La interpretación de las decisiones tomadas por nuestros algoritmos de Machine Learning pasa a un plano muy importante: para comprender el modelo y mejorarlo, evitar “biases” (ó descubrirlos), para justificar nuestra confianza en el modelo y hasta legalmente pues es requerido por leyes como la GDPR -para decisiones delicadas como puede ser dar ó no un crédito a una persona-.
Si nuestro algoritmo tuviera que detectar enfermedades y suponiendo que logramos una tasa de aciertos del 90% ¿no te parecería lógico comprender cómo lo ha hecho? ¿es puro azar? ¿está teniendo en cuenta combinaciones de características que nosotros no contemplamos?
Si de pequeño eras curioso y querías sabes cómo funcionaban las cosas: relojes, autos, ó hasta el mismísimo ordenador… serás un poco como yo… y… no siempre nos convence el concepto de “caja negra”.
Si vas por el buen camino hacia el aprendizaje del Machine Learning, la inteligencia artificial y la ciencia de datos, seguramente te hayas topado con trabas y obstáculos frecuentes. En este artículo repasaremos 12 útiles consejos para tener en cuenta a la hora de trabajar con los modelos del Aprendizaje Automático. Estos postulados surgen del paper “A Few Useful Things to Know about Machine Learning“ escrito en 2012 por Pedro Domingos.
Con el objetivo de ilustrar mejor estos consejos, nos centraremos en la aplicación del Machine Learning de Clasificar, pero esto podría servir para otros usos.
Los 3 componentes del Aprendizaje Automático
Supongamos que tienes un problema al que crees que puedes aplicar ML. ¿Qué modelo usar? Deberá ser una combinación de estos 3 componentes: Representación, evaluación y optimización.
Representación: Un clasificador deberá poder ser representado en un lenguaje formal que entienda el ordenador. Deberemos elegir entre los diversos algoritmos que sirven para resolver el problema. A este conjunto de “clasificadores aptos” se les llamará “espacio de hipótesis del aprendiz”. Ej: SVM, Regresión Logística, K-nearest neighbor, árboles de decisión, Redes Neuronales, etc.
Evaluación: Se necesitará una función de evaluación para distinguir entre un buen clasificador ó uno malo. También es llamada función objetivo ó scoring function. Ejemplos son accuracy, likelihood, information gain, etc.
Optimización: necesitamos un método de búsqueda entre los clasificadores para mejorar el resultado de la Evaluación. Su elección será clave. EJ: Descenso por gradiente, mínimos cuadrados, etc.
Mejora del modelo de Series Temporales con Múltiples Variables y Embeddings
Este artículo es la continuación del post anterior “Pronóstico de Series Temporales con Redes Neuronales en Python” en donde vimos cómo a partir de un archivo de entrada con las unidades vendidas por una empresa durante años anteriores, podíamos estimar las ventas de la próxima semana. Continuaremos a partir de ese modelo -por lo que te recomiendo leer antes de continuar- y haremos propuestas para mejorar la predicción.
Breve Repaso de lo que hicimos
En el modelo del capitulo anterior creamos una Red Neuronal MLP (Multilayered Perceptron) feedforward de pocas capas, y el mayor trabajo que hicimos fue en los datos de entrada. Puesto que sólo tenemos un archivo csv con 2 columnas: fecha y unidades vendidas lo que hicimos fue transformar esa entrada en un “problema de aprendizaje supervisado“. Para ello, creamos un “nuevo archivo” de entrada con 7 columnas en donde poníamos la cantidad de unidades vendidas en los 7 días anteriores y de salida la cantidad de unidades vendidas en “la fecha actual”. De esa manera alimentamos la red y ésta fue capaz de realizar pronósticos aceptables. Sólo utilizamos la columna de unidades. Pero no utilizamos la columna de fecha. ¿Podría ser la columna de fecha un dato importante? ¿podría mejorar nuestra predicción de ventas?
Mejoras al modelo de Series Temporales
Esto es lo que haremos hoy: propongo 2 nuevos modelos con Redes Neuronales Feedforward para intentar mejorar los pronósticos de ventas:
Un primer modelo tomando la fecha como nueva variable de entrada valiosa y que aporta datos.
Un segundo modelo también usando la fecha como variable adicional, pero utilizándola con Embeddings… y a ver si mejora el pronóstico.
Por lo tanto explicaremos lo qué son los embeddings utilizados en variables categóricas (se utiliza mucho en problemas de Procesamiento del Lenguaje Natural NLP para modelar).
En el artículo de hoy veremos qué son las series temporales y cómo predecir su comportamiento utilizando redes neuronales con Keras y Tensorflow. Repasaremos el código completo en Python y la descarga del archivo csv del ejercicio propuesto con los datos de entrada.
¿Qué es una serie temporal y qué tiene de especial?
Una serie temporal es un conjunto de muestras tomadas a intervalos de tiempo regulares. Es interesante analizar su comportamiento al mediano y largo plazo, intentando detectar patrones y poder hacer pronósticos de cómo será su comportamiento futuro. Lo que hace <<especial>> a una Time Series a diferencia de un “problema” de Regresión son dos cosas:
Es dependiente del Tiempo. Esto rompe con el requerimiento que tiene la regresión lineal de que sus observaciones sean independientes.
Suelen tener algún tipo de estacionalidad, ó de tendencias a crecer ó decrecer. Pensemos en cuánto más producto vende una heladería en sólo 4 meses al año que en el resto de estaciones.
Ejemplo de series temporales son:
Capturar la temperatura, humedad y presión de una zona a intervalos de 15 minutos.
Valor de las acciones de una empresa en la bolsa minuto a minuto.
Ventas diarias (ó mensuales) de una empresa.
Producción en Kg de una cosecha cada semestre.
Creo que con eso ya se dan una idea 🙂 Como también pueden entrever, las series temporales pueden ser de 1 sóla variable, ó de múltiples.
Vamos a comenzar con la práctica, cargando un dataset que contiene información de casi 2 años de ventas diarias de productos. Los campos que contiene son fecha y la cantidad de unidades vendidas.
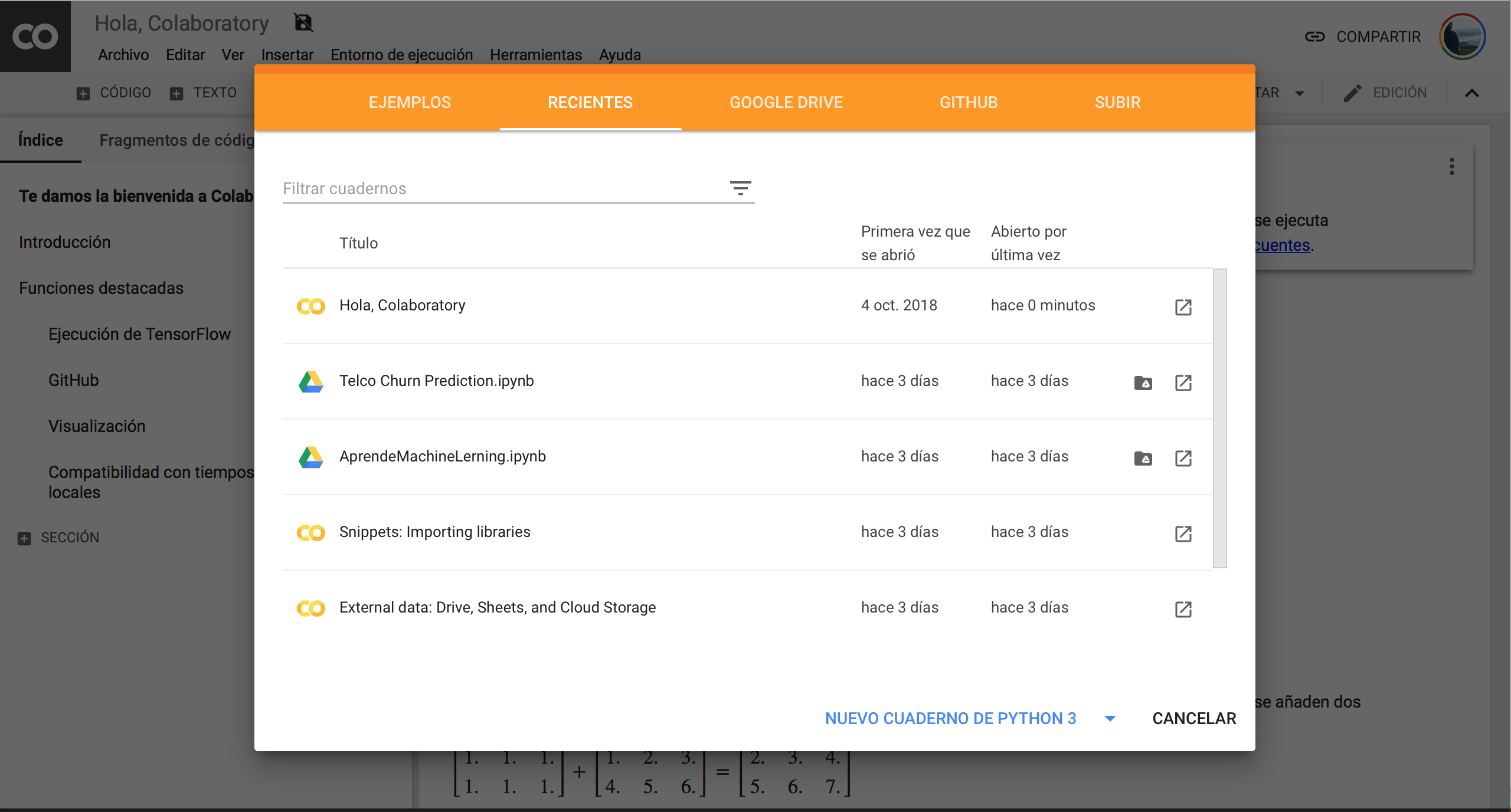
Por increíble que parezca, ahora mismo tenemos disponible una cuenta gratuita para programar nuestros modelos de Machine Learning en la nube, con Python, Jupyter Notebooks de manera remota y hasta con GPU para poder aumentar nuestro poder de procesamiento…. gratis! sí sí… esto no es un “cuento del tío” ni tiene ninguna trampa!… Descubre cómo aprovecharlo en este artículo!
Machine Learning desde el Navegador
Primero lo primero. ¿Porqué voy a querer tener mi código en la nube? Pues bien, lo normal (¿ideal?) es que tengamos un entorno de desarrollo local en nuestro propio ordenador, un entorno de pruebas en algún servidor, staging y producción. Pero… ¿qué pasa si aún no tenemos instalado el ambiente?, o tenemos conflictos con algún archivo/librería, versión de Python… ó por lo que sea no tenemos espacio en disco… ó hasta si nos va muy lento y no disponemos en -el corto plazo- de mayor procesador/ram? O hasta por simple comodidad, está siempre bien tener a mano una web online, “siempre lista” en donde ya esté prácticamente todo el software que necesitamos instalado. Y ese servicio lo da Google, entre otras opciones. Lo interesante es que Google Colab ofrece varias ventajas frente a sus competidores.
interesante es que Google Colab ofrece varias ventajas frente a sus competidores.
La GPU…. ¿en casa o en la nube?
¿Una GPU? ¿para que quiero eso si ya tengo como 8 núcleos? La realidad es que para el procesamiento de algoritmos de Aprendizaje Automático (y para videojuegos, ejem!) la GPU resulta mucho más potente en realizar cálculos (también en paralelo) por ejemplo las multiplicaciones matriciales… esas que HACEMOS TOooooDO el tiempo al ENTRENAR nuestros modelos!!! para hacer el descenso por gradiente ó Toooodo el rato con el Backpropagation de nuestras redes neuronales… Esto supone una mejora de hasta 10x en velocidad de procesado… Algoritmos que antes tomaban días y ahora se resuelven en horas. Un avance enorme.
Si tienes una tarjeta Nvidia con GPU ya instalada, felicidades ya tienes el poder! Si no la tienes y no vas a invertir unos cuántos dólares en comprarla, puedes tener toda(*) su potencia desde la nube!
(*)NOTA: Google se reserva el poder limitar el uso de GPU si considera que estás abusando ó utilizando en demasía ese recurso ó para fines indebidos (por ej. minería de bitcoins)
En este artículo aprenderemos a utilizar la librería BeatifulSoap de Python para obtener contenidos de páginas webs de manera automática.
En internet encontramos de todo: artículos, noticias, estadísticas e información útil (¿e inútil?), pero ¿cómo la extraemos? No siempre se encuentra en forma de descarga ó puede haber información repartida en multiples dominios, ó puede que necesitemos información histórica, de webs que cambian con el tiempo.
Para poder generar nuestros propios archivos con los datos que nos interesan y de manera automática es que utilizaremos la técnica de WebScraping.
Contenidos:
Requerimientos para WebScraping
Lo básico de HTML y CSS que debes saber
Inspeccionar manualmente una página web
Al código! Obtener el valor actual del IBEX35® de la Bolsa de Madrid