NLP: Analizamos los cuentos de Hernan Casciari
Ejercicio Python de Procesamiento del Lenguaje Natural
( ó “¿Qué tiene Casciari en la cabeza?” )

Luego de haber escrito sobre la teoría de iniciación al NLP en el artículo anterior llega la hora de hacer algunos ejercicios prácticos en código Python para adentrarnos en este mundo.
Como la idea es hacer Aprendizaje Automático en Español, se me ocurrió buscar textos en castellano y recordé a Hernan Casciari que tiene los cuentos de su blog disponibles online y me pareció un buen desafío.
Para quien no conozca a Hernan Casciari, es un escritor genial, hace cuentos muy entretenidos, de humor (y drama) muy reales, relacionados con su vida, infancia, relaciones familiares con toques de ficción. Vivió en España durante más de una década y tuvo allí a su primera hija. En 2005 fue premiado como “El mejor blog del mundo” por Deutsche Welle de Alemania. En 2008 Antonio Gasalla tomó su obra “Más respeto que soy tu madre” y la llevó al teatro con muchísimo éxito. Escribió columnas para importantes periódicos de España y Argentina hasta que fundó su propia editorial Orsai en 2010 donde no depende de terceros para comercializar ni distribuir sus productos y siempre ofrece versione en pdf (gratuitos). Tiene 7 libros publicados, apariciones en radio (Vorterix y Perros de la Calle) y hasta llevó sus historias a una genial puesta en escena llamada “Obra en Construcción” que giró por muchas provincias de la Argentina, España y Uruguay.
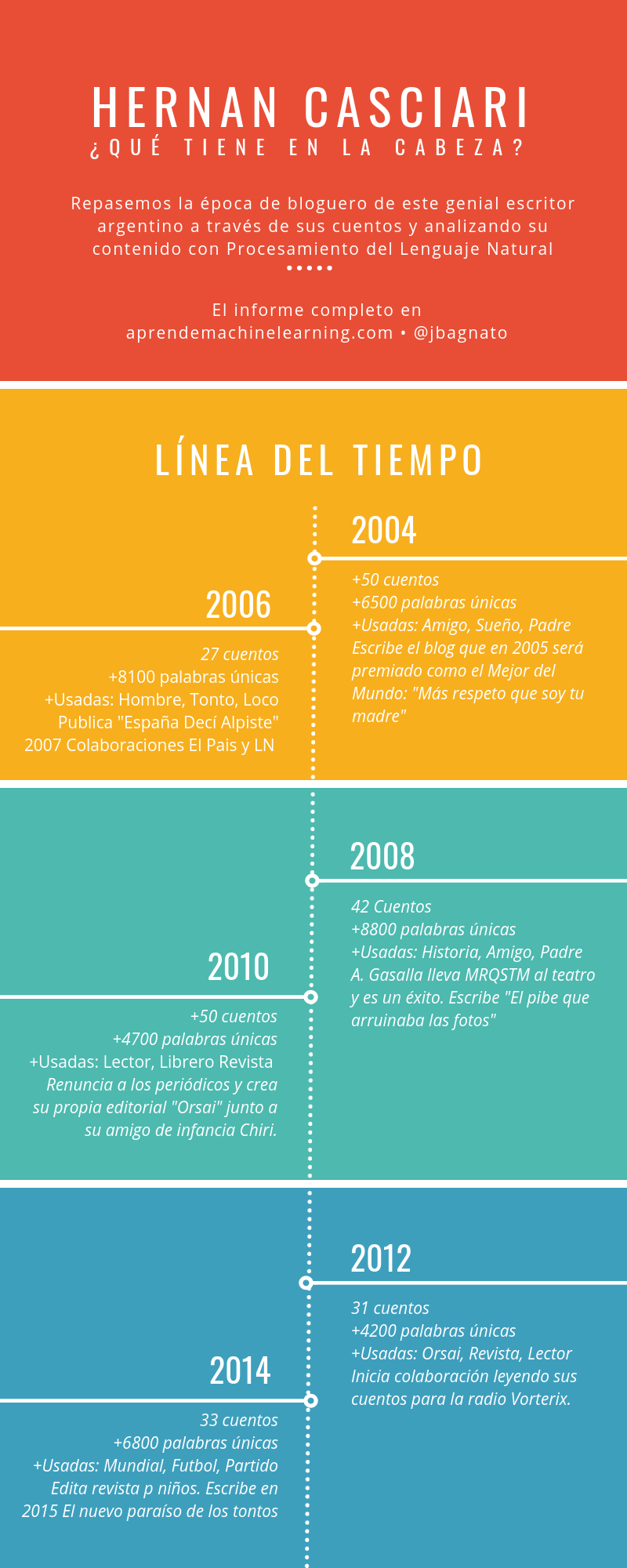
Agenda del Día: “NLP tradicional”
Lo cierto es que utilizaremos la librería python NLTK para NLP y haremos uso de varias funciones y análisis tradicionales, me refiero a que sin meternos – aún- en Deep Learning (eso lo dejaremos para otro futuro artículo).
- Obtener los Datos (los cuentos)
- Exploración Inicial
- Limpieza de datos
- Análisis Exploratorio
- Análisis de Sentimiento
- Modelado de Tópicos
Vamos al código!
Seguir Leyendo