¿Cómo funcionan las Convolutional Neural Networks? Visión por Ordenador
En este artículo intentaré explicar la teoría relativa a las Redes Neuronales Convolucionales (en inglés CNN) que son el algoritmo utilizado en Aprendizaje Automático para dar la capacidad de “ver” al ordenador. Gracias a esto, desde apenas 1998, podemos clasificar imágenes, detectar diversos tipos de tumores automáticamente, enseñar a conducir a los coches autónomos y un sinfín de otras aplicaciones.

El tema es bastante complejo/complicado e intentaré explicarlo lo más claro posible. En este artículo doy por sentado que tienes conocimientos básicos de cómo funciona una red neuronal artificial multicapa feedforward (fully connected). Si no es así te recomiendo que antes leas sobre ello:
- Historia de las Redes Neuronales, desde el principio hasta 2018
- Breve introducción al DeepLearning con Redes Neuronales
- Crea una sencilla Red Neuronal en Python con Keras y Tensorflow
- Crea una Red Neuronal desde Cero (sin Keras!)
¿Qúe es una CNN? ¿Cómo puede ver una red neuronal? ¿Cómo clasifica imagenes y distingue un perro de un gato?
La CNN es un tipo de Red Neuronal Artificial con aprendizaje supervisado que procesa sus capas imitando al cortex visual del ojo humano para identificar distintas características en las entradas que en definitiva hacen que pueda identificar objetos y “ver”. Para ello, la CNN contiene varias capas ocultas especializadas y con una jerarquía: esto quiere decir que las primeras capas pueden detectar lineas, curvas y se van especializando hasta llegar a capas más profundas que reconocen formas complejas como un rostro o la silueta de un animal.
Necesitaremos…
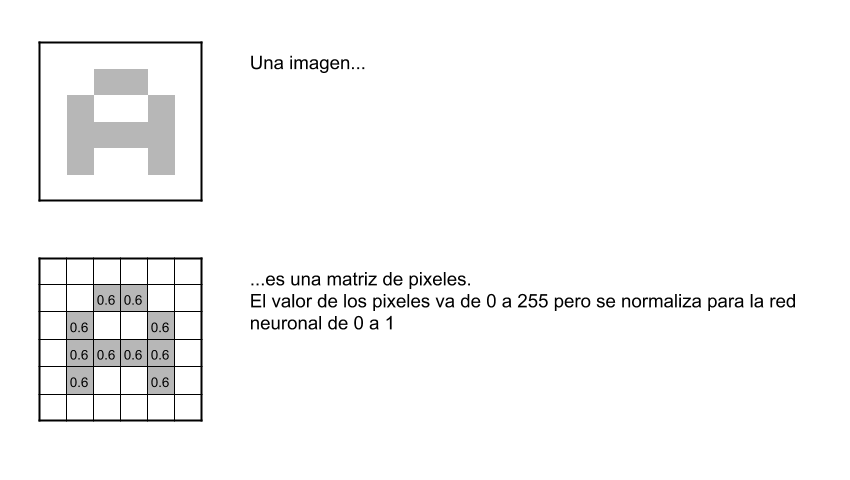
Recodemos que la red neuronal deberá aprender por sí sola a reconocer una diversidad de objetos dentro de imágenes y para ello necesitaremos una gran cantidad de imágenes -lease más de 10.000 imágenes de gatos, otras 10.000 de perros,…- para que la red pueda captar sus características únicas -de cada objeto- y a su vez, poder generalizarlo -esto es que pueda reconocer como gato tanto a un felino negro, uno blanco, un gato de frente, un gato de perfil, gato saltando, etc.-