Introducción a los LLM, en Inglés Large Language Model, que revolucionaron el campo del Procesamiento del Lenguaje Natural (NLP) crearon tendencia gracias a ChatGPT e incluso pusieron en cuestión la posibilidad de alcanzar el AGI, el punto de quiebre en el que la Inteligencia Artificial se vuelve autónoma y más poderosa que la inteligencia humana.
En este artículo vamos a comentar cómo surgen las LLMs, el cambio de paradigma, sus modelos actuales y cómo disrumpe en prácticamente todas las áreas laborales.
Definición de LLM
Los Grandes Modelos de Lenguaje son modelos de propósito general de Inteligencia Artificial desarrollados dentro del campo del Procesamiento del Lenguaje Natural que puede entender y generar texto al estilo humano.
Un LLM es un modelo estadístico que determina la probabilidad de ocurrencia de una secuencia de palabras en una oración.
Los modelos más famosos actuales “GPT” tienen una arquitectura basada en Transformers (2017) y usan redes neuronales que son entrenadas con inmensas cantidades de texto obtenidos y “curados” de internet, incluyendo libros, periódicos, foros, recetas, legales, paper científicos, patentes, enciclopedias.
Para darnos una idea de la inmensa cantidad de información que utiliza GPT-3, es el equivalente a que una persona leyera 120 palabras por minuto las 24 horas del día sin parar durante 9 mil años.
En artículos anteriores, hablamos sobre la clasificación de imágenes y sobre cómo hacer detección de objetos en tiempo real gracias a Yolo. Esta vez hablaremos sobre “Seguimiento de objetos” (Object Tracking en inglés) en donde sumamos una nueva “capa” de inteligencia dentro del campo de Visión Artificial.
La Problemática del rastreo de objetos
Imaginemos que tenemos un cámara de seguridad en donde aplicamos un modelo de Machine Learning como Yolo que detecta coches en tiempo real. Agregamos un “rectángulo rojo” (ó caja) sobre cada automóvil que se mueve. Bien. Queremos contabilizar cuántos de esos vehículos aparecen en pantalla durante una hora; ¿cómo hacemos?. Hasta ahora, sabemos los coches que hay en cada frame del video. En el primer fotograma hemos detectado 3 coches. En el segundo cuadro tenemos 3 coches. ¿Son los mismos ó son coches distintos? ¿Qué ocurre cuando en el siguiente fotograma aparece un cuarto coche? ¿Cuántos coches sumamos? 3 + 3 + 4 ? Tendremos un mal recuento en el transcurso de una hora, si no aplicamos un algoritmo adecuado para el rastreo de vehículos.
Espero que con ese ejemplo empieces a comprender la problemática que se nos plantea al querer hacer object tracking. Pero no es sólo eso, además de poder identificar cada objeto en un cuadro y mantener su identidad a lo largo del tiempo, aparecen otros problemas “clásicos”: la oclusión del objeto la superposición y la transformación.
Oclusión: cuando un objeto que estamos rastreando queda oculto momentáneamente o parcialmente por quedar detrás de una columna, farola ú otro objeto.
Superposición de objetos: ocurre cuando tenemos a dos jugadores de fútbol con camiseta blanca y uno pasa por detrás de otro, entonces el algoritmo podría ser incapaz de entender cuál es cada uno.
Transformación del objeto: tenemos identificada a una persona que camina de frente con una camiseta roja y luego cambia de rumbo y su camiseta por detrás es azul. Es la misma persona pero que en el transcurso de su recorrido va cambiando sus “features”.
Efectos visuales: ocurre cuando al cristal de un coche le da el sol y genera un destello, lo cual dificulta su identificación. O podría ser que pase de una zona soleada a una con sombra generando una variación en sus colores.
Imagen creada por el Autor utilizando el modelo de text-to-img StableDiffusion
Los Transformers aparecieron como una novedosa arquitectura de Deep Learning para NLP en un paper de 2017 “Attention is all you need” que presentaba unos ingeniosos métodos para poder realizar traducción de un idioma a otro superando a las redes seq-2-seq LSTM de aquel entonces. Pero lo que no sabíamos es que este “nuevo modelo” podría ser utilizado en más campos como el de Visión Artificial, Redes Generativas, Aprendizaje por Refuerzo, Time Series y en todos ellos batir todos los records! Su impacto es tan grande que se han transformado en la nueva piedra angular del Machine Learning.
En este artículo repasaremos las piezas fundamentales que componen al Transformer y cómo una a una colaboran para conseguir tan buenos resultados. Los Transformers y su mecanismo de atención posibilitaron la aparición de los grandes modelos generadores de texto GPT2, GPT3 y BERT que ahora podían ser entrenados aprovechando el paralelismo que se alcanza mediante el uso de GPUs.
Agenda
¿Qué son los transformers?
Arquitectura
General
Embeddings
Positional Encoding
Encoder
Mecanismo de Atención
Add & Normalisation Layer
Feedforward Network
Decoder
Salida del Modelo
Aplicaciones de los Transformers
BERT
GPT-2
GPT-3
Resumen
¿Qué son los transformers en Machine Learning?
En el paper original de 2017 “Attention is all you need” aparece el diagrama con la novedosa arquitectura del Transformer, que todos deberíamos tatuarnos en un brazo. Esta arquitectura surge como una solución a problemas de aprendizaje supervisado en Procesamiento del Lenguaje Natural, obteniendo grandes ventajas frente a los modelos utilizados en ese entonces. El transformer permitía realizar la traducción de un idioma a otro con la gran ventaja de poder entrenar al modelo en paralelo; lo que aumentaba drásticamente la velocidad y reducción del coste; y utilizando como potenciador el mecanismo de atención, que hasta ese momento no había sido explotado del todo. Veremos que en su arquitectura utiliza diversas piezas ya existentes pero que no estaban combinadas de esta manera. Además el nombre de “Todo lo que necesitas es Atención” es a la vez un tributo a los Beatles y una “bofetada” a los modelos NLP centrados en Redes Recurrentes que en ese entonces estaban intentando combinarlos con atención. De esta sutil forma les estaban diciendo… “tiren esas redes recurrentes a la basura”, porque el mecanismo de atención NO es un complemento… es EL protagonista!
El modelo de Machine Learning llamado Stable Diffusion es Open Source y permite generar cualquier imagen a partir de un texto, por más loca que sea, desde el sofá de tu casa!
Estamos viviendo unos días realmente emocionantes en el campo de la inteligencia artificial, en apenas meses, hemos pasado de tener modelos enormes y de pago en manos de unas pocas corporaciones a poder desplegar un modelo en tu propio ordenador y lograr los mismos -increíbles- resultados de manera gratuita. Es decir, ahora mismo, está al alcance de prácticamente cualquier persona la capacidad de utilizar esta potentísima herramienta y crear imágenes en segundos (ó minutos) y a coste cero.
En este artículo les comentaré qué es Stable Diffusion y por qué es un hito en la historia de la Inteligencia Artificial, veremos cómo funciona y tienes la oportunidad de probarlo en la nube o de instalarlo en tu propio ordenador sea Windows, Linux ó Mac, con o sin placa GPU.
Reseña de los acontecimientos
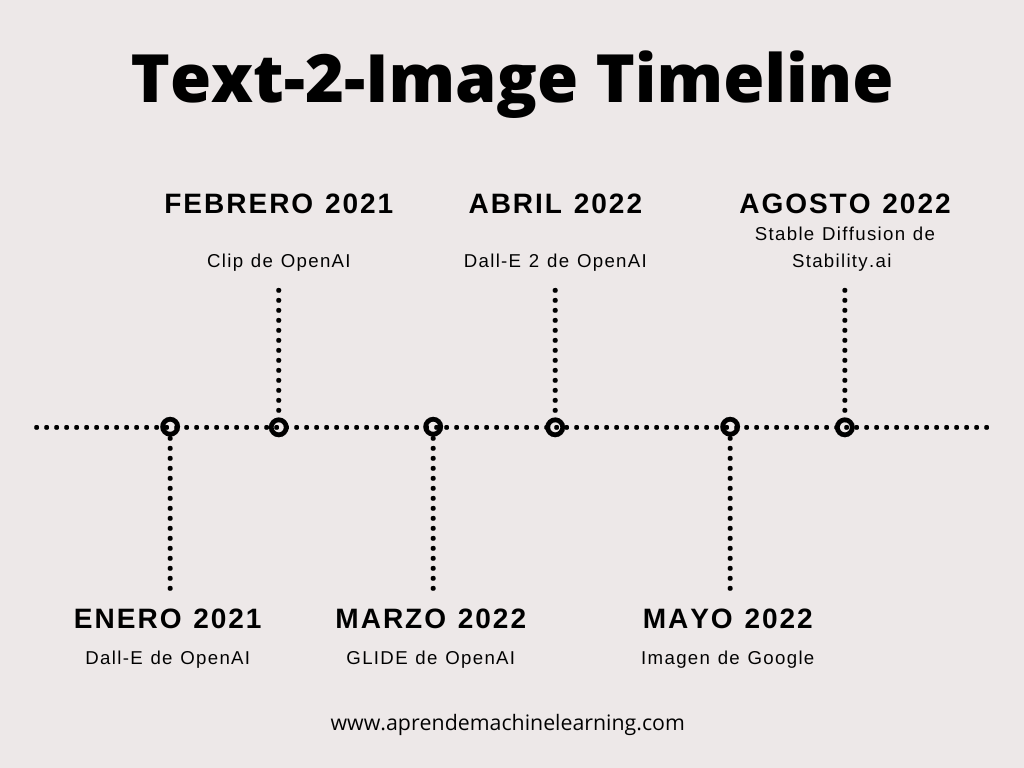
2015: Paper que propone los Diffusion Models.
2018 -2019 Text to Image Synthesis – usando GANS se generan imágenes de 64×64 pixels, utiliza muchos recursos y baja calidad de resultados.
Enero 2021: Open AI anuncia Dall-E, genera imágenes interesantes, pequeñas, baja resolución, lentas.
Febrero 2021: CLIP de Open AI (Contrastive Language-Image Pretraining), un codificador dual de lenguaje-imagen muy potente.
Julio 2021: Image Text Contrastive Learning Mejora sobre las Gans “image-text-label” space.
Marzo 2022: GLIDE: esta red es una mejora sobre Dall-E, tambien de openAI pero usando DIFFUSION model.
Abril 2022: Dall-E 2 de Open AI, un modelo muy bueno de generación de imágenes. Código cerrado, acceso por pedido y de pago.
Agosto de 2022: Lanzamiento de Stable Diffusion 1.4 de Stability AI al público. Open Source, de bajos recursos, para poder ejecutar en cualquier ordenador.
Stable Diffusion es también una gran revolución en nuestra sociedad porque trae consigo diversas polémicas; al ofrecer esta herramienta a un amplio público, permite generar imágenes de fantasía de paisajes, personas, productos… ¿cómo afecta esto a los derechos de autor? Qué pasa con las imágenes inadecuadas u ofensivas? Qué pasa con el sesgo de género? Puede suplantar a un diseñador gráfico? Hay un abanico enorme de incógnitas sobre cómo será utilizada esta herramienta y la disrupción que supone. A mí personalmente me impresiona por el progreso tecnológico, por lo potente que es, los magnificos resultados que puede alcanzar y todo lo positivo que puede acarrear.
¿Por qué tanto revuelo? ¿Es como una gran Base de datos de imágenes? – ¡No!
Es cierto que fue entrenada con más de 5 mil millones de imágenes. Entonces podemos pensar: “Si el modelo vio 100.000 imágenes de caballos, aprenderá a dibujar caballos. Si vio 100.000 imágenes de la luna, sabrá pintar la luna. Y si aprendió de miles de imágenes de astronautas, sabrá pintar astronautas“. Pero si le pedimos que pinte “un astronauta a caballo en la luna” ¿qué pasa? La respuesta es que el modelo que jamás había visto una imagen así, es capaz de generar cientos de variantes de imágenes que cumplen con lo solicitado… esto ya empieza a ser increíble. Podemos pensar: “Bueno, estará haciendo un collage, usando un caballo que ya vio, un astronauta (que ya vió) y la luna y hacer una composición“. Y no; no es eso lo que hace, ahí se vuelve interesante: el modelo de ML parte de un “lienzo en blanco” (en realidad es una imagen llena de ruido) y a partir de ellos empieza a generar la imagen, iterando y refinando su objetivo, pero trabajando a nivel de pixel (por lo cual no está haciendo copy-paste). Si creyéramos que es una gran base de datos, les aseguro que no caben las 5.500.000.000 de imágenes en 4 Gygabytes -que son los pesos del modelo de la red- pues estaría almacenando cada imagen (de 512x512px) en menos de 1 Byte, algo imposible.
En este artículo aprenderemos qué es el aprendizaje por refuerzo, lo más novedoso y ambicioso a día de hoy en Inteligencia artificial, veremos cómo funciona, sus casos de uso y haremos un ejercicio práctico completo en Python: una máquina que aprenderá a jugar al pong sóla, sin conocer las reglas ni al entorno.
En este artículo intentaré comentar los seis perfiles más frecuentes solicitados por la industria en la actualidad, sus diversos roles. El artículo esta fuertemente basado en el reporte 2020 de Workera.
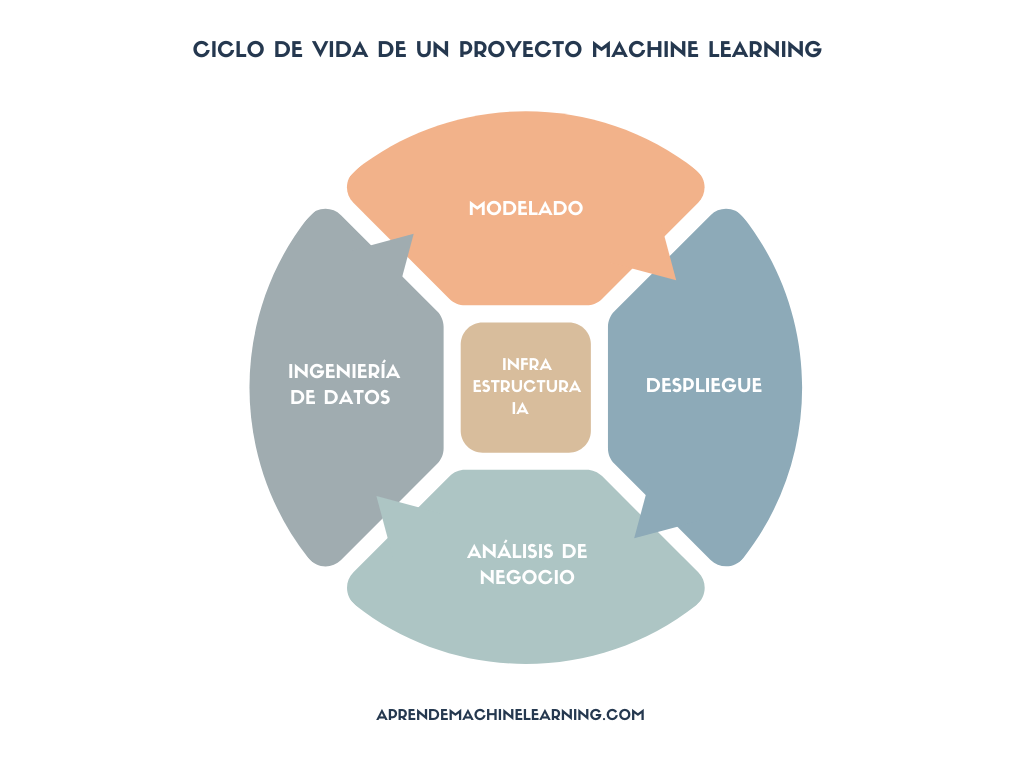
El proyecto de ML
Primero definamos en grandes rasgos las diversas etapas que conforman el desarrollo de un proyecto de Machine Learning.