¿Cómo funcionan los Transformers? en Español
Los Transformers aparecieron como una novedosa arquitectura de Deep Learning para NLP en un paper de 2017 “Attention is all you need” que presentaba unos ingeniosos métodos para poder realizar traducción de un idioma a otro superando a las redes seq-2-seq LSTM de aquel entonces. Pero lo que no sabíamos es que este “nuevo modelo” podría ser utilizado en más campos como el de Visión Artificial, Redes Generativas, Aprendizaje por Refuerzo, Time Series y en todos ellos batir todos los records! Su impacto es tan grande que se han transformado en la nueva piedra angular del Machine Learning.
En este artículo repasaremos las piezas fundamentales que componen al Transformer y cómo una a una colaboran para conseguir tan buenos resultados. Los Transformers y su mecanismo de atención posibilitaron la aparición de los grandes modelos generadores de texto GPT2, GPT3 y BERT que ahora podían ser entrenados aprovechando el paralelismo que se alcanza mediante el uso de GPUs.
Agenda
- ¿Qué son los transformers?
- Arquitectura
- General
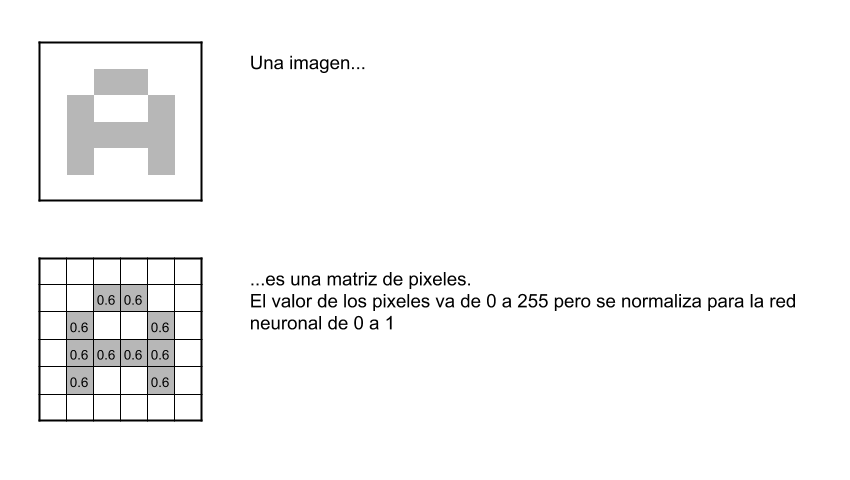
- Embeddings
- Positional Encoding
- Encoder
- Mecanismo de Atención
- Add & Normalisation Layer
- Feedforward Network
- Decoder
- Salida del Modelo
- Aplicaciones de los Transformers
- BERT
- GPT-2
- GPT-3
- Resumen
¿Qué son los transformers en Machine Learning?
En el paper original de 2017 “Attention is all you need” aparece el diagrama con la novedosa arquitectura del Transformer, que todos deberíamos tatuarnos en un brazo. Esta arquitectura surge como una solución a problemas de aprendizaje supervisado en Procesamiento del Lenguaje Natural, obteniendo grandes ventajas frente a los modelos utilizados en ese entonces. El transformer permitía realizar la traducción de un idioma a otro con la gran ventaja de poder entrenar al modelo en paralelo; lo que aumentaba drásticamente la velocidad y reducción del coste; y utilizando como potenciador el mecanismo de atención, que hasta ese momento no había sido explotado del todo. Veremos que en su arquitectura utiliza diversas piezas ya existentes pero que no estaban combinadas de esta manera. Además el nombre de “Todo lo que necesitas es Atención” es a la vez un tributo a los Beatles y una “bofetada” a los modelos NLP centrados en Redes Recurrentes que en ese entonces estaban intentando combinarlos con atención. De esta sutil forma les estaban diciendo… “tiren esas redes recurrentes a la basura”, porque el mecanismo de atención NO es un complemento… es EL protagonista!
Seguir LeyendoAll you need is
The BeatlesLoveAttention

 4150 €
4150 € Becas hasta el 40%
Becas hasta el 40% Financiación sin intereses
Financiación sin intereses