciona bien.
Para poder entender esto un poco mejor, utilizaremos la llamada “Confusión matrix” que nos ayudará a comprender las salidas de nuestra máquina:
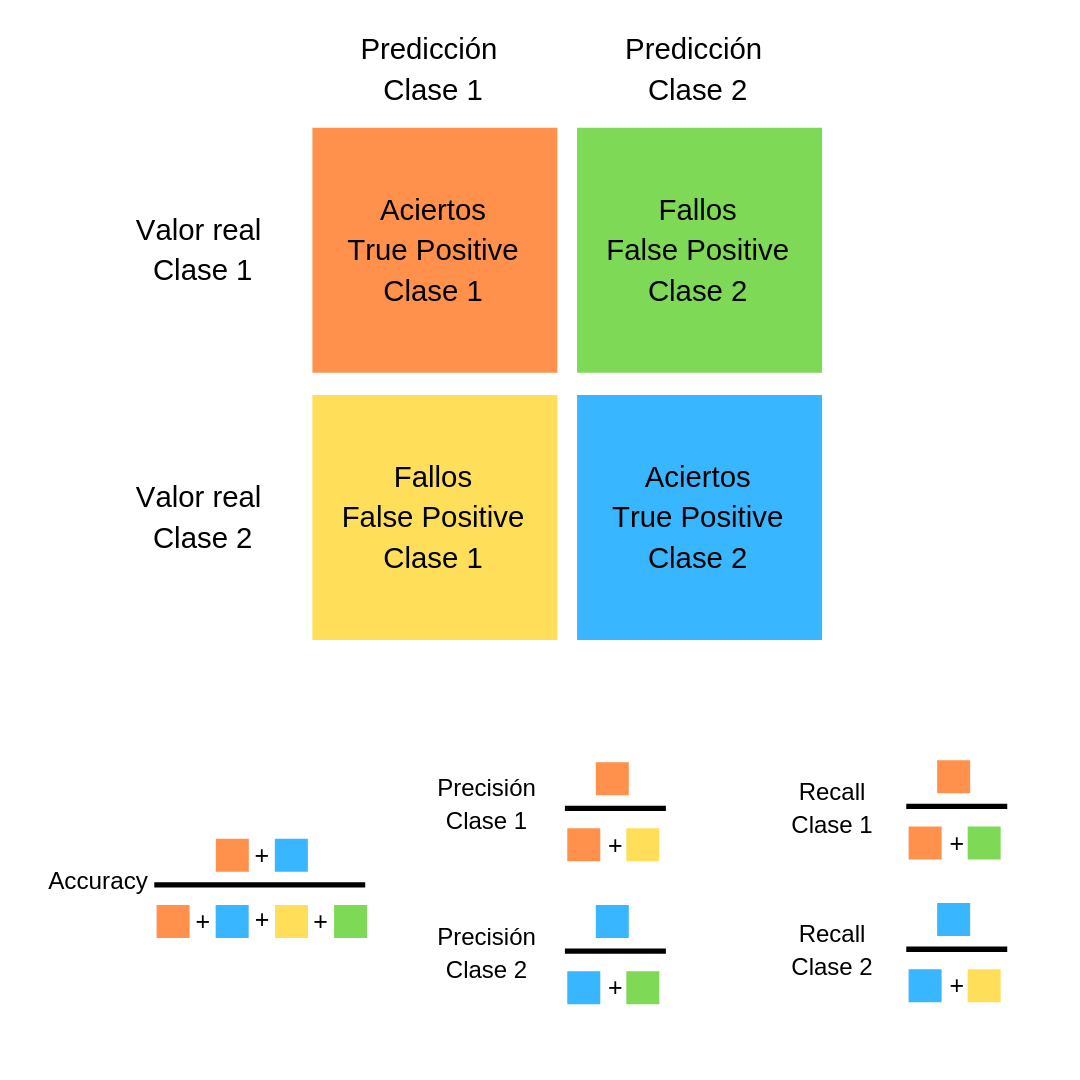
Y de aqui salen nuevas métricas: precisión y recall
Veamos la Confusion matrix con el ejemplo de las predicciones de perro y gato.

Breve explicación de estás métricas:
La Accuracy del modelo es básicamente el numero total de predicciones correctas dividido por el número total de predicciones. En este caso da 99% cuando no hemos logrado identificar ningún perro.
La Precisión de una clase define cuan confiable es un modelo en responder si un punto pertenece a esa clase. Para la clase gato será del 99% sin embargo para la de perro será 0%.
El Recall de una clase expresa cuan bien puede el modelo detectar a esa clase. Para gatos será de 1 y para perros 0.
El F1 Score de una clase es dada por la media harmonía de precisión y recall (2 x precision x recall / (precision+recall)) digamos que combina precisión y recall en una sola métrica. En nuestro caso daría cero para perros!.
Tenemos cuatro casos posibles para cada clase:
- Alta precision y alto recall: el modelo maneja perfectamente esa clase
- Alta precision y bajo recall: el modelo no detecta la clase muy bien, pero cuando lo hace es altamente confiable.
- Baja precisión y alto recall: La clase detecta bien la clase pero también incluye muestras de otras clases.
- Baja precisión y bajo recall: El modelo no logra clasificar la clase correctamente.
Cuando tenemos un dataset con desequilibrio, suele ocurrir que obtenemos un alto valor de precisión en la clase Mayoritaria y un bajo recall en la clase Minoritaria
MUY importante que conozcas los conceptos de Train, test y validación cruzada.
Vamos al Ejercicio con Python!
Usaremos el set de datos Credit Card Fraut Detection de la web de Kaggle. Son 66 MB que al descomprimir ocuparán 150MB. Usaremos el archivo creditcard.csv. Este dataset consta de 285.000 filas con 31 columnas (features). Como la información es privada, no sabemos realmente que significan los features y están nombradas como V1, V2, V3, etc. excepto por las columnas Time y Amount (el importe de la transacción). Y nuestras clases son 0 y 1 correspondiendo con “transacción Normal” ó “Hubo Fraude”. Como podrán imaginar, el set de datos está muy desequilibrado y tendremos muy pocas muestras etiquetadas como fraude.
La notebook que acompaña este artículo puedes verla aquí en Github y en los recursos, al final del artículo.
También debo decir que no nos centraremos tanto en la elección del modelo ni en su configuración y tuneo si no que nos centraremos en aplicar las diversas estrategias para mejorar los resultados a pesar del desequilibrio de clases.
Requerimientos Técnicos
Necesitaremos tener Python 3.6 en el sistema y como lo haremos en una Notebook Jupyter, recomiendo tener instalada Anaconda.
Instala la librería de Imbalanced Learn desde linea de comando con: (toda la documentación en la web oficial imblearn)
|
1 |
pip install -U imbalanced-learn |
Veamos el dataset
Análisis exploratorio, para comprobar el desequilibrio entre las clases
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns from sklearn.metrics import confusion_matrix from sklearn.metrics import classification_report from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.decomposition import PCA from sklearn.tree import DecisionTreeClassifier from pylab import rcParams from imblearn.under_sampling import NearMiss from imblearn.over_sampling import RandomOverSampler from imblearn.combine import SMOTETomek from imblearn.ensemble import BalancedBaggingClassifier from collections import Counter |
Luego de importar las librerías que usaremos, cargamos con pandas el dataframe y vemos las primeras filas:
|
1 2 |
df = pd.read_csv("creditcard.csv") # read in data downloaded to the local directory df.head(n=5) |
Veamos de cuantas filas tenemos y cuantas hay de cada clase:
|
1 2 |
print(df.shape) print(pd.value_counts(df['Class'], sort = True)) |
(284807, 31)
0 284315
1 492
Name: Class, dtype: int64
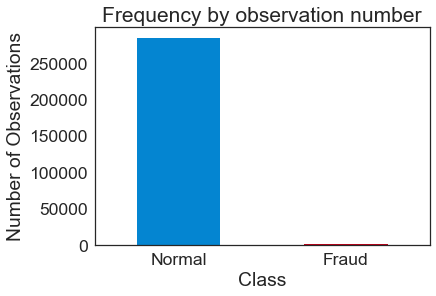
Vemos que son 284.807 filas y solamente 492 son la clase minoritaria con los casos de fraude. Representan el 0,17% de las muestras.
|
1 2 3 4 5 6 |
count_classes = pd.value_counts(df['Class'], sort = True) count_classes.plot(kind = 'bar', rot=0) plt.xticks(range(2), LABELS) plt.title("Frequency by observation number") plt.xlabel("Class") plt.ylabel("Number of Observations"); |
Estrategias para el manejo de Datos Desbalanceados:
Tenemos diversas estrategias para tratar de mejorar la situación. Las comentaremos brevemente y pasaremos a la acción (al código!) a continuación.
- Ajuste de Parámetros del modelo: Consiste en ajustar parametros ó metricas del propio algoritmo para intentar equilibrar a la clase minoritaria penalizando a la clase mayoritaria durante el entrenamiento. Ejemplos on ajuste de peso en árboles, también en logisticregression tenemos el parámetro class_weight= “balanced” que utilizaremos en este ejemplo. No todos los algoritmos tienen estas posibilidades. En redes neuronales por ejemplo podríamos ajustar la métrica de Loss para que penalice a las clases mayoritarias.
- Modificar el Dataset: podemos eliminar muestras de la clase mayoritaria para reducirlo e intentar equilibrar la situación. Tiene como “peligroso” que podemos prescindir de muestras importantes, que brindan información y por lo tanto empeorar el modelo. Entonces para seleccionar qué muestras eliminar, deberíamos seguir algún criterio. También podríamos agregar nuevas filas con los mismos valores de las clases minoritarias, por ejemplo cuadriplicar nuestras 492 filas. Pero esto no sirve demasiado y podemos llevar al modelo a caer en overfitting.
- Muestras artificiales: podemos intentar crear muestras sintéticas (no idénticas) utilizando diversos algoritmos que intentan seguir la tendencia del grupo minoritario. Según el método, podemos mejorar los resultados. Lo peligroso de crear muestras sintéticas es que podemos alterar la distribución “natural” de esa clase y confundir al modelo en su clasificación.
- Balanced Ensemble Methods: Utiliza las ventajas de hacer ensamble de métodos, es decir, entrenar diversos modelos y entre todos obtener el resultado final (por ejemplo “votando”) pero se asegura de tomar muestras de entrenamiento equilibradas.
Apliquemos estas técnicas de a una a nuestro código y veamos los resultados.
PERO… antes de empezar, ejecutaremos el modelo de Regresión Logística “desequilibrado”, para tener un “baseline”, es decir unas métricas contra las cuales podremos comparar y ver si mejoramos.
Probando el Modelo “a secas” -sin estrategias-
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
#definimos nuestras etiquetas y features y = df['Class'] X = df.drop('Class', axis=1) #dividimos en sets de entrenamiento y test X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7) #creamos una función que crea el modelo que usaremos cada vez def run_model(X_train, X_test, y_train, y_test): clf_base = LogisticRegression(C=1.0,penalty='l2',random_state=1,solver="newton-cg") clf_base.fit(X_train, y_train) return clf_base #ejecutamos el modelo "tal cual" model = run_model(X_train, X_test, y_train, y_test) #definimos funciona para mostrar los resultados def mostrar_resultados(y_test, pred_y): conf_matrix = confusion_matrix(y_test, pred_y) plt.figure(figsize=(12, 12)) sns.heatmap(conf_matrix, xticklabels=LABELS, yticklabels=LABELS, annot=True, fmt="d"); plt.title("Confusion matrix") plt.ylabel('True class') plt.xlabel('Predicted class') plt.show() print (classification_report(y_test, pred_y)) pred_y = model.predict(X_test) mostrar_resultados(y_test, pred_y) |
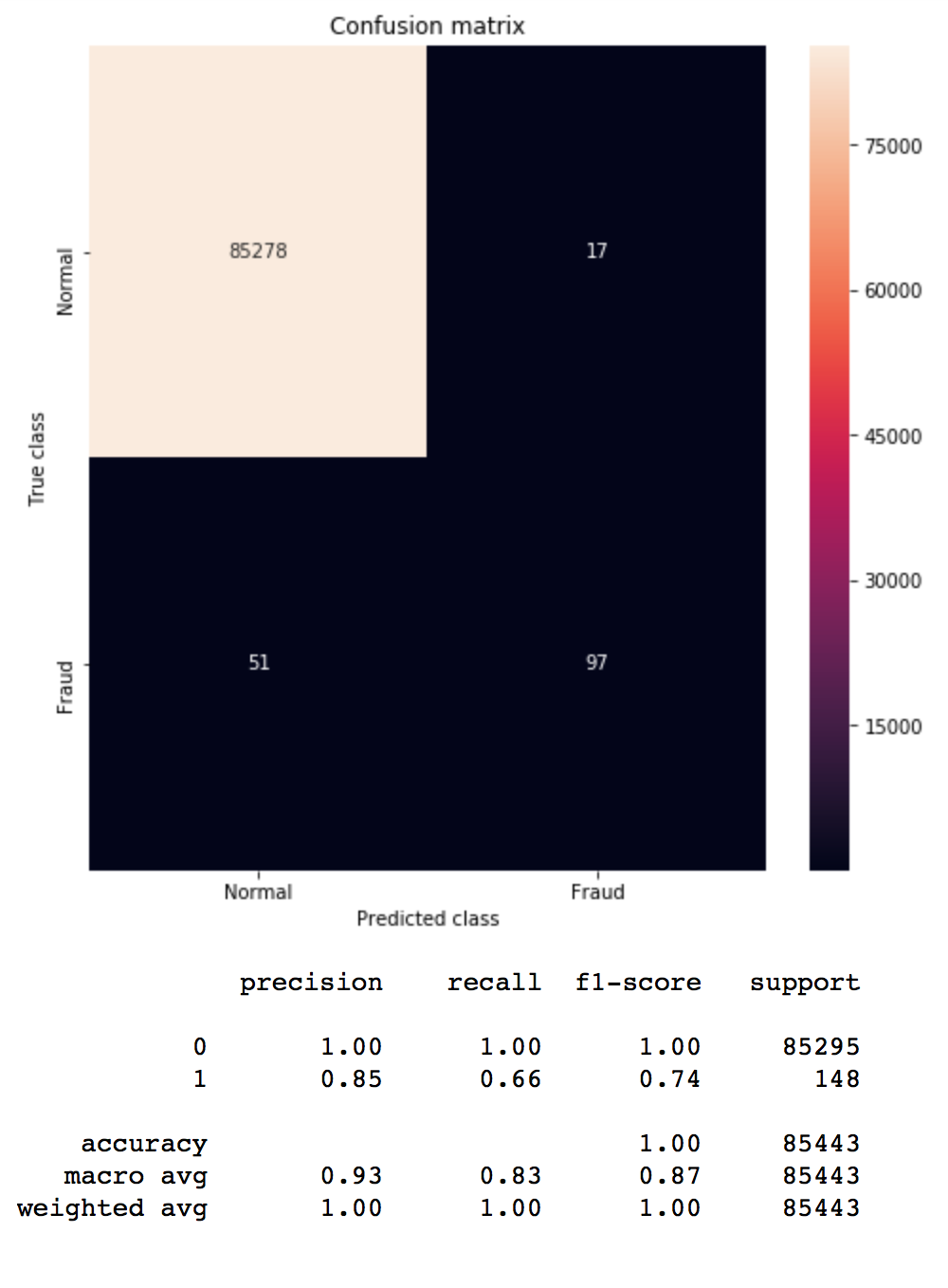
Aqui vemos la confusion matrix y en la clase 2 (es lo que nos interesa detectar) vemos 51 fallos y 97 aciertos dando un recall de 0.66 y es el valor que queremos mejorar. También es interesante notar que en la columna de f1-score obtenemos muy buenos resultados PERO que realmente no nos deben engañar… pues están reflejando una realidad parcial. Lo cierto es que nuestro modelo no es capaz de detectar correctamente los casos de Fraude.
Estrategia: Penalización para compensar
Utilizaremos un parámetro adicional en el modelo de Regresión logística en donde indicamos weight = “balanced” y con esto el algoritmo se encargará de equilibrar a la clase minoritaria durante el entrenamiento. Veamos:
|
1 2 3 4 5 6 7 8 |
def run_model_balanced(X_train, X_test, y_train, y_test): clf = LogisticRegression(C=1.0,penalty='l2',random_state=1,solver="newton-cg",class_weight="balanced") clf.fit(X_train, y_train) return clf model = run_model_balanced(X_train, X_test, y_train, y_test) pred_y = model.predict(X_test) mostrar_resultados(y_test, pred_y) |
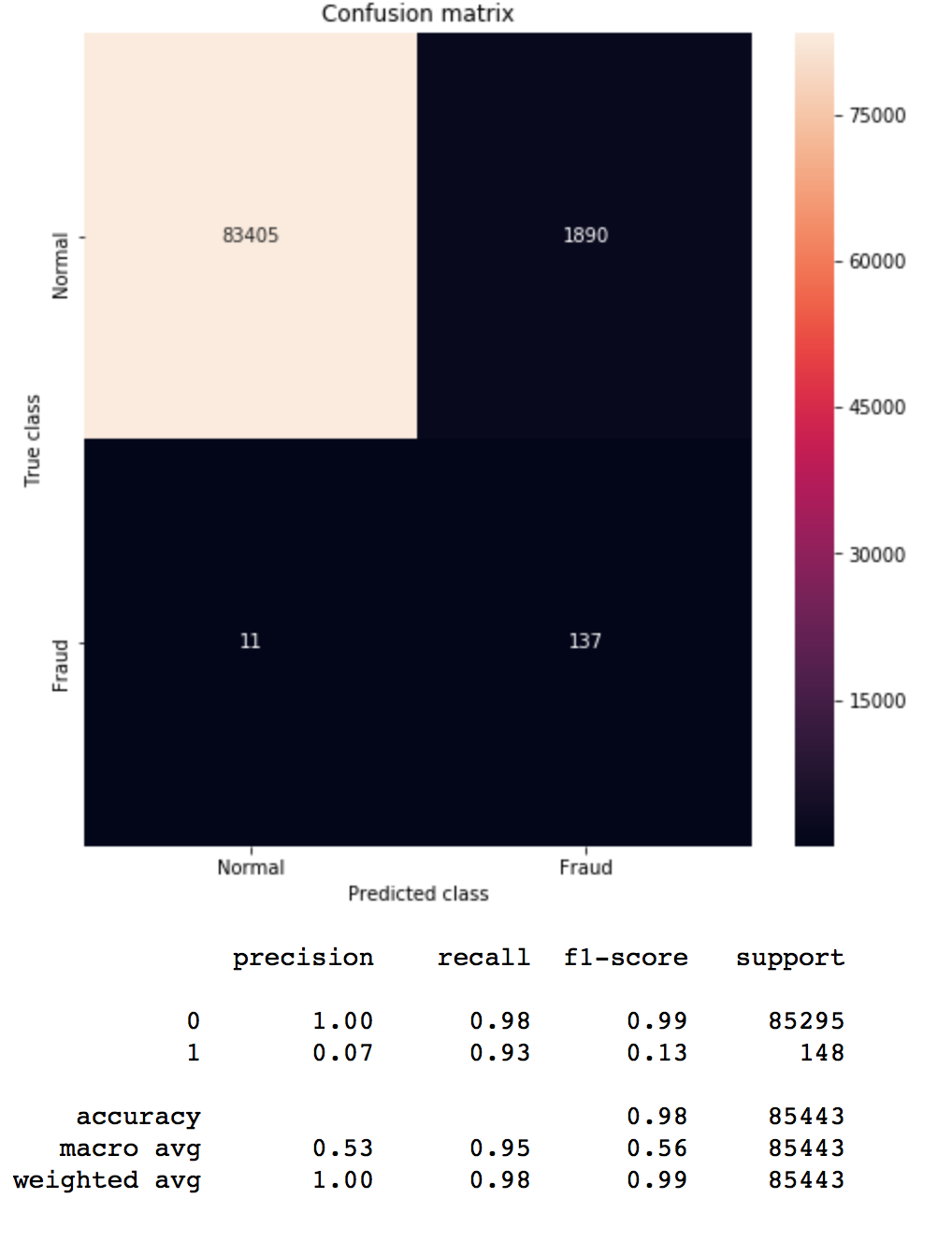
Ahora vemos una NOTABLE MEJORA! en la clase 2 -que indica si hubo fraude-, se han acertado 137 muestras y fallado en 11, dando un recall de 0.93 !! y sólo con agregar un parámetro al modelo 😉 También notemos que en la columna de f1-score parecería que hubieran “empeorado” los resultados… cuando realmente estamos mejorando la detección de casos fraudulentos. Es cierto que aumentan los Falsos Positivos y se han etiquetado 1890 muestras como Fraudulentas cuando no lo eran… pero ustedes piensen… ¿qué prefiere la compañía bancaria? ¿tener que revisar esos casos manualmente ó fallar en detectar los verdaderos casos de fraude?
Sigamos con más métodos:
Estrategia: Subsampling en la clase mayoritaria
Lo que haremos es utilizar un algoritmo para reducir la clase mayoritaria. Lo haremos usando un algoritmo que hace similar al k-nearest neighbor para ir seleccionando cuales eliminar. Fijemonos que reducimos bestialmente de 199.020 muestras de clase cero (la mayoría) y pasan a ser 688. y Con esas muestras entrenamos el modelo.
|
1 2 3 4 5 6 7 8 9 |
us = NearMiss(ratio=0.5, n_neighbors=3, version=2, random_state=1) X_train_res, y_train_res = us.fit_sample(X_train, y_train) print ("Distribution before resampling {}".format(Counter(y_train))) print ("Distribution after resampling {}".format(Counter(y_train_res))) model = run_model(X_train_res, X_test, y_train_res, y_test) pred_y = model.predict(X_test) mostrar_resultados(y_test, pred_y) |
Distribution before resampling Counter({0: 199020, 1: 344})
Distribution after resampling Counter({0: 688, 1: 344})
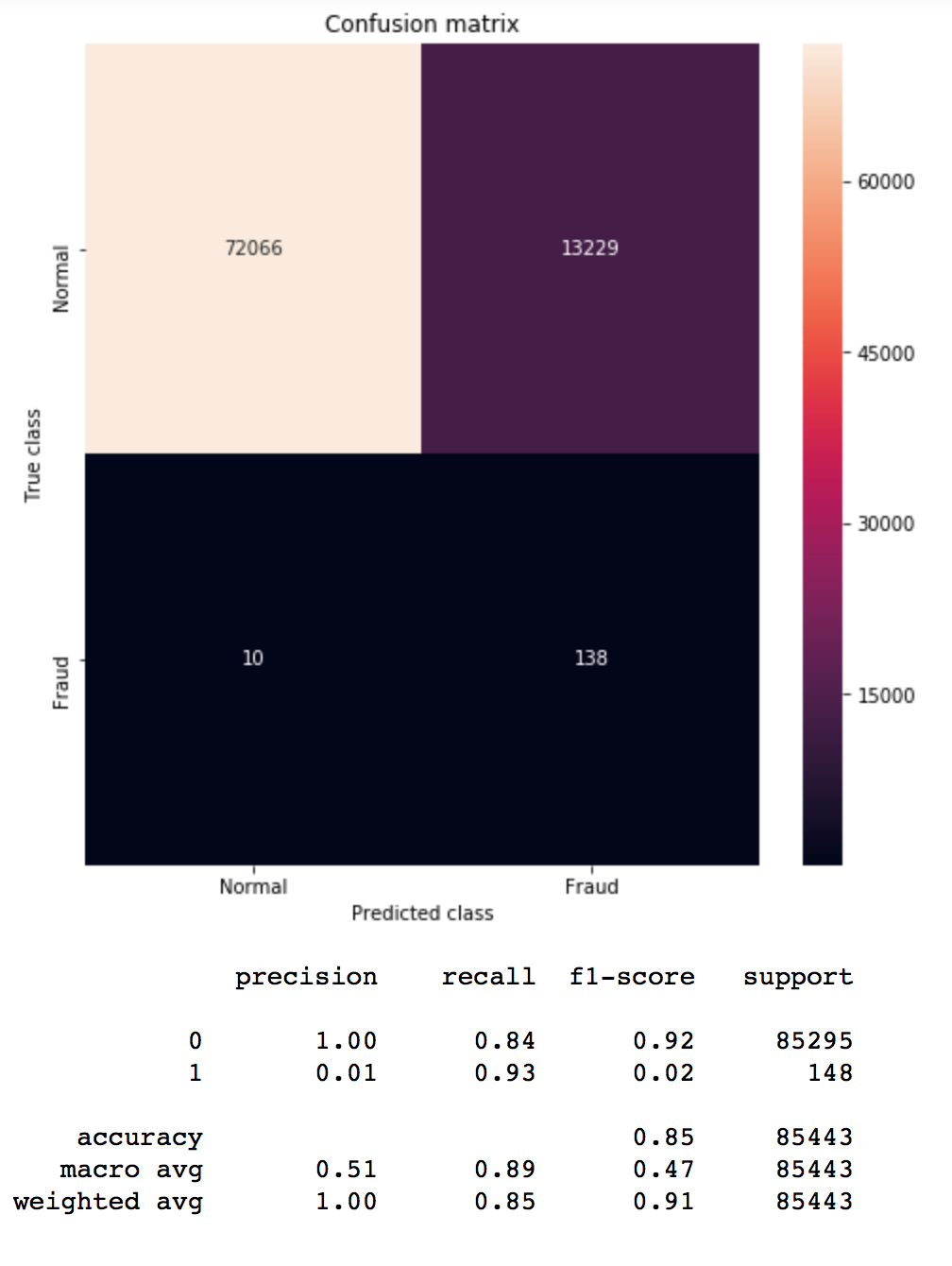
También vemos que obtenemos muy buen resultado con recall de 0.93 aunque a costa de que aumentaran los falsos positivos.
Estrategia: Oversampling de la clase minoritaria
En este caso, crearemos muestras nuevas “sintéticas” de la clase minoritaria. Usando RandomOverSampler. Y vemos que pasamos de 344 muestras de fraudes a 99.510.
|
1 2 3 4 5 6 7 8 9 |
os = RandomOverSampler(ratio=0.5) X_train_res, y_train_res = os.fit_sample(X_train, y_train) print ("Distribution before resampling {}".format(Counter(y_train))) print ("Distribution labels after resampling {}".format(Counter(y_train_res))) model = run_model(X_train_res, X_test, y_train_res, y_test) pred_y = model.predict(X_test) mostrar_resultados(y_test, pred_y) |
|
1 |
Distribution before resampling Counter({0: 199020, 1: 344})<br> Distribution after resampling Counter({0: 199020, 1: 99510}) |
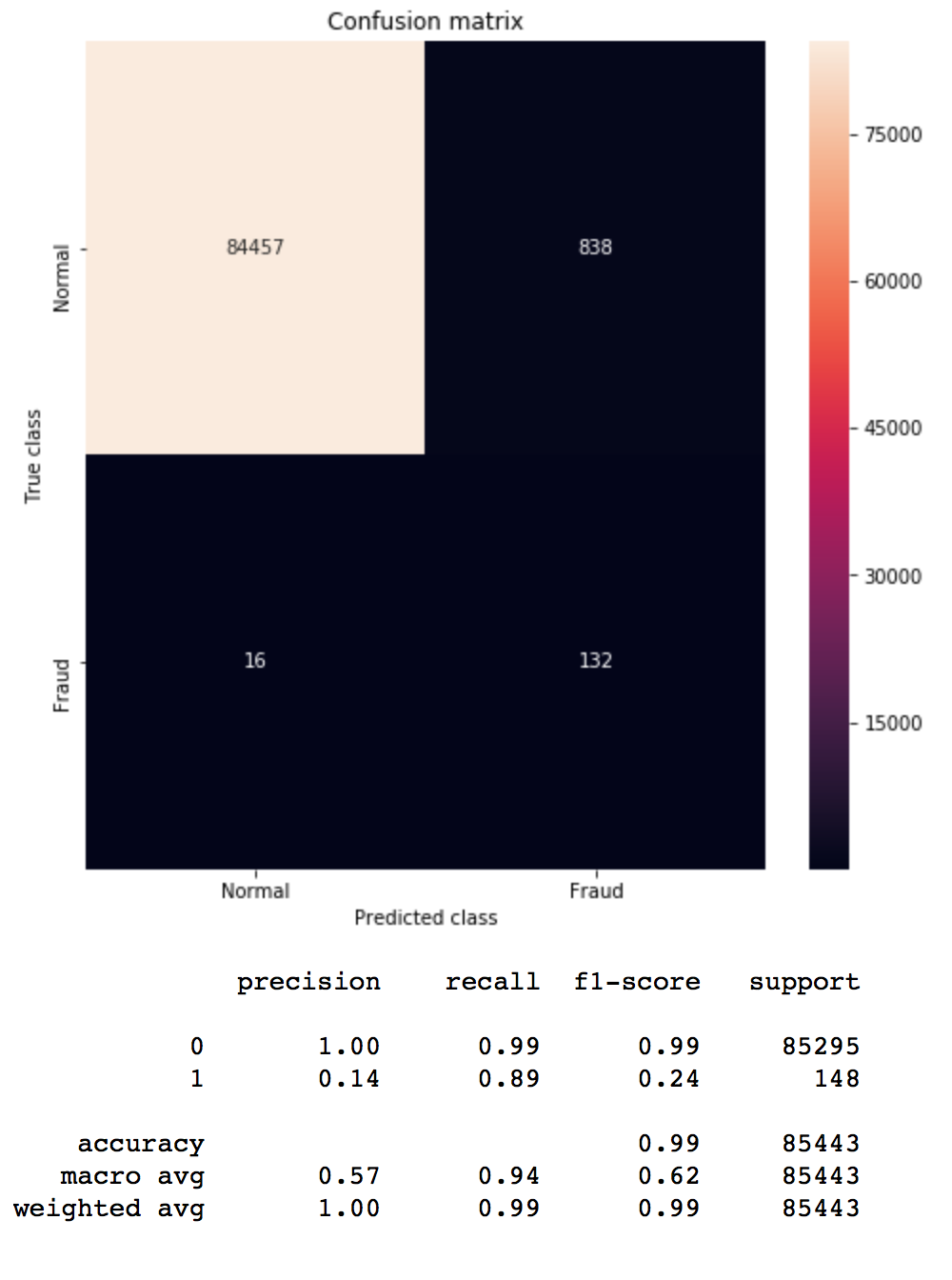
Tenemos un 0.89 de recall para la clase 2 y los Falsos positivos son 838. Nada mal.
Estrategia: Combinamos resampling con Smote-Tomek
Ahora probaremos una técnica muy usada que consiste en aplicar en simultáneo un algoritmo de subsampling y otro de oversampling a la vez al dataset. En este caso usaremos SMOTE para oversampling: busca puntos vecinos cercanos y agrega puntos “en linea recta” entre ellos. Y usaremos Tomek para undersampling que quita los de distinta clase que sean nearest neighbor y deja ver mejor el decisión boundary (la zona limítrofe de nuestras clases).
|
1 2 3 4 5 6 7 8 9 |
os_us = SMOTETomek(ratio=0.5) X_train_res, y_train_res = os_us.fit_sample(X_train, y_train) print ("Distribution before resampling {}".format(Counter(y_train))) print ("Distribution after resampling {}".format(Counter(y_train_res))) model = run_model(X_train_res, X_test, y_train_res, y_test) pred_y = model.predict(X_test) mostrar_resultados(y_test, pred_y) |
|
1 |
Distribution labels before resampling Counter({0: 199020, 1: 344})<br> Distribution after resampling Counter({0: 198194, 1: 98684}) |
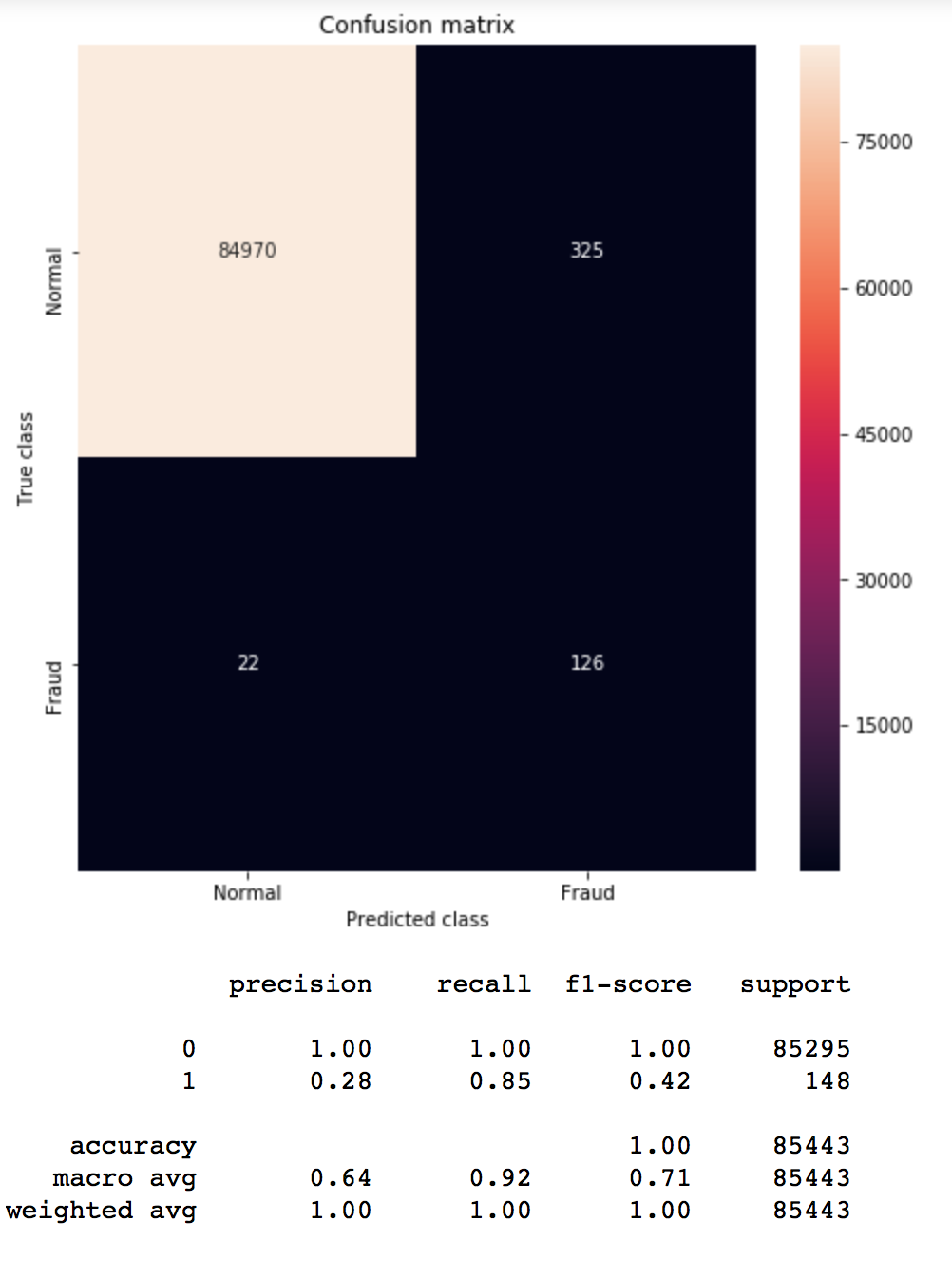
En este caso seguimos teniendo bastante buen recall 0.85 de la clase 2 y vemos que los Falsos positivos de la clase 1 son bastante pocos, 325 (de 85295 muestras).
Estrategia: Ensamble de Modelos con Balanceo
Para esta estrategia usaremos un Clasificador de Ensamble que utiliza Bagging y el modelo será un DecisionTree. Veamos como se comporta:
|
1 2 3 4 5 6 7 8 9 |
bbc = BalancedBaggingClassifier(base_estimator=DecisionTreeClassifier(), sampling_strategy='auto', replacement=False, random_state=0) #Train the classifier. bbc.fit(X_train, y_train) pred_y = bbc.predict(X_test) mostrar_resultados(y_test, pred_y) |
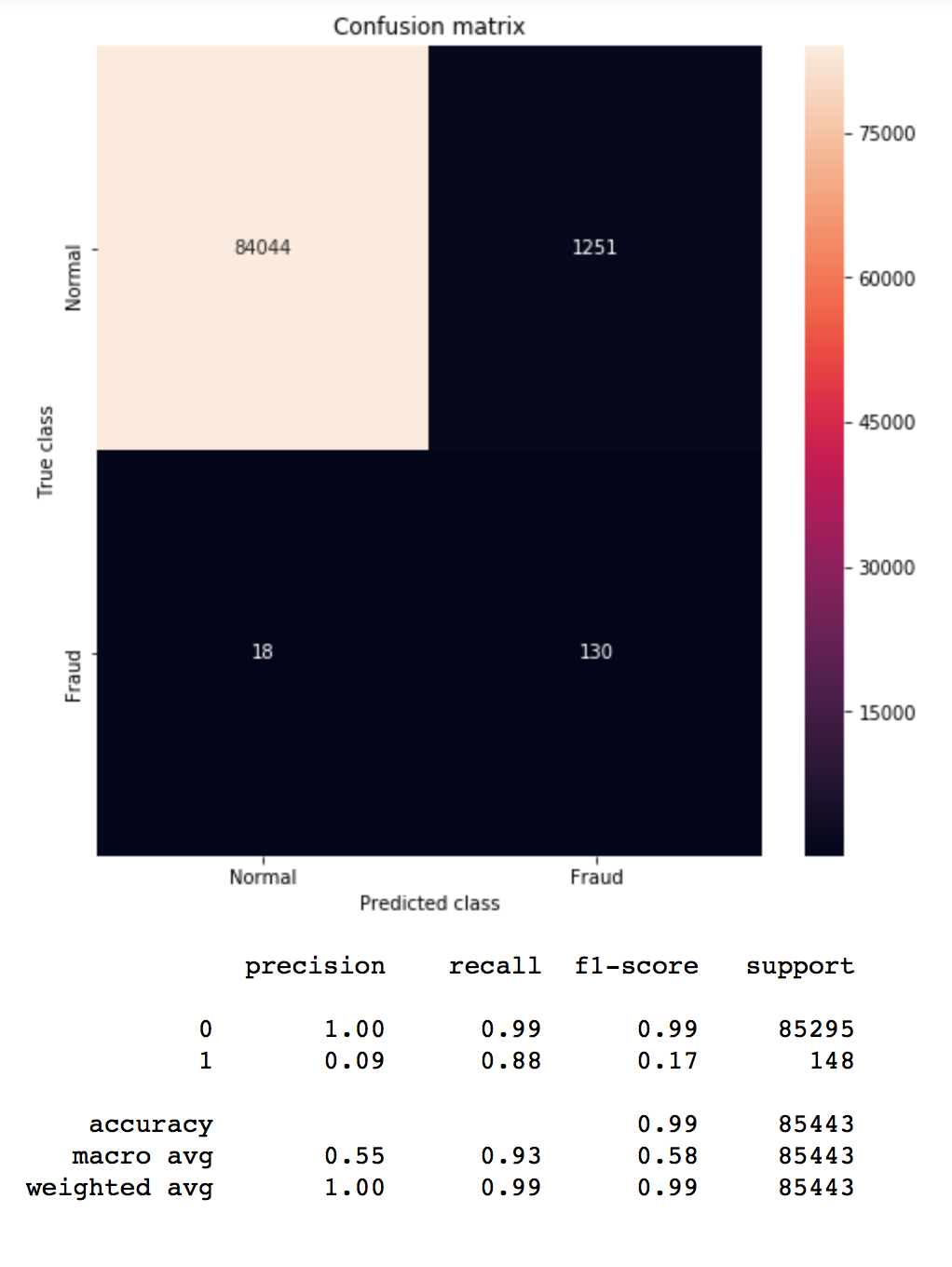
Tampoco está mal. Vemos siempre mejora con respecto al modelo inicial con un recall de 0.88 para los casos de fraude.
Resultados de las Estrategias
Veamos en una tabla, ordenada de mejor a peor los resultados obtenidos.
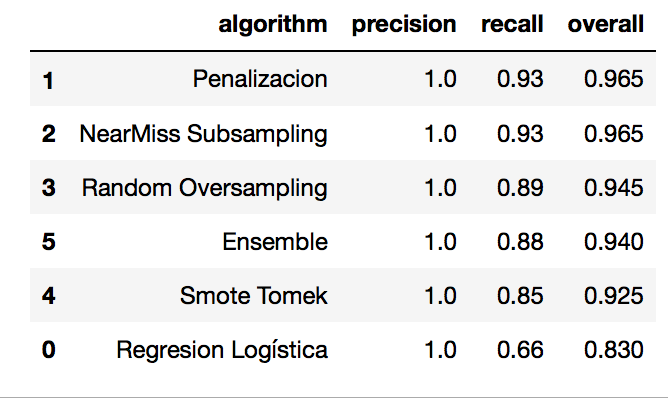
Vemos que en nuestro caso las estrategias de Penalización y Subsampling nos dan el mejor resultado, cada una con un recall de 0.93.
Pero quedémonos con esto: Con cualquiera de las técnicas que aplicamos MEJORAMOS el modelo inicial de Regresión logística, que lograba un 0.66 de recall para la clase de Fraude. Y no olvidemos que hay un tremendo desbalance de clases en el dataset!
IMPORTANTE: esto no quiere decir que siempre hay que aplicar Penalización ó NearMiss Subsampling!, dependerá del caso, del desbalanceo y del modelo (en este caso usamos regresión logística, pero podría ser otro!).
Conclusiones
Es muy frecuente encontrarnos con datasets con clases desbalanceadas, de hecho… lo más raro sería encontrar datasets bien equilibrados.
A lo largo de estos 2 años de vida del blog la pregunta más frecuente que he recibido creo que a sido “¿cómo hago cuando tengo pocas muestras de una clase?”. Mi primera respuesta y la de sentido común es “Sal a la calle y consigue más muestras!” pero la realidad es que no siempre es posible conseguir más datos de las clases minoritarias (como por ejemplo en Casos de Salud).
En el artículo de hoy vimos diversas estrategias a seguir para combatir esta problemática: eliminar muestras del set mayoritario, crear muestras sintéticas con algún criterio, ensamble y penalización.
Además revisamos la Matriz de Confusión y comprendimos que las métricas pueden ser engañosas… si miramos a nuestros aciertos únicamente, puede que pensemos que tenemos un buen clasificador, cuando realmente está fallando.
Súmate a los suscriptores del Blog
Recibe los próximos artículos sobre Machine Learning, estrategias, teoría y código Python en tu casilla de correo!
NOTA: muchos usuarios reportaron que el email de confirmación y/o posteriores a la suscripción entraron en su carpeta de SPAM. Te sugiero que revises y recomiendo que agregues nuestro remitente a tus contactos para evitar problemas. Gracias!
Recursos
- Notebook con todo el ejercicio y más cositas
- Descarga el dataset desde Kaggle
- Librería de Imbalanced-Learn



Buen tema, gracias por la clara explicación como siempre. Sería interesante ver el tema de datos desbalanceados aplicado a CNN para clasificación de objetos.
Buen tema y como siempre claramente explicado. Sería interesante abordar el tema de clases desbalanceadas aplicado a CNN para clasificación de datos. Cuáles de las alternativas estarían disponibles en ese caso.
Gracias
Hola Bernardo, gracias por escribir, pues para CNN se utiliza algo llamado Data Augmentation y consiste en generar imágenes variadas de las clases con menos muestras, por ejemplo, con algo de zoom, imagenes rotadas, con algo de desenfoque y combinaciones de estas.
En la librería de fast.ai vienen estas funciones hechas y son muy útiles! De hecho puede que lo comente en algún artículo más adelante.
Saludos
Muy buena info, me sacó de un apuro!
Qué bien saberlo Alex! Saludos
Muchisimas gracias, la verdad es que me está resultando de gran ayuda para iniciarme en todo esto.
Si me permites quería consultarte una duda, cuando ejecuto el código de arriba me da un error con plt.xticks(range(2), labels), me dice algo de este estilo –> name ‘LABELS’ is not defined
¿Puedes ayudarme? Gracias!!
Tengo el mismo problema:
plt.xticks(range(2), labels), me dice algo de este estilo –> name ‘LABELS’ is not defined
Yo le saqué la línea esa para poder avanzar
Hola,
Una pregunta: ¿todo esto es válido también para clasificación no binaria?
Muchas gracias
Saludos
Tengo una duda, en una ocación estaba usando RNA para la prediccion de una propiedad en un registros Geofisico,,, Tenia muchos datos de registros Geofisicos (como 5000) y como 20 datos que eran tomados de muestras de laboratorio.. Al correr mi RNA ajustaba bien a los datos del registro pero jamas ajusto a los datos de los nucleos. Podria aplicarse algun metodo que usaste para clasificació binaria pero a datos minoritarios pero que sean numericos cualquiera 2.334, 7.432,2.4 etc…
Hola Manuel, si, claro, pueden aplicarse usando esa misma librería.
Saludos!
Excelente explicación, solo me queda la duda si la matriz de confusión se puede utilizar para categorías, como en tú ejemplo de múltiples categorías (coche, barco, avión).
Saludos
Hola Cristian, si, si se puede usar una matriz de confusión con muchas categorías y queda muy bonita jaja! me refiero a que es de mucha utilidad.
Saludos
Falta esto
LABELS= [‘Normal’,’Fraudulent’]
En el artículo no aparece, pero en la notebook de Github si!.
Gracias, saludos
Hola a todos! En este ejemplo, cada vez que escribia “ratio” me devolvia lo siguiente:
TypeError: init() got an unexpected keyword argument ‘ratio’
En el ejemplo de RandomOverSampler y SMOTETomek lo resolvi sustituyendo “ratio” por “sampling_strategy”.
https://stackoverflow.com/questions/62225793/typeerror-init-got-an-unexpected-keyword-argument-ratio-when-using-smot
En cambio, con el caso de NearMiss no me funciona, ¿alguna idea?
PD: Muchas gracias por los artículos!!! me están ayudando mucho a aprender y adentrarme en este mundo tan apasionante!! 🙂
Buenos dias
Una pregunta, si mi red de clasificacion es de dos clases, por poner ejemplos analizar el estado de un cable, “roto” y “no roto”, y lo entreno con muchos ejemplos, pero luego le presento una categoria completamente diferente a un cable, por ejemplo un coche, y me interesa funcionalmente que al no pertenecer a “roto” me lo etiquete como “no roto”. ¿que estrategia se puede seguir? ¿como puedo favorecer que lo que no esté muy claro que sea un “roto” me lo clasifique como “no roto” ?
Muchas gracias.
Hola, podrías utilizar la función predict_proba() -en vez de predict- y verás la probabilidad de que sea roto y no roto. Si vez que el valor está muy cerca del límite entre ambos (por ejemplo entre ser 0.45 y 0.65) podrías clasificarlo siempre como “no roto”.
Saludos!
Hola, presentó este error: AttributeError: ‘RandomOverSampler’ object has no attribute ‘fit_sample’
cambie fit_sample() por fit_resample(). Corrió.
Hola,
Antes de nada, quiero dar las gracias por este post. Me ha servido de gran ayuda.
Cuando cargo el último modelo en un archivo pickle, al ejecutarlo sobre un nuevo dataset, todos las predicciones me salen igual a 1, cosa que no es así es el resto de estrategias.
¿Podríais darme un poco de luz, por favor?
Un saludo,